
호기심 많은 분석가
[BoostCamp] Week1_Day5. 한 주의 마무리 (2) 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개요
[BoostCamp] Week1_Day5. 한 주의 마무리 (1)
부스트캠프 개발자의 지속 가능한 성장을 위한 학습 커뮤니티 boostcamp.connect.or.kr 개요 폭풍같았던 일주일이 지나갔다. 첫 주는 프리코스 때 들었던 강의만 다시 다뤘던 것이라 내용이 굉장히 많
herjh0405.tistory.com
이 포스팅에 이어 5일 차의 학습 내용과 멘토링, 피어세션, 그리고 오피스 아워에 대한 이야기를 포스팅하겠다. :)
개인 학습
(Python 6강) numpy
파이썬은 C에 비해 훨씬 느리기 때문에 큰 Matrix에 대해선 다루기 어렵다.
- 그렇다면 어떻게 극복할 수 있을까?
- 적절한 패키지의 사용
- 그 중 파이썬 과학 처리 패키지 Numpy에 대해 알아보겠다.
Numpy
- Numerical Python
- 고성능 과학 계산용 패키지
- Matrix와 Vector와 같은 Array 연산의 사실상의 표준
특징
- 일반 List에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열에 대한 처리를 지원함
- 선형대수와 관련된 다양한 기능을 제공함
- C, C++, 포트란 등의 언어와 통합 가능
Array creation
test_array = np.array([1,4,5,8], float)
# Shift+Tab 누르면 jupyter에선 도움말 볼 수 있음
print(test_array) # array([1., 4., 5., 8.])
type(test_array[3]) # numpy.float64- numpy는 np.array 함수를 활용하여 배열을 생성함 → ndarray 객체라 부름
- numpy는 하나의 데이터 type만 배열에 넣을 수 있음 (위로 치면, float와 int를 섞을 수 없다는 것)
- numpy의 ndarray와 list의 가장 큰 차이점은 Dynamic typing의 차이다.
- ndarray는 float타입으로 선언하기 때문에 그 앞의 리스트에 어떤 타입의 원소가 들어오더라도 float로 변환시켜줌
- C의 Array를 사용 → 그래서 굉장히 빠름
Array shape - ndim&size
- array의 RANK에 따라 불리는 이름이 있음

- tensor는 차원이 늘어갈 때마다 row의 차원이 한 칸씩 밀린다
- ndim - number of dimension
- size - data의 개수
- nbytes - ndarray object의 메모리 크기를 반환함
Handling shape
- reshape : Array의 shape의 크기를 변경함 (element의 개수는 동일)
- flatten : 다차원 array을 1차원(vector)으로 변경 - (n, )
Indexing & Slicing
a = np.array([[1,2,3], [4.5, 5, 6]], int)
print(a)
print(a[0, 0]) # Two dimensional array representation #1
print(a[0][0]) # Two dimensional array representation #2
- list와 달리 행과 열 부분을 나눠서 slicing이 가능함
- matrix의 부분 집합을 추출할 때 유용하다.
arange
- array의 범위를 지정하여, 값의 list를 생성하는 명령어
np.arange(30) # range : List의 range와 같은 효과, integer로 0부터 29까지 배열 추출
# array([0,1,2,3,...,27,28,29])
np.arange(0, 5, 0,5) # floating point도 표시 가능함
# 리스트에서는 안되니까 np.arange로 만들어주고 tolist()로 하는 것도 방법
np.zeros(shape=(10,), dtype=np.int8)
np.ones((2,5))
# empty - shape만 주어지고 비어있는 ndarray 생성(memory initialization이 되지 않음)
# 그냥 형태만 잡아주고 아무 값이나 들어가있음
np.empty(shape=(10,), dtype=np.int8)
# something_list
# 기존 ndarray의 shape의 크기 만큼 1, 0 또는 empty array를 반환
test_matrix = np.arange(30).reshape(5, 6)
np.ones_list(test_matrix) # test_matrix의 크기만큼 1이 꽉 차 있는 매트릭스 반환
# something_like
np.zeros_like(test_matrix, dtype=np.float32)
# identity
# 단위 행렬(i 행렬)을 생성함
np.identity(n=3, dtype=np.int8)
# eye
# 대각선이 1일 행렬, k 값의 시작 index의 변경이 가능
np.eye(N=3, M=5, dtype=np.int8) # 3X5행렬
np.eye(3, 5, k=2) # 3번째 열부터 대각행렬 시작
np.diag(matrix, k) # 대각 위치의 원소들 뽑아오기, 마찬가지로 k번째 시작 가능
# random sampling
np.random.uniform(0, 1, 10).reshape(2, 5) # 균등분포
# (3, 4)이면 3이 axis=0, 4가 axis=1 순서대로 생각하면 될 듯
# array의 경우 축이 늘어날 경우 row가 하나씩 밀리는데 새로 생기는 것이 axis=0이라고 생각하면 된다
# concatenate
a = np.array([1,2,3])
b = np.array([2,3,4])
np.vstack((a,b)) # 아래위로 concat
np.concatenate((a,b), axis=0)
a = np.array([[1,2], [3,4])
b = np.array([[5,6]])
np.hstack((a,b)) # 좌우로 concat
np.concatenate((a,b.T), axis=1)
# Operations b/t arrays
# np.array * np.array는 각 원소들끼리의 곱(shape가 같아야함)
test_a.dot(test_b) # dot product
# broadcasting
# shape이 다른 배열 간 연산을 지원하는 기능
# matrix와 scalar 간의 연산
# concat은 numpy보단 list가 빠름
# all&any
a = np.arange(10)
np.any(a>5), np.all(a<0)
# True, False
np.all(a>5), np.any(a<10)
# False, True
# **where, 조건에 만족하는 Index**값을 뱉어냄, 요거 좀 중요
a = np.array([1., 3., 0.])
np.where(a>0, 3, 2) # 조건문, 참일 때, 거짓일 때 값
# array([3, 3, 2])
np.where(a>0)
# (array[0, 1],)
# argmax&argmin
a = np.array([1, 2, 4, 5, 8, 78, 23, 3])
np.argmax(a), np.argmin(a)
# (5, 0) : Index를 의미함
a = np.array([[1,2,4,7],[9,88,6,45],[9,76,3,4])
np.argmax(a, axis=1), np.argmin(a, axis=0)
# (array([3,1,1]), array([0,0,2,2]))
# numpy에서는 웬만해서 for문을 쓰지마라, argmax, argmin을 이용
# fancy index
# numpy는 array를 index value로 사용해서 값을 추출하는 방법
a = np.array([2,4,6,8], float)
b = np.array([0,0,1,3,2,1], int) # 반드시 integer로 선언
a[b] # array([2,2,4,8,6,4]) # bracket index, b 배열의 값을 index로 하여 a의 값들을 추출함
a.take(b) # 마찬가지로 위와 같다
a = np.array([[1,4],[9,16]], float)
b = np.array([0,0,1,1,0], int)
c = np.array([0,1,1,1,1], int)
a[b,c] - 그 외에도 다양한 수학 연산자 제공 (np.something 호출)
(Python 7강) pandas
Pandas
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리
- pandas의 파라미터로는 sep과 delimiter가 존재한다.
- 이 두 개의 차이는 무엇인가?
- delimiter는 separator의 Alias라고 한다. 동일함, 구분자를 의미
- header=None, 칼럼들 이름이 지정되어있지 않다.
※ Series()의 () 안에서 Shift+Tab을 누르면 Help가 나옴
DataFrame
- DataFrame(raw_data, columns=['age', 'city']) 이렇게 컬럼 불러올 수도 있음
- 비슷하게 DataFrame(raw_data, columns=['age', 'city', 'total']) 이렇게 새로운 column을 추가해주는 것도 가능
- df.debt = df.age > 40 이런 식으로 True, False를 새로운 컬럼으로 만드는 것도 가능
- df.index = df['account'] : index를 Series의 값들로 변환시켜주는 건데 기억하자
Series Operation
- index를 기준으로 연산 수행, 겹치는 index가 없을 경우 NaN값으로 반환
- Series와 Dataframe을 합치면 columns을 기준으로 broadcasting이 발생함
map, lambda, apply
# 데이터의 형태를 보기 위해 head().T도 종종 사용한다
df.head().T
z = {1:'A', 2:'B', 3:'C'}
s1.map(z)
# 이게 바로 먹는구나
df.sex.replace({'male':0, 'female':1})
df.sex.replace(['male', 'female'], [0, 1])
# 이렇게도 사용가능하지만 잘 쓰지는 않을 듯- apply for dataframe
- map과 달리, series 전체(column)에 해당 함수를 적용
- 입력값이 series 데이터로 입력받아 handling 가능
f = lambda x : x.max() - x.min() df_info.apply(f) # 이렇게 전체를 들고 오기 때문에 max, min 적용이 가능한 것
- unique
np.array(dict(enumerate(df['race'].unique())))
# array({0:'white', 1:'other', ...}) 이렇게 category마다 번호 할당 가능Groupby
- SQL groupby 명령어와 같음
- split → apply → combine과정을 거쳐 연산함

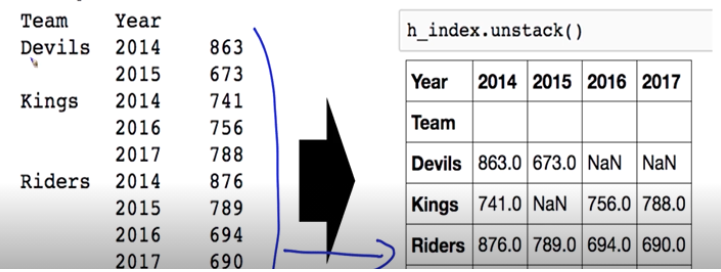
- 두 개의 column으로 groupby를 할 경우, index가 두 개 생성 - multiindex
- 이것을 Hierarchical index라고 부른다
- 이걸 unstack()을 해주면 기존에 있던 matrix 형태로 바꿔줌
- 늘 reset_index를 사용해줬는데 이젠 unstack을 쓰면 될 듯
- swaplevel
- index의 순서를 바꾸는 명령어
- h_index.swaplevel().sortlavel(0)
- h_index.sum(level=0)
Grouped
grouped = df.groupby('Team') # groupby 즉, split된 상태
for name, group in grouped :
print(name)
print(group)
grouped.get_group('Devils') # ket값의 이름으로 추출
# aggregation 원하는 통계값 추출
grouped.agg(sum)
grouped.agg(np.mean)
# lambda 함수도 적용 가능
grouped['Points'].agg([np.sum, np.mean, np.std]) # 특정 컬럼에 여러개의 function을 apply가능
# transformation
# aggregation과 달리 key값 별로 요약된 정보가 아닌, 개별 데이터의 변환을 지원
score = lambda x : (x.max())
grouped.transform(score)
# 이거 엄청 편한데? 한 그룹의 각각의 최댓값만 뽑아낼 때 편하겠다.
# filter
# 특정 조건으로 데이터를 검색할 때 사용
df.groupby('Team').filter(lambda x: len(x)>=3)
# len(x)는 grouped된 dataframe 개수
# dateutil.parser.parse, date타입으로 변환시키기 좋음
df_phone.groupby(['month', 'item']).agg({'duration':sum,
'network_type':'count',
'date':[min, 'first', 'nunique']})

Pivot_table
df_phone.pivot_table(['duration'],
index=[df_phone.month, df_phone.item],
columns=df_phone.network, aggfunc='sum', fill_value=0)
pd.crosstab(index=df_movie.critic, columns=df_movie.title, value=df_movie.rating,
aggfunc='first').fillna(0)
# groupby, pivot_table, crosstab은 거의 동일한 형태임
df_ipcr['ipc_class'].map(str) # 요거 좀 자주 써야겠다.Merge
# 두 dataframe이 column 이름이 다를 때
pd.merge(df_a, df_b, left_on='subject_id', right_on='subject_id')
# index 기준 join
pd.merge(df_a, df_b, right_index=True, left_index=True)Database connection
import sqlite3
# pymysql이랑 비슷한거
conn = sqlite3.connect('./data/flights.db')
cur = conn.cursor()
cur.execute('select * from airlines limit 5;')
results = cur.fetchall()
results
df_airplines = pd.read_sql_query('select * from airlines;', conn)
writer = pd.ExcelWriter('./data/df_routes.xlsx', engine='xlsxwirter')
df_routes.to_excel(writer, sheet_name='Sheet1')
df_routes.to_pickle('./data/df_routes.pickle')멘토링
- 13-14시 박채훈 멘토님, 우리 피어님들과 같이 5주간 함께 하신다고 하심
- 카이스트 NLP 박사과정 2년 차 / 스캐터랩에서 인턴
- 화학과 전공하다가 전산학부로 전과
처음은 자기소개 시간을 가졌다.
- 구글 Docs에 적힌 질문들을 바탕으로 질의응답이 이어짐
- 실생활의 어떤 문제들을 가지고 인공지능으로 해결할 수 있다고 판단하시는가?
- 현재 사용되고 있지만 정확도를 높일 수 있는 부분들이 인공지능으로 해결할 수 있지 않을까?
- 논문 구현이 기업에서 요구하는 사항인 경우가 많은데 어떤 논문을 구현해보는 게 좋을까? 가장 낮은 난도의 논문은? 한 번은 꼭 구현해봐야 할 논문은 추리기가 사실 어려울 것 같은데ㅠ 개인적으로는 Transformer 모델을 논문만 보고 처음부터 짤 수 있으면 구현 능력은 충분하지 않을까 싶습니다.
- 코드 자체는 어렵지 않아도 데이터를 넣고 평가하는 게 되게 어렵다. 코드 작성뿐만 아니라 전체적으로 해보는 것을 추천한다
아래 논문은 NLP 분야의 감성 분류 (sentiment analysis) task를 위한 CNN 기반의 모델을 제안하였는데요. 처음 구현하기에 task 자체도 간단하고 모델도 온라인에 참고할만한 소스가 많아서 쉽게 시작하실 수 있을 것 같아요.
-Yoon Kim, Convolutional Neural Networks for Sentence Classification, EMNLP 2014
-
- 머신러닝 공부 중에 확률, 추정과 관련된 부분이 하면 어렵게 다가오는데요.
학부에서 배우는 확률 및 통계 과목 하나 듣고, 블로그 찾아보면서 공부하기는 너무 어려운 것 같습니다.
멘토님 공부하실 때 이런 쪽으로 어떤 책, 어떤 학교 과목들이 도움이 되셨는지 알고 싶습니다.- 아래의 책 및 이에 대한 coursera 수업도 도움이 되지 않을까 싶어요!
책: Mathematics for Machine Learning
온라인 강의: https://www.coursera.org/specializations/mathematics-machine-learning
- 아래의 책 및 이에 대한 coursera 수업도 도움이 되지 않을까 싶어요!
- NLP가 실무에서 활용되는 예시와 그 전망이 궁금합니다(챗봇, 문서 분류 등), NLP를 공부할 때 국문학적 지식이 많이 필요할까요?
- 검색, 고객응대용 챗봇
사람마다 생각이 다른 걸로, 처음이나 논문 이해할 때는 필요하지 않았다. 실제 논문을 쓰거나 문제 정의를 해야 하는데 언어학적으로 말이 되는 건지를 고민할 때 언어학적 지식이 필요했다.
음식점 리뷰를 분류할 때, 긍정적, 부정적 단어를 세고 어떤 게 더 많은 지 세는 건데, 이거만 가지고는 다루지 못하는 케이스들이 분명 있을 텐데, 언어학적 지식이 있었다면 사전에 체크하고 높일 수 있지 않았을까?
- 검색, 고객응대용 챗봇
- 멘토님의 강점
- 수학적 모델 이해 부족, 열심히 한다!! 열심히 하다 보면 되지 않을까란 생각을 가지고 산다.! 노력!!
- NLP의 매력
- 비전은 레드오션이 아닌가? 하는 생각이 들었고, 똑같은 문장이 있어도 어떻게 받아들이냐에 따라 다르지 않은가? 예를 들어 아이 러브 유, 아이 윌 러브 유, 아이 러브드 유, 굉장히 비슷한 문장이지만 해석이 굉장히 달라진다.
- Neuro Symbolic AI가 현업에 많이 사용되는가?
- 정리한 다음에 다시 답변드리겠습니다 ㅎㅎ.
- 멘토님에 대해 알고 싶습니다
- 참여 계기 : 부스트 캠프 친구가 1기 때 했었는데 재밌었다. 스스로 배우는 것도 많았고, 틈틈이 시간만 내면 좋다더라
취미 : 자전거, 롤
- 참여 계기 : 부스트 캠프 친구가 1기 때 했었는데 재밌었다. 스스로 배우는 것도 많았고, 틈틈이 시간만 내면 좋다더라
- 추천 자료
- 머신러닝 공부 중에 확률, 추정과 관련된 부분이 하면 어렵게 다가오는데요.
DALL·E: Creating Images from Text
We’ve trained a neural network called DALL·E that creates images from text captions for a wide range of concepts expressible in natural language.
openai.com
피어세션
Q1. 커널과 신호의 위치가 바뀌어도 된다고 적힌 이유가 element-wise 할 거라 상관이 없다는 의미로 해석해도 되나요?

A. convolution 연산이 교환 법칙을 만족하기 때문에, 위치가 바뀌어도 상관없다고 생각
그 후 검색 중 좋은 자료가 있어서 첨부해주심

Q2. 아래 equation이 왜 성립할까요? Xt과 X1부터.. X_t-1이 교집합이 없나요?

A. 저런 기호를 결합 확률이라 부르는데, 교집합과 비슷한 개념이라고 받아들여도 될 것 같다.

Q3. 시퀀스 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정해지는데.. activation function에 따라 다른지? 미분 값이 [0,1]인 tanh와 sigmoid는 괜찮고, relu인 경우만 불안정한 것은 아닌지?
A. 다들 정확히 알지는 못해서 질문 게시판에 올려보기로 함
Q4. 기울기 소실의 해결책이 왜 truncated 인지? 기울기 소실과 롱텀 디펜던시 하고 어떤 연관이 있는지?
A. 이 부분은 다음 주차에 RNN 공부하고 다시 논의해보기로 결정
다음주 스케줄을 정하기 위해 월요일 10시 미팅 (월요일 아침에 강의, 과제 overview 업로드되었을 시)
오피스 아워
Python & AI Math
- 윤태현, 박기훈, 이가람 멘토님
- 필수과제 해설
- 1,2,3번 해설
- 4,5번 캠퍼 풀이 공유
- 4,5번 해설
- 선택과제 접근 방향 안내
- 설문조사를 통해 난이도 체크
- 123번은 평이했지만 45번은 123번에 비해 어려웠던 것으로 판단
1번
- python 내장 함수를 써도 문제가 없지만, 나중에는 결국 numpy를 쓸 것 이기 때문에, numpy 내장함수를 알려주고자 출제
2번
- Join과 split은 익혀두면 좋다.
그다음으로는 캠퍼 분들의 4, 5번 발표가 이루어졌고, 200명 앞에서 자신의 코드를 소개한다는 게 쉬운 일이 아닌데 대단했다. 심지어 코드도 굉장히 잘 짜여 있어서 보고 배울 필요가 있겠다고 느낌.
그리고 split의 경우 default값이 ' '로 알고 있었는데 왜 split(' ')과 결과가 다른가?라는 질문을 해주셨는데 나도 생각지 못한 채 넘어간 부분이었다. 그렇게 찾아보니 Python document에 이런 내용이 기재되어 있었다. 지식이 1개 늘어남 👍

마지막으로는 선택 과제들에 대한 풀이가 이어졌는데 너무나도 어려웠다 😢
이렇게 첫 주 차의 마지막 포스팅이 마무리되었다. 포스팅할 내용이 정말 많았지만 쓰다 보니 요령이 생겨 점점 빠르고 조금 더 깔끔하게 정리할 수 있는 듯하다. 다음 주도 화이팅 :)
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week2_Day7. CV vs. NLP 선택의 기로 (0) | 2021.08.12 |
|---|---|
| [BoostCamp] Week2_Day6. 내가 원했던 수업 (0) | 2021.08.10 |
| [BoostCamp] Week1_Day5. 한 주의 마무리 (1) (0) | 2021.08.08 |
| [BoostCamp] Week1_Day4. 길잡이, 마스터와의 만남 (0) | 2021.08.06 |
| [BoostCamp] Week1_Day3. 예상치 못한 인연의 시작 (4) | 2021.08.05 |



