
호기심 많은 분석가
[BoostCamp] Week2_Day8. 피어세션 때 발표를 하다. 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개요
피어세션 때 각자 발표를 함으로써 설명하는 힘도 기르고, 모르는 부분에 대해서 조금 더 짚어가며 피어세션의 밀도를 채워갔다. 설명을 하기 위해 조금 더 열심히 찾아보고 이해하려 노력했고, 꽤 도움이 됐다. 그런데 오늘의 강의 양이 많아서 시간이 조금 부족했다. 특강도 많고 더 빠르게 학습해야겠다.
개인 학습
(04강) Convolution은 무엇인가?
CNN(Convolution Neural Network)에서 가장 중요한 연산은 Convolution이다.
그래서 CNN을 공부하기 전에 Convolution의 정의, 연산 방법과 기능에 대해 먼저 배운다.
Convolution
- Convolution은 CNN에서 처음 나온 것은 아니고, 두 개의 함수를 잘 섞어주는 operator로 정의되었다.
- 우리가 주로 맞이하게 될 2D image convolution은 연산은 아래의 형태와 같고, I는 전체 이미지 공간, K가 우리가 적용하고 싶은 filter, 3x3 or 5x5를 의미한다.
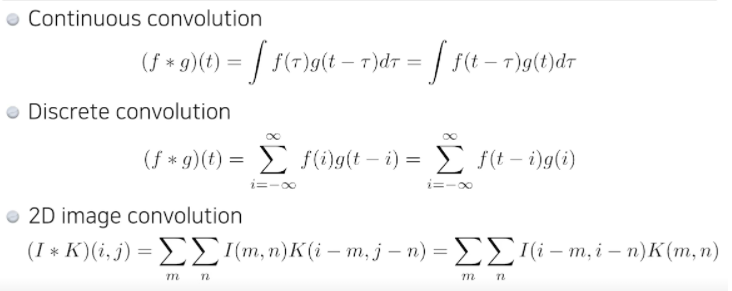
- Zero Padding이나 Stride를 고려하지 않고 기본적인 Convolution만 했을 때 3x3 filter에 7x7 image를 씌워주게 되면 5x5의 output이 출력된다.
- Zero Padding : Input image size를 유지시켜주기 위해 사용, Edge 성분도 충분히 사용 가능
- Stride : 원래는 한 칸씩 띄면서 곱했는데, 이동할 간격을 조절하는 것. 출력 데이터의 크기를 조절하기 위해

- 하나의 아웃풋 값은 적용하고자 하는 image에 filter를 찍는다고 생각하면 됨 - Like 도장
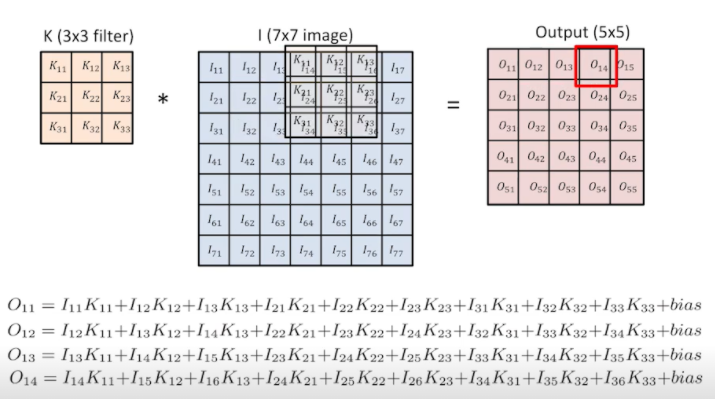
- 그렇다면 Convolution한다는 것은 어떤 의미가 있을까?
- 적용하고자 하는 filter에 대해 같은 image에 대해서 convolution output이 달라진다.

RGB Image Convolution
- 일반적으로 RGB 이미지를 다루고, RGB 이미지를 수학적으로 다루면 tensor로 표현됨(RGB는 3차원이므로)
- 32x32 이미지가 있고 depth 방향으로 3채널(R,G,B)가 들어가 있다.
- 32x32x3 이미지에 5x5 filter(kernel)를 적용하더라도 filter의 채널도 똑같이 3이라는 것이 숨겨져 있음 → 28x28x1의 output

- 일반적인 Convonlution을 생각하면 이미지가 들어가서 여러 개의 채널을 갖는 Convolutional feature map이 나오게 된다. feature map의 채널 숫자는 어떻게 생기게 되는가?
- Convolution filter가 여러 개 있는 것
- 인풋 채널과 아웃풋(Convolutional feature map) 채널을 알면 여기에 적용되는 필터의 크기 역시 알 수 있다.
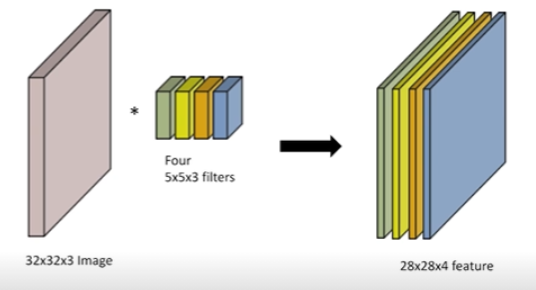
Stack of Convolutions
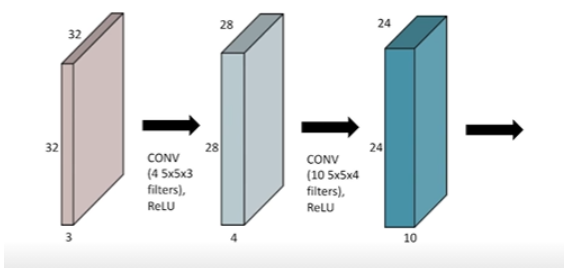
Convolution을 여러 개 할 수도 있다.
- 한번 Convolution 후에는 nonlinear activation이 들어가게 됨
- Convolution이 끝난 matrix 각각의 원소에 ReLU
- 32x32x3 * 5x5x3(4) $\overrightharpoon{ReLU}$ 28x28x4 * 5x5x4(10) $\overrightharpoon{ReLU}$ 24x24x10
- 항상 집중해서 봐야 할 것은 연산에 필요한 parameter의 숫자를 잘 봐야 함
Convolutional Neural Networks
- CNN consists of convolution layer, pooling layer, and fully connected layer
- Convolution and pooling layers : feature extraction
- Fully connected layer : decision making (e.g., classification

- CNN은 위 그림과 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나뉘는데, 특징 추출 영역은 Convolution layer와 Pooling layer를 여러 겹 쌓는 형태로 구성된다.
- Convolution layer : 입력 데이터에 필터 적용하고, 활성화 함수를 반영하는 요소
- Pooling layer : Convolution layer의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용된다.
Ex) Max Pooling, Average Pooling, Min Pooling,...- 학습대상 파라미터가 없고, Pooling layer를 통과하면 행렬의 크기 감소, 채널 수 변경 없음 등의 특징이 있고, CNN에서는 주로 Max Pooling을 사용한다.

- 그 마지막에 다 합쳐서 최종적으로 원하는 값을 만들어주는 fully connected layer가 된다.
- 이전 레이어의 출력을 평탄화하여 다음 스테이지의 입력이 될 수 있는 단일 벡터로 변환, 활성화 함수(Relu, Leaky Relu, tanh)로 뉴런을 활성화, 분류기 함수(softmax)로 분류
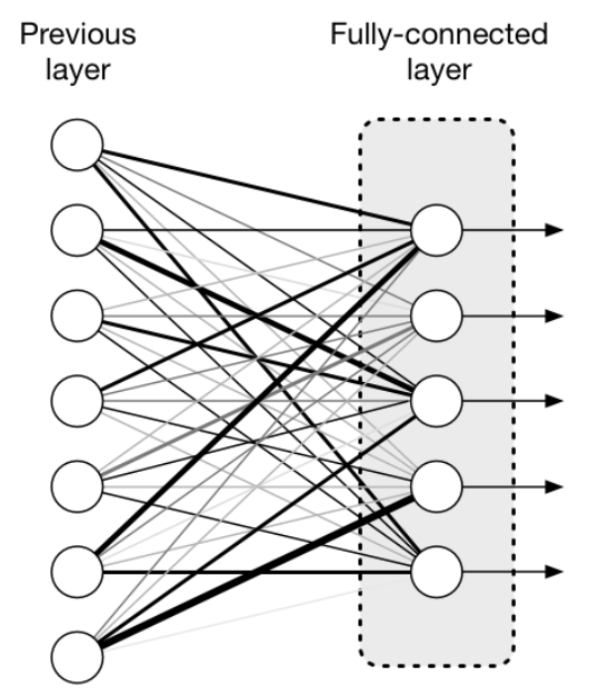
- 이전 레이어의 출력을 평탄화하여 다음 스테이지의 입력이 될 수 있는 단일 벡터로 변환, 활성화 함수(Relu, Leaky Relu, tanh)로 뉴런을 활성화, 분류기 함수(softmax)로 분류
- 이것이 가장 기본적인 CNN인데 최근에 와서는 뒷단의 fully connected layer가 점점 없어지거나 최소화시키는 추세임
- Image가 고해상도가 될 경우 input neuran이 급격하게 증가하게 되어, parameter의 수가 급격히 증가한다. 아래 그림의 경우 input neuran 256개와 1개의 layer에서 100개의 hidden neuran을 사용하게 되면 parameter의 개수는 총 28326개가 된다.
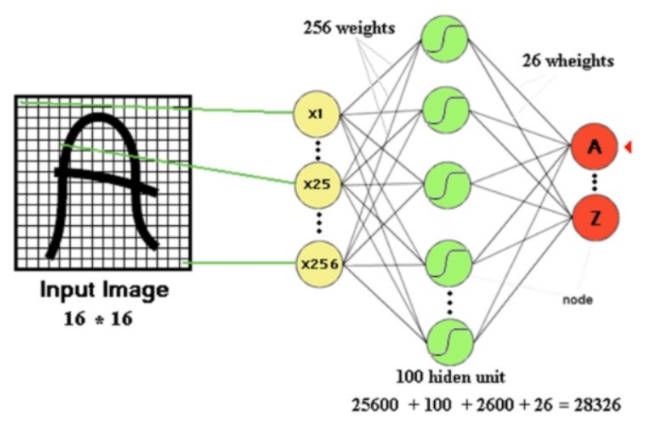
- 왜? 내가 학습시켜야 할 parameter의 숫자가 늘어날수록 학습시키기가 어렵고, generalizatoin performance가 떨어진다고 알려져 있다.
- 그래서 CNN의 목표가 deep 하게 layer는 쌓지만 parameter의 숫자를 줄이는 데 집중하고 있다. 그걸 위한 여러 가지 테크닉들을 배울 것. 그래서 네트워크의 레이어별로 몇 개의 파라미터로 이루어져 있고, 전체 파라미터는 몇 개인지 감을 익히는 것이 중요하다.
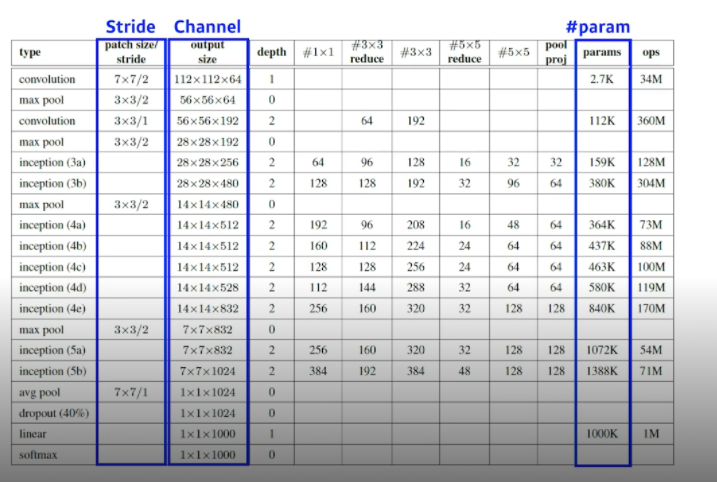
Convolution Arithmetic (of GoogLeNet)
- NN의 parameter 수를 직접 계산해보고 아래 표가 맞는지 확인해보자
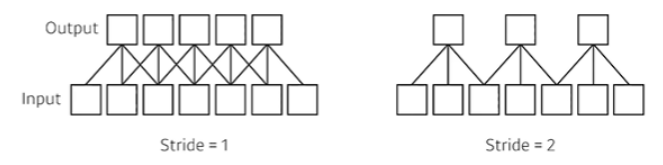
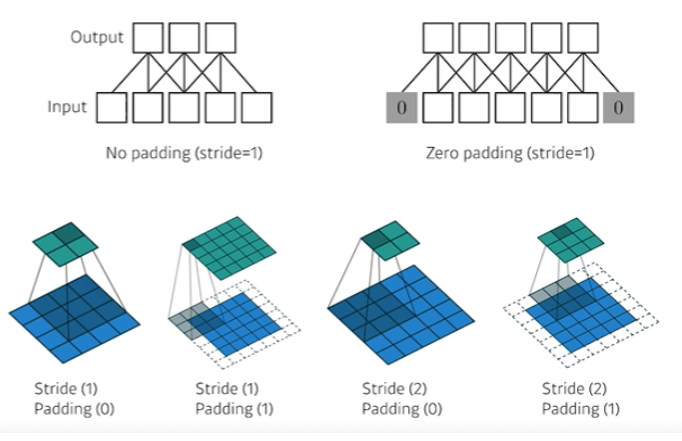
Stride
- 넓게 걷는다. Stride가 1이라는 것은 매 픽셀마다 한 칸 찍고, 한 칸씩 띄어서 찍는 것을 의미
- 7개의 input와 3짜리 filter 있을 때, Stride에 따른 output의 변화를 볼 수 있음
Padding
- Zero padding : 0으로 덧대줌으로써 가장자리도 찍을 수 있게 해주면서 input과 output의 출력을 동일하게 만들어줌
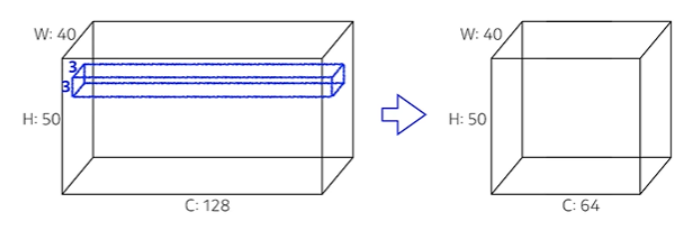
Convolution Arithmetic
- Padding(1), Stride(1), 3x3 Kernel
- 파라미터 수를 계산해보자
- 우리가 Convolution Feature map(Convolution operator)로 나오는 다음 단 layer의 한 겹, 한 채널을 만들기 위해서는 기본적으로 kernel dimension이 3x3이 있어야 하고(padding이 1이므로) 자동으로 각각의 kernel의 channel 크기는 내가 가지고 있는 input 크기와 같아야 한다(그래야 nxnx1차원으로 나옴). → kernel : 3x3x128
- 그렇게 계산하면 40x50x128 * 3x3x128 → 40x50x1이 나온다. 우리가 결국 필요한 것은 Channel이 64니까 이러한 filter(kernel)이 64개 필요하다.
- 그래서 필요한 parameter 숫자는 3x3x128x64 = 73,728개다.
- 사실 parameter 숫자는 convolution operator인 kernel에만 dependent 하기 때문에 padding이나 stride에는 independent하다.
- 대충 네트워크 모양만 봐도 파라미터 숫자에 대한 단위(만, 천,...)에 대한 감이 와야 한다.
Exercise
다음의 사진은 AlexNet의 Network이다. 각 layer별로 parameter 개수를 구해보아라.
- First Layer : 입력으로 들어오는 이미지가 224x224x3구나, 여기에 11x11 kernel이 이루어진다. 숨겨진 채널은 3일 것, 다음 채널이 48이니까 parameter 숫자는
→ $11\times11\times3\times48*2\approx35k$, 2가 곱해진 이유는 원래 96짜리 채널을 만들어야 하는데 당시 GPU가 좋지 않아서 48 채널짜리를 2개 만들었기 때문 - Second Layer : 55x55x48 * 5x5x48, 128개의 filer → $5\times5\times48\times128*2\approx307k$
- Third Layer : 27x27x128 * 3x3x128, 192 → $3\times3\times128\times192*2\approx884k$
- 4th Layer : 13x13x192 * 3x3x192, 192 → $3\times3\times192\times192*2\approx663k$
- Final Layer : 13x13x192 * 3x3x192, 128 → $3\times3\times192\times128*2\approx442k$
- 그다음 layer는 Dense layer, 즉 MLP 또는 fully-connected layer이다. fully connected layer의 차원은 input에 있는 파라미터의 개수와 아웃풋 layer의 파라미터 개수를 곱한 것만큼이다. → $13*13*128*2\times2048*2\approx177M$
- 다음 layer는 $2048*2\times2048*2\approx16M$, 마지막은 $2048*2\times1000\approx4M$
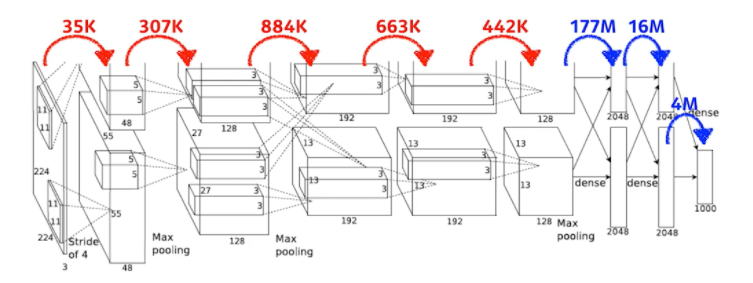
- 빨간색의 Convolution layer, 파란색이 Dense layer, MLP인데 딱 봐도 파라미터의 숫자가 엄청 차이 난다. 왜 그럴까?
- Convolution operator가 각각의 하나의 커널이 모든 위치에 대해서 동일하게 적용되기 때문, 뉴럴 네트워크의 성능을 높이기 위해선 파라미터의 개수를 줄이는 것이 중요한데, 대부분 파라미터가 fully connect layer에 들어가 있기 때문에 네트워크가 발전되는 성향이 뒷단의 fully connect layer를 최대한 줄이고 앞단의 convolution layer를 깊게 쌓는 것이 최근의 트렌드이다.
- 1x1 Convolution 등 여러 가지를 사용해서 최대한 깊게 쌓고 파라미터의 개수는 줄인다.
1x1 Convolution
- 이미지에서 영역을 보진 않는다. 이미지에서 한 픽셀만 보고 채널만 줄인다.
- 왜 하는가?
- Dimension reduction
- To reduce the number of parameters while increasing the depth
- 방금 이야기했던 것처럼 parameter 수는 줄이면서 depth는 늘림
- e.g., bottleneck architecture

(05강) Modern CNN - 1x1 convolution의 중요성
- 이름만큼 완전 Modern 한 CNN은 아니다. 나중에 더 좋은걸 배울 것
ILSVRC
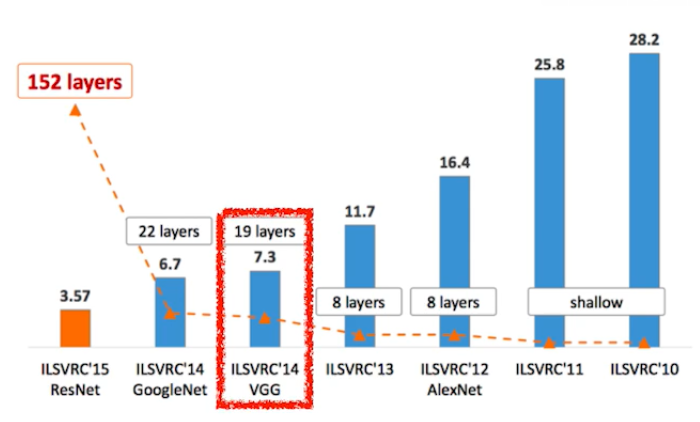
- ImageNet Large-Scale Visual Recognition Challenge
- Classification / Detection(bounding box를 찾는) / Localization(하나의 물체를 찾는) / Segmentation(여러 개를 찾는)
- 1000 different category
- Over 1 million images
- Training set : 456,567 images
- Human은 어떻게 측정했을까? 한 박사가 자신을 트레이닝시키고 일부 테스트 데이터를 라벨링 해보면서 측정했다고 함 with 동료들

AlexNet
- Alex Krizhevsky, IIya Sutskever, and Geoffery Hinton, "ImageNet Classification with Deep Convolutional Neural Networks, " NIPS, 2012
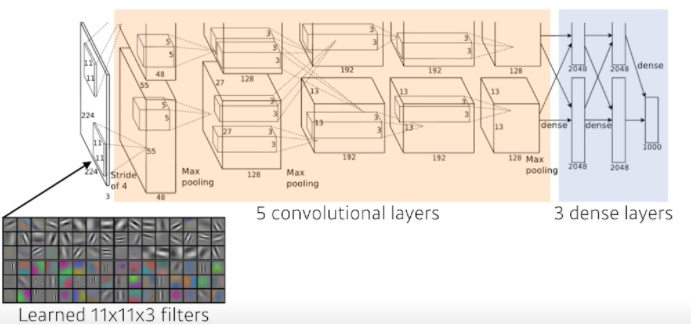
- Input에 11x11 filter를 사용하는데 parameter 관점에서 바라봤을 때 좋은 선택은 아님
- 하나의 Convolutional kernel이 볼 수 있는 영역은 커지지만 상대적으로 필요한 파라미터가 더 많아짐
- 5개의 convolutional layer와 3개의 dense layer, 즉 8단으로 이루어져 있음
- Key ideas : AlexNet은 어떻게 성공할 수 있었는가?
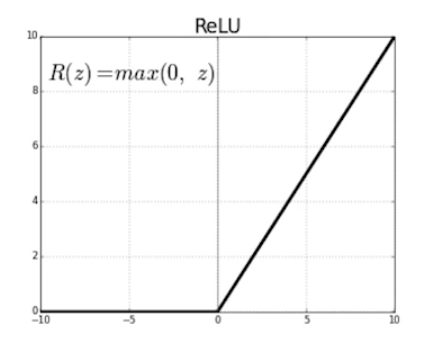
- Rectified Linear Unit (ReLU) activation을 사용했음
- 활성함수가 가져야 하는 첫 번째 조건은 nonlinear여야 한다.
- 마지막 slope가 1이기 때문에(0보다 클 때의 미분이 1이다) 그레디언트가 사라지나 네트워크를 깊게 쌓았을 때 망치는 현상이 없음(gradient vanishing)
- GPU implementatation (2 GPUs) 2개의 GPU를 사용함
- Local response normalization(LRN : 입력 공간에서 response가 너무 큰 거는 죽여버리는 것, 지금은 잘 활용되지 않으니까 신경 안 써도 된다), Overlapping pooling(max pooling)
- Data augmentation
- Dropout
- Rectified Linear Unit (ReLU) activation을 사용했음
- 지금 볼 때는 당연해 보이지만, 그 당시(2012)에는 당연하지 않았다. 지금의 일반적으로 잘 되는 기준을 잡아준 논문이다.
- ReLU Activation
- Preserve properties of linear models 선형 모델들이 가지고 있는 좋은 성질들을 유지해준다.
- 그레디언트가 activation 값이 0보다 많이 커도 그레디언트는 그대로 가지고 있게 됨
- Easy to optimize with gradient descent
- Good generalization ← 결과론적인 이야기
- Overcome the vanishing gradient problem → ReLU의 핵심
- Sigmoid와 tanh의 slope가 0을 기점으로 값이 커지면 점점 줄어들게 된다.
- slope가 결국 그레디언트인데 내가 가진 값이 0에서 많이 벗어나게 되면 그레디언트가 굉장히 0에 가까워짐, vanishing gradient
- Preserve properties of linear models 선형 모델들이 가지고 있는 좋은 성질들을 유지해준다.
VGGNet
- Karen Simonyan, Andrew Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition, " ICLR, 2015

- Increasing depth with 3x3 convolution filters (with stride 1) - 독특한 점은 filter로 오직 3x3 만 사용했다는 것
- 1x1 convolution for fully connected layers → 이걸 통해서 파라미터 수를 줄이려고 한 것은 아니기 때문에 중요하지는 않음
- Dropout (p=0.5)
- VGG16, VGG19 - layer의 개수에 따라, 16개면 VGG16
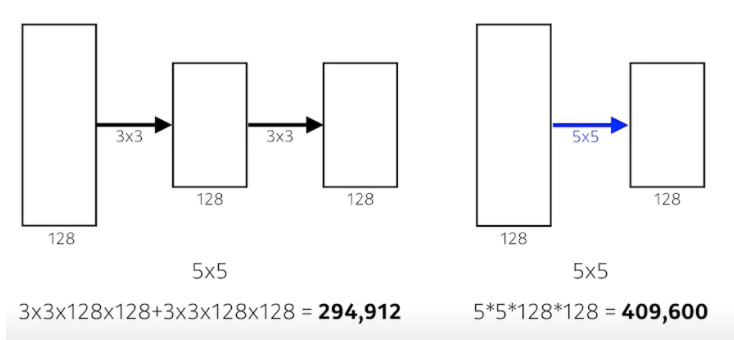
- Why 3x3 convolution?
- 우리가 filter의 크기가 커짐으로써 얻는 이점은 filter로 찍었을 때 고려되는 input의 크기가 커진다는 점이다. 이것을 바로 Receptive field라고 부름
- 하나의 convolution feature map 값을 얻기 위해서 고려할 수 있는 입력의 spatial dimension을 respective field라 부른다.
- 가장 마지막 단의 하나의 값은 중간에 있는 값의 3x3을 보게 되고, 그 중간 레이어의 1개의 값은 또 그 전의 값의 3x3을 보게 되니까 사실상 마지막 레이어의 1개의 값은 인풋 레이어의 5x5의 픽셀 값이 합쳐진 값이 된다.
- 그래서 3x3 2개를 사용하는 것과 5x5 1개를 사용하는 것은 Receptive field의 관점에서는 똑같다. 하지만 파라미터의 관점에서 3x3 2개를 사용할 때의 parameter 수가 훨씬 적다.
- 그래서 그 뒤의 논문에서 kernel의 spatial dimension은 7x7을 벗어나지 않음 → 너무 파라미터 수가 많아지기 때문
GoogLeNet
- Christian et al. "Going Deeper with Convolutions", CVPR, 2015
- 1x1 Feature map이 dimension induction의 효과가 있다. Spatial dimension이 아니라 depth 방향의 채널을 줄인다.
- 1x1 Convolution을 잘 활용해서 전체적인 parameter 수를 줄이는 법을 배우자.

- 22단임
- 비슷해 보이는 네트워크가 반복된다. → 네트워크 모양이 네트워크 안에 있고 해서 NIN구조라고 부름
- GoogLeNet won the ILSVRC at 2014
- It combined network-in-network (NiN) with inception blocks
- Inception blocks
- Convolution filter를 하기 전에 1x1 block을 해줌
- What are the benefits of the inception block?
- 1개의 입력에 대해서 여러 개의 receptive filed를 갖는 filter를 거치고, 이걸 통해서 여러 개의 response들을 concatenation 하는 것도 중요하지만, 전체적인 네트워크의 파라미터를 줄여준다. 그래서 굉장히 많이 사용해줌
- 1x1 convolution can be seen as channel-wise dimension reduction
- 1x1 convolution은 채널 방향으로 dimension을 줄이는 데 효과가 있다.

Inception Block
- Benefit of 1x1 convolution
- 입력과 출력이 동일한데 반해 파라미터 개수가 굉장히 줄어든다.
- 입력과 출력이 동일하기에 Receptive field 차원에서도 같다.

- depth가 길어지는 효과도 받을 수 있다. → 깊게 구성하는 게 왜 좋은가? 그 과정에서 더 많은 수의 비선형함수(ReLU)를 사용해서 복잡한 패턴을 더 잘 인식할 수 있게 된다.
1x1 convolution이란,
GoogLeNet 즉, 구글에서 발표한 Inception 계통의 Network에서는 1x1 Convolution을 통해 유의미하게 연산량을 줄였습니다. 그리고 이후 Xception, Squeeze, Mobile 등 다양한 모델에서도 연산량 감소를 위해 이..
hwiyong.tistory.com
Quiz. Which CNN architecture has the least number of parameters?
- AlexNet (8-layers)
- VGGNet (19-layers)
- GoogLeNet (22-layers)
-
- GoogLeNet이 가장 작다.
- AlexNet이 60M, VGGNet이 110M, GoogLeNet이 4M, GoogLeNet의 경우 깊이는 가장 깊지만 파라미터 수는 가장 적은 굉장한 모습을 보여준다. 뒷단의 Dense layer를 줄이고, AlexNet의 11x11 layer를 줄이고, 1x1으로 feature dimension을 줄였기 때문에 가능했던 것 → 네트워크는 점점 깊어지고, 파라미터 수는 점점 줄어들고 성능은 좋아짐
ResNet
- Kaiming He, Xiangyu Zhang, Shaoquing Ren, Jian Sun, "Deep Residual Learning for Image Recognition, ", CVPR, 2015
- Deeper neural networks are hard to train
- 보통 파라미터 수가 많아지면 2가지의 문제가 있다.
- Overfitting - training error는 줄어드는데, test error는 커지는 것, generalization이 안 좋음
- 딥러닝은 이 경우에 해당하지는 않음
- 네트워크가 커짐으로써 애초에 학습 자체가 아무리 많이 하더라도 잘 안 되는 것
- Overfitting - training error는 줄어드는데, test error는 커지는 것, generalization이 안 좋음
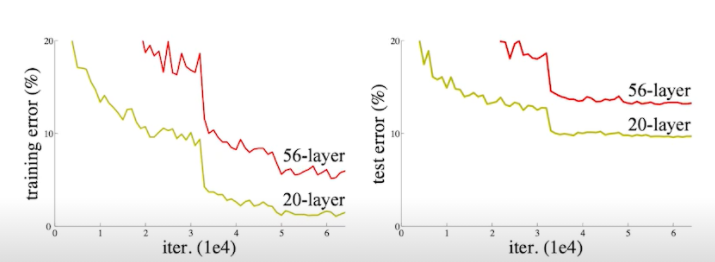
- 그래서 ResNet은 Residual connection==identity map(skip connection)이라는 것을 추가해줌
- 아래 2번째 사진처럼 identity map을 추가해줌으로써 학습 자체가 더 잘 되게 만들어줌
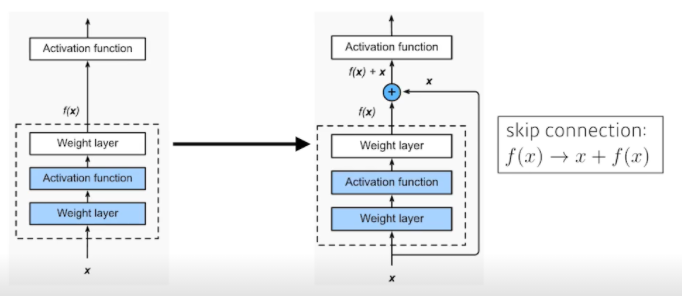
- 이게 왜 잘 되는 거야? 레이어 간 연결이 순서대로 연속적만 있는 것이 아니라, 중간을 뛰어넘어 더하는 shortcut이 추가되면서 그레디언트를 직접적으로 잘 전달하였기에 gradient vanishing/exploding 문제를 해결하는 큰 효과를 불렀다. 딥러닝에서는 정말 gradient vanishing/exploding, 이 문제가 critical 하고 이것을 해결하기 위해 많은 방법들이 도입되었다. 그리고 그 방법들마다 혁신적인 성공을 거두었다.
- 기존 모델은 앞부분의 feature가 뒤쪽까지 영향을 직접적으로 전달하는 것이 아니라, 중간을 거쳐 전달되기 때문에 학습의 과정에서 크게 변했다. 그런데 shortcut connection을 추가해주면 이전으로부터 얼마큼 변하는지 나머지(residual)만 계산하는 문제로 변한다. 즉, 현재 레이어의 출력 값과 이전 스케일의 레이어 출력 값을 더해 입력받기 때문에, 그 차이를 볼 수 있게 되는 것. 따라서 학습하는 과정에서 그 '조금'을 하면 되는 것이고, 더 빠르게 학습한다.
- x에 f를 씌워준 f(x)의 값은 convolution을 거듭할수록 값이 소실될 수 있다. 이것을 엄청 간단하게 x, 그 자체 값을 더해줌으로써 해결해준 것. 차이만 학습해주면 되니까 연산에는 큰 무리가 안 가면서 값은 유지해줌으로써 문제는 해결해준 것이다.
- ResNet (Shortcut Connection과 Identity Mapping) [설명/요약/정리]
- 아래 2번째 사진처럼 identity map을 추가해줌으로써 학습 자체가 더 잘 되게 만들어줌
ResNet (Shortcut Connection과 Identity Mapping) [설명/요약/정리]
등장 배경 레이어가 많아져, 인공신경망이 더 깊어질 수록 gradient vanishing/exploding 문제가 커집니다. 이전의 다른 방법들로 이 문제를 해결했다고 생각했지만, 수십개의 레이어를 가진 모델에서는
lv99.tistory.com
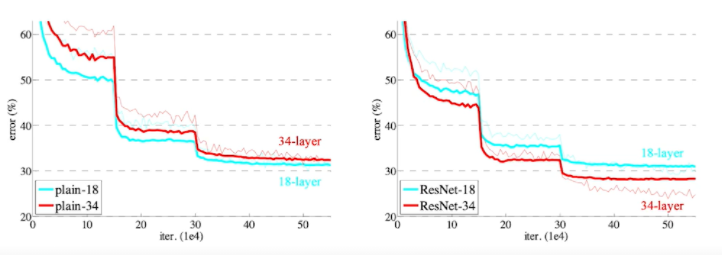
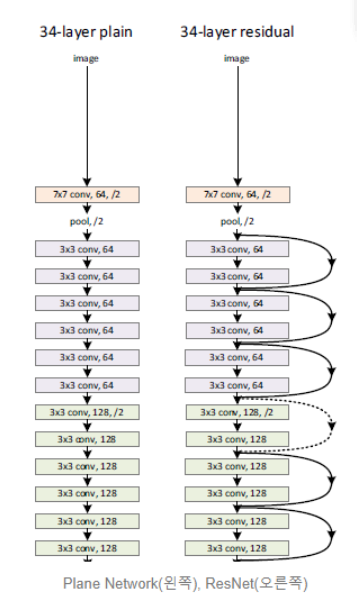
- 깊게 쌓으면 전체적인 성능이 줄어서 못썼는데 ResNet 구조를 사용함으로써 조금 더 깊게 쌓을 수 있게 되었다.
- 더하기 위해서는 차원이 같아야 하기 때문에 1x1 convolution으로 차원을 맞춰준다.
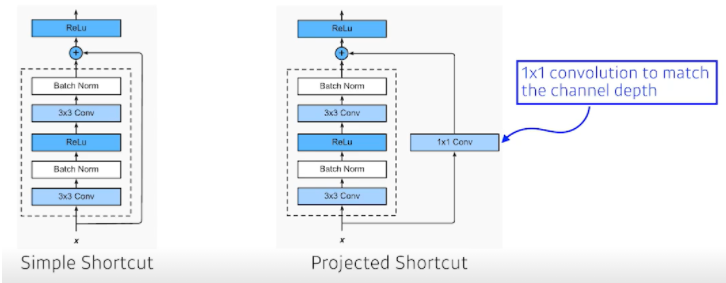
- Add an identity map after nonlinear activations
- Batch normalization after convolutions
Bottleneck architecture

- GoogLeNet의 Inception이랑 똑같은 개념
- 1x1을 Convolution을 곱해줌으로써 채널을 맞춰주는 것
- 그래서 ResNet으로 갈수록 성능은 좋아지고 파라미터 수는 줄어든다

정리
1x1 Convolution이라는 구조를 활용해서 채널을 줄이게 되고 그렇게 줄어든 채널에서 3x3 혹은 5x5 Convolution을 함으로써 Receptive field를 키우고 다시 1x1 Convolution으로 원하는 채널을 맞춰줌으로써 파라미터 수를 줄임과 동시에 네트워크를 점점 깊게 쌓아서 성능을 높이는 전략이다.
DenseNet
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Weinberger, "Densely Connected Convolutional Networks, " CVPR, 2017
- DenseNet uses concatenation instead of addition
- 큰 관점에서 보면 ResNet은 더하는 거니까, 더하면 값이 섞이니까 대신 concat 하면?

- 큰 관점에서 보면 ResNet은 더하는 거니까, 더하면 값이 섞이니까 대신 concat 하면?
- 근데 그러면 채널이 2배씩 기하급수적으로 계속 커진다.
- 채널이 커지면 그에 따라서 거기 가해지는 Convolutional feature 역시 같이 커짐
- 그러면 파라미터 수가 많아지고 그것은 우리가 원하는 것이 아니다.
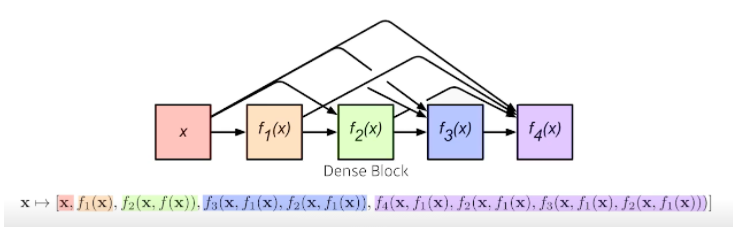
- 우리가 원하는 대로 하려면 중간에 채널을 줄여줘야 한다.
- 어떻게 할까? 1x1 Convolution!
- Dense Block
- Each layer concatenates the feature maps of all preceding layers
- The number of channels increases geometrically.
- Transition Block
- BatchNorm → 1x1 Conv → 2x2 AvgPooling
- Diemsion reduction
- Dense Block으로 늘리고 Transition Block으로 줄이고 반복하는 게 DenseNet
- 간단한 문제에서 Dense Net이 굉장한 성능을 보일 때가 있다.
- 그래서 간단한 모델을 만들어야 할 때 ResNet이나 DenseNet을 사용하면 웬만한 성능이 보장될 것

Summary
- Key takeaways
- VGG : repeated 3x3 blocks
- GoogLeNet : 1x1 convolution
- ResNet : skip-connection
- DenseNet : concatenation
(06강) Computer Vision Applications
Semantic Segmentation
- 이미지가 있을 때 각 픽셀마다 분류를 하는 것
- 단순 분류보다 굉장히 어렵다.
- 자율 주행 같은 곳에 많이 활용이 된다.
- 내 앞에 이미지가 이미지, 도로, 사람, 신호등인지 다 구분해야 하기 때문
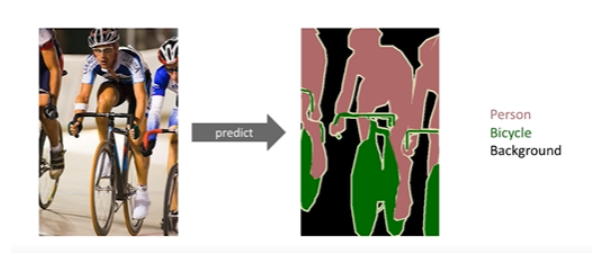
Fully Convolutional Network
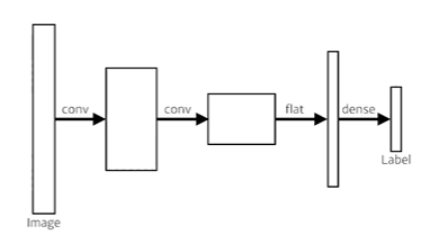
- This is how an ordinary CNN looks like
- 기본적인 CNN 구조는 Convolution과 Pooling을 이것저것 한 마지막에 dense layer를 통과시켜서 1000개짜리 output을 뽑아내는 것

- This is a fully convolutional network
- Dense layer를 없애고 싶은 것, 원래 아웃풋이 1000단짜리가 나왔으면 이것을 Convolution layer로 바꾸자는 것
- Dense layer를 없애는 과정을 convolutionalization이라 한다.
- 이것의 가장 큰 장점은 Dense layer가 없는 것이다.
- 두 과정은 파라미터가 정확히 일치한다. flat후 dense 하는 과정을 convolution으로 바꿨을 뿐
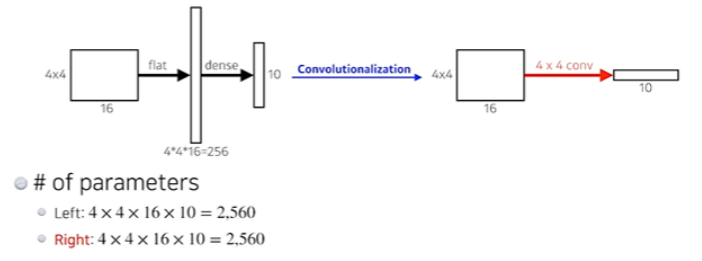
- This process is called convolutionalization
- 그렇다면 네트워크, 파라미터, 아웃풋 모두 똑같은 이 과정을 왜 진행하는가?
- Fully Convolutional Network의 가장 큰 특징은 input dimension(spatial)에 independent 하다는 점이다
- 이미지 크기를 신경 쓰지 않는다
- 이미지 크기가 커지더라도 convolution의 shared parameter 특성 때문, 동일한 filter가 동일하게 찍기 때문 → 아웃풋만 커진다.
- Transforming fully connected layers into convolution layers enables a classification net to output a heap map
- 32x32로 만들어진 네트워크가 있을 때 1개의 분류로 나타나는 것이 아니라 히트맵처럼 결과를 뽑아준다
- 해당 이미지에 고양이가 어디에 있는지 히트맵을 보여준다. 주의해야 할 점은 spatial dimension이 많이 줄어들었다. 100x100이었다면 10x10으로, 하지만 우리는 이미지가 커지면 fully convolutional network를 하게 되면 단순히 분류만 했던 network가 히트맵으로 나올 수 있는 가능성을 찾았다.

- While FCN can run with inputs of any size, the output dimensions(spatial) are typically reduced by subsampling
- FCN을 시행해주면 100x100 → 10x10처럼 디멘젼이 줄어들 수밖에 없다.
- So we need a way to connect the coarse output to the dense pixels
- 그래서 그것을 원래처럼 늘려주는 방법이 필요하다.

Deconvolution (convolution transpose)
- 직관적으로는 convolution의 역연산
- 원래 stride를 2로 하면 절반으로 줄어들었는데 그것을 반대로 해주는 방법
- 엄밀하게 말하면 실제로 복원하는 건 불가능하다. 2와 8을 합해서 10을 만들었는데 10을 가지고 2와 8을 찾는 건 말이 안 되기 때문

- 원래 Convolution이 5x5에 3x3 filter를 씌워서 2x2를 만들었다면, Deconvolution은 2x2의 이미지에 패딩을 많이 줘서 3x3 filter를 씌워서 5x5로 복원하는 것
- 엄밀한 복원은 아니지만, 네트워크 숫자, 파라미터의 관점에서 봤을 때는 역연산

Result
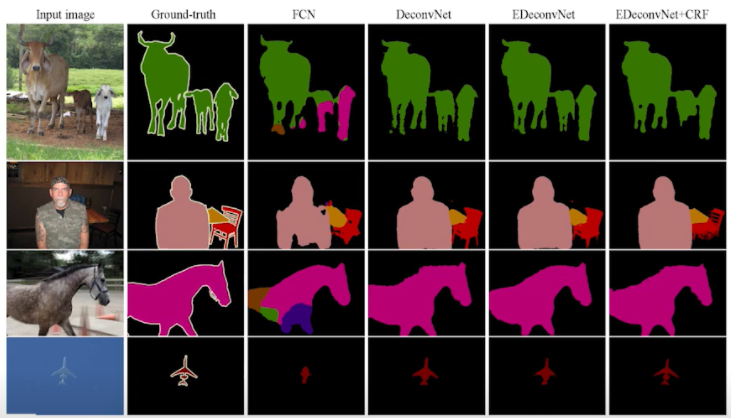
Detection
- 방금 전의 과정과 굉장히 비슷하지만 pixel 단위로 찾는 것이 아니라 bounding box를 찾고자 하는 것
R-CNN
- 그걸 가장 쉽게 하는 게 RCNN
- 이미지에서 2천 개의 region을 뽑아냄(By Selective search)
- 크기가 다른 그 region들의 크기를 같게 맞춰줌(CNN에 넣기 위해)
- compute features for each proposal (using AlexNet)
- 마지막으로 SVM(support vector machine)을 가지고 분류해줌
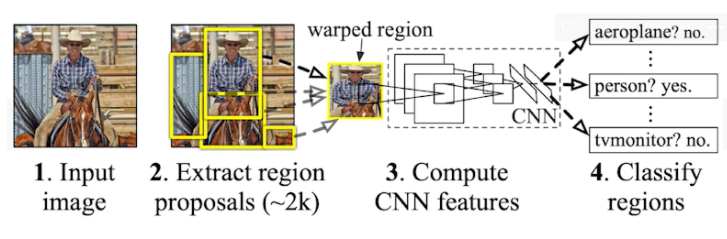
- 결과
- 이미지에서 대략 어떤 위치에 어떤 물체가 있는지 뽑아줌

SPPNet
- RCNN의 가장 큰 문제는 2천 개의 이미지를 다 CNN에 통과시켰어야 했다는 점이다
- 즉 Convolution Network를 2천 번 돌아야 하나의 이미지를 해석할 수 있다는 것
- CPU에서는 1번 CNN 돌리는 데 1분이 걸렸음
- 그래서 SPPNet은 다 똑같은 데 이미지 안에서 CNN을 한 번만 돌렸다.
- 이미지에서 bounding box를 뽑고, 이미지 전체에 대한 convolutional feature map을 만든 다음에, 뽑힌 bounding box에 위치 해당하는 convolutional feature map의 tensor만 끌고 오자
- 그렇게 해서 속도를 높임
Fast R-CNN
- Fast R-CNN도 비슷한 컨셉을 가져온다.
- 이미지가 들어오면 우선 Selectiva search를 이용해서 2천 개의 bounding box를 뽑아온다.
- 그다음 convolutional feature map을 한 번 얻는다. (CNN을 한번 통과)
- 각각의 region에 대해서 ROI pooling이라는 고정된 길이의 feature를 뽑음
- 마지막에 NN을 통해 bounding box regression, 내가 얻은 bounding box를 어떻게 움직이면 좋을지, 그 박스의 라벨을 찾아준다.
- 이 부분이 SPPNet과의 차이점

Faster R-CNN
- Faster R-CNN = Region Propasal Network + Fast R-CNN
- 이미지를 통해 bounding box를 뽑아내는 Region Propasal이라는 것도 학습하자.
- 우리가 사용하던 Selective Search는 우리의 디텍션 방향과 맞지 않는다.
- 그래서 그 과정을 Region Propasal Network라 부르고, 그 부분이 Fast R-CNN과 다른 점
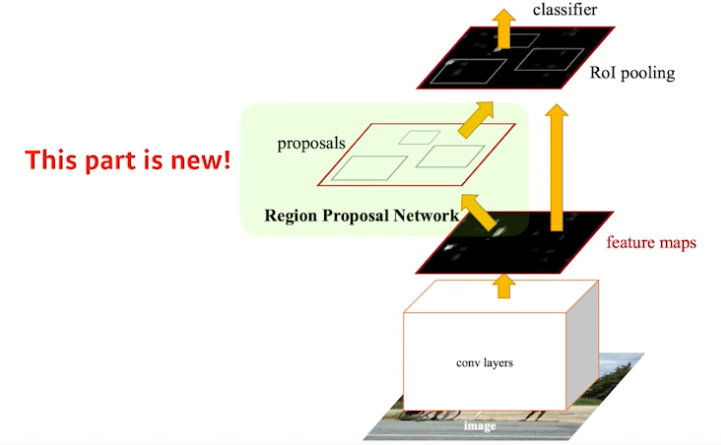
Region Propasal Network
- 이미지가 있으면 그 이미지의 특정 영역(patch)이 bounding box로써 의미가 있는지, 여기 안에 물체가 있을지 없을지를 찾아주는 것
- 이것을 해주기 위해서 anchor box라는 것이 필요하다
- Anchor box : 미리 정해둔 box의 크기
- 일종의 템플릿을 만들어두고 이것이 얼마나 바뀔지도 찾고 궁극적으로는 이 템플릿을 고정해두는 게 RPN의 특징이 된다.

- 여기서도 fully convoltional network가 사용되고, 이미지를 돌아가면서 filter를 찍게 되니까 해당 영역에 물체가 존재할지 아닐지를 판단해주게 되는 것
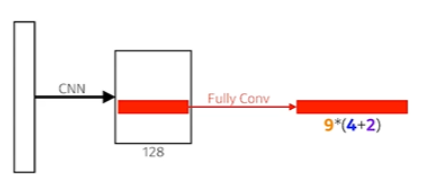
- 9 : Three different region sizes (128, 256, 512) with three different ration (1:1, 1:2, 2:1)
- RPN의 경우에는 Anchor box(predefined kernel) size가 9개가 있다. (128, 128), (256, 256), (512, 512)을 (1:1, 1:2, 2:1)의 비율로
- 4 : four bounding box regression parameters
- 각각의 region size마다 bounding box를 얼마나 키우고 줄일지, 높이와 넓이를 줄이고 키울지
- 2 : box classification (whether to use it or not)
- 상대적으로 적은 숫자의 Region Propasal을 만들어줘야 할 것, 모두 다 쓸모 있으면 할 이유가 없으니까. 그것을 판단해준다.
- 9 : Three different region sizes (128, 256, 512) with three different ration (1:1, 1:2, 2:1)
- 그래서 RPN은 9*(4+2)의 숫자의 채널을 가지게 된다.
- 그렇게 조금 더 결과가 좋은 Faster R-CNN이 만들어짐

YOLO

- YOLO (v1) is an extremely fast object detection algorithm
- baseline : 45 fps / smaller version : 155 fps
- It simultaneously predicts multiple bounding boxes and class probabilities
- No explicit bounding box sampling ( compared with Faster R-CNN)
- RPN을 통해 bounding box를 따로 뽑아서 CNN을 돌려서 분류를 하는 것이 아니라, 그냥 이미지 한 장에서 찍어서 바로 나오기 때문
- bounding box를 뽑는 과정이 없기 때문에 상당히 빠를 수 있는 것

- 이미지가 들어오면 YOLO는 SxS grid로 나눈다.
- If the center of an obejct falls into the grid cell, that grid cell is responsible for detection
- 이 이미지 안에 내가 찾고자 하는 물체의 중앙이 해당 grid 안에 들어가면 해당 물체의 bounding box와 해당 물체가 무엇인지를 같이 예측
- Each cell predicts B bounding boxes (B=5)
- 각각의 cell은 B개 (논문에서는 5개)의 bounding box를 예측하게 된다.
- Each bounding box predicts
- box refinement (x/y/w/h)
- confidence (of objectness)
- 박스를 찾아주고 그게 진짜 박스가 맞는지 box probability를 사용해서 찾아주게 됨
- Each bounding box predicts
- Each cell predicts C class probabilities
- 그와 동시에 그 bounding 박스(grid cell)에 속하는 중점에 있는 어떤 object가 어떤 Class인지 예측해줌
- 이 작업을 동시에 수행해준다
- In total, it becomes a tensor with SxS(B5+C) size
- SxS : Number of cells of the grid
- B*5 : B bounding boxes with offsets (x, y, w, h) and confidence
- C : Number of classes

github특강1
- 생활코딩으로 활동하는 이고잉님
Git
- git client : git command line, source tree, VS code → VS code 내의 git 쓸 것
- git server : github.com, gitlab,... → github.com 쓸 것
우리도 github.com이라는 서비스에서 출발할 것이다.
- commits에서 Browse file 하면 그때의 컴퓨터 상태로 돌아감
- Issue에서 New issue로 기능에 대한 게시판이 있다. Labels를 보면 bug, documentation 등 category를 구분할 수 있음
- Assignees로 어떤 사람에게 할당할 수 있음
- Close Issue로 작업이 마무리됨을 알릴 수 있다.
- 파일 들어가서 고칠 부분 누르고 Reference in new issue를 눌러서 issue를 날릴 수도 있다.
Insights
- 이 프로젝트가 어떤지 보여주는 지표들이 있음
Wiki
- 프로젝트의 룰 등
- VS code의 설정에서 Exclude를 들어가면 안 보이게 만들 파일과 그렇지 않을 파일을 구별해줄 수 있다
- Ex) default로 .git 파일은 보이지 않게 되어 있음
- Extension에서 git graph를 깔아주면 좌측 하단에 Git Graph라는 버튼이 생긴다.
- Git history 확인 가능
- origin은 원격저장소의 별명
- origin과 main 사이에 있는 commit 들은 아직 main에만 있는 것. 원격저장소에 올라가 있지 않다.

- Push를 하면 이제 main과 origin이 함께 있는 걸 확인할 수 있다.
- dropbox는 자동으로 업로드가 되지만 git은 수동으로 업로드해야 한다.
- 엄격하게 관리해야 하기 때문
- pull == fetch + merge , fetch는 download
- 오늘의 한 마디. 이건 저도 잘 모르겠네요 제가 모르는 건 당분간 몰라도 됩니다
- 이 자신감 있는 멘트가 정말 멋있었다. 이런 발언을 자신 있게 할 수 있는 사람이 되어야겠다 🙂
피어세션
- 수업내용 정리: 허정훈 캠퍼
- 피어세션 정리: 이준혁 캠퍼
Q1. 인풋 이미지의 채널과 커널의 채널은 같아야 하는가?
A. 그렇다
Q2. Dense layer로 넘어갈 때 별도 연산인가 reshape인가?
A. Flatten을 쓰는데 reshape이랑 거의 같다고 이해하면 된다.
Q3. Receptive field?
A. 딥러닝이 고려할 수 있는 이미지 범위.
- 3*3 convolution 2번과 5*5 convolution의 reception field는 같다

Q4. 11 conv 참고자료(pointwise convolution = 11 convolution)

Q5. selective search를 좀 자세히 설명해 주시면

[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week2_Day10. 딥러닝의 기본을 알다. (0) | 2021.08.15 |
|---|---|
| [BoostCamp] Week2_Day9. "Key"word. Transformer (0) | 2021.08.14 |
| [BoostCamp] Week2_Day7. CV vs. NLP 선택의 기로 (0) | 2021.08.12 |
| [BoostCamp] Week2_Day6. 내가 원했던 수업 (0) | 2021.08.10 |
| [BoostCamp] Week1_Day5. 한 주의 마무리 (2) (0) | 2021.08.09 |



