
호기심 많은 분석가
[BoostCamp] Week2_Day9. "Key"word. Transformer 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개요
정말 바쁜 하루가 아니었을까. 학습해야 할 내용은 많은데 여러 특강들이 겹치면서 시간이 부족했다. 처음 보는 내용들이 많다 보니까 짧은 강의도 학습하는 데 오래 걸리는 게 가장 큰 문제점이 아닐까 싶다. 특히 팀원들에게 발표하기 위해 준비를 하다 보니까 저번 주에는 그런갑다하고 넘어가던 부분을 조금 더 찾아보고 이해하려고 노력한달까? 피어 세션 때 수업 리뷰를 하는 것은 굉장히 좋은 선택이었다. 오늘은 그 유명하던 Transformer에 대해 설명 들었는데 굉장히 흥미로웠다. 역시 배우는 건 늘 짜릿해. 또한 오피스아워 시간에 멘토님께서 요즘 AI가 적용되는 사례들에 대한 영상들을 조금 보여주셨는데 이래서 데이터(AI) 다루지, 멋지다는 느낌을 한번 더 받아서 즐거운 나날들이다.
개인학습
(07강) Sequential Models - RNN
- 이제까지 배운 것은 이미지나 벡터에 관한 것이었다
- MLP는 vector → vector
- CNN은 image를 내가 원하는 형태로 바꿔주는 것
- Classification : image → one-hot vector
- Detection : image → bounding box
- Semantic segmentation : pixel별로 어떤 class에 속하는 지
- RNN은 주어지는 입력 자체가 sequential, 그래서 sequential model에 대해서 알아보자
Sequential Model
audio, video, motion 모두 sequential data, 그렇다면 sequential data를 처리함에 있어서 가장 큰 어려움이 무엇일까?
- 얻고 싶은 것은 하나의 label, 정보일 때가 많다. 근데 sequential data는 그 정의 상 길이가 언제 끝날 지를 모름. 그래서 내가 받아들여야 하는 입력의 차원을 알기 어렵다.
- 그래서 지금까지 배운 기술들을 사용할 수 없고, 몇 개의 입력이 들어오든 동작할 수 있는 모델이어야 한다.
- 가장 기본적인 sequential model, Naive sequence model
- language model, 이전 단어가 들어왔을 때 다음 단어를 예측해보자
- 뒤로 갈수록 내가 고려해야 할 conditioning data가 많아짐
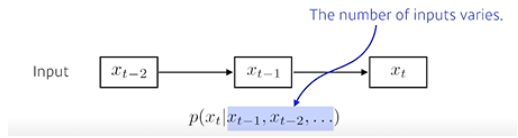
- 이걸 가장 쉽게 하기 위해서는 fix the past timespan, 과거의 몇 개만 본다.
- 이런 모델을 Autoregressive model이라고 부름
- AR1이라 하면 현재는 직전 과거 1개에만 depend 한다.
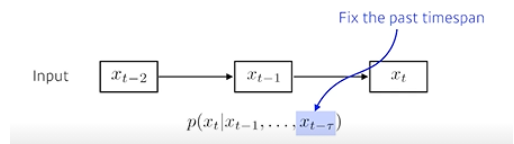
- 이 모델 중 가장 쉬운 모델이 Markov model (first-order autoregressive model)
- joint distribution을 표현하기 쉽다는 장점이 있지만, 사실은 말이 잘 안 되는 모델임
- 내일 수능 점수가 당장 오늘의 공부량만으로 결정되지는 않으므로..

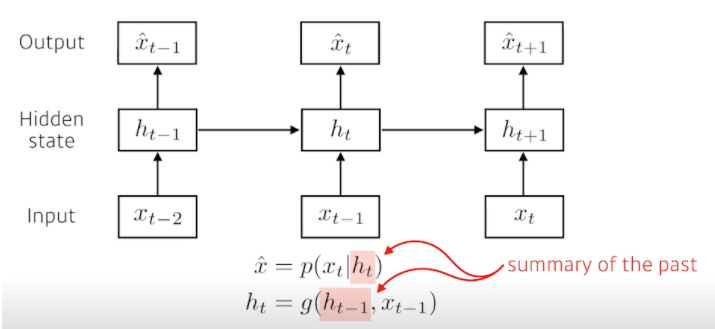
- Latent autoregressive model
- Markov의 가장 큰 문제는 과거의 수많은 정보들을 다 무시한다는 것
- 그래서 Latent는 과거의 정보를 hidden state에 요약해둠으로써 반영
- 내 다음 step은 이 hidden state 하나에만 depend 한 것
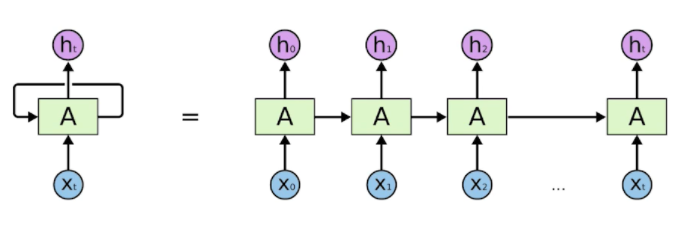
Recurrent Neural Network
- RNN을 시간 순으로 풀어둔 것
- 이게 입력이 굉장히 많은 fully connected layer 구성됐다고 볼 수 있다.
- RNN의 가장 큰, 어려운 단점, Long-term dependencies
- 과거의 얻어진 정보들이 취합돼서 미래에 그것을 고려해야 하는데 RNN 자체는 하나의 fixed 룰로 이 정보들을 계속 취합하기 때문에 과거의 있던 정보가 미래까지 살아남기가 힘들다.
- Ex) 우리의 문제가 문장이라면, 문장의 길이가 길더라도 다 기억해두다가 필요할 때 써야 하는데, 5초 이전의 정보는 다 잊어버린다면 성능이 제한적일 것이다.
- Short는 잘 잡는데 반해, Long-term은 기억하기 어려워한다.
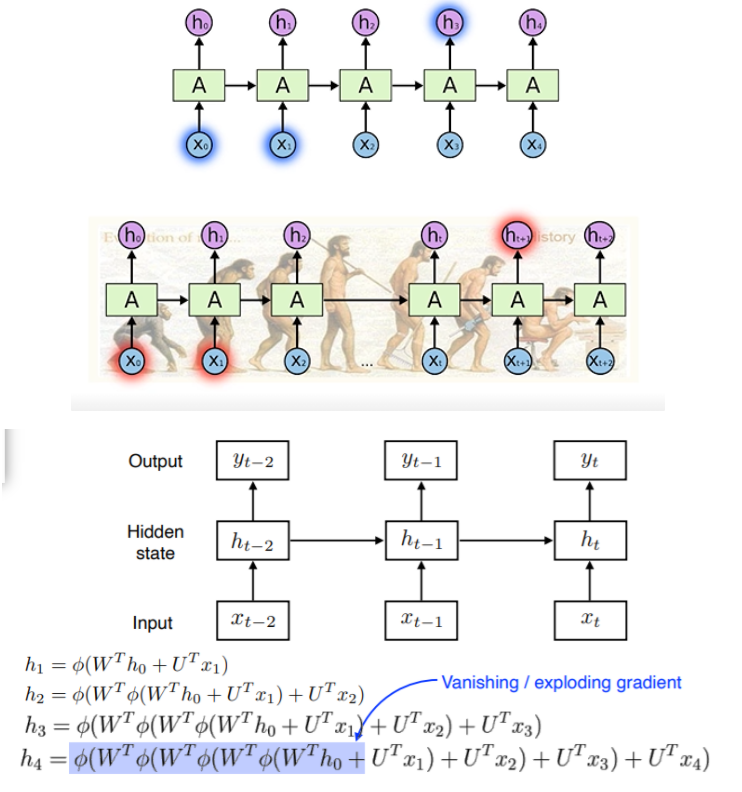
- 이러한 구조 때문에 $h_0$가 $h_4$까지 가는 동안 똑같은 weight와 nonlinear function을 거치게 됨
- nonlinear function, 즉 activation function이 sigmoid라 생각해보면 0-1 값 사이로 줄여버리니까 정보가 줄어들게 된다. 이것을 반복하면 의미 없는 정보가 될 것 (vanishing gradient)
- 만약 ReLU이고 h의 값이 양수라면? 계속 W가 곱해져서 너무 큰 값이 된다. (exploding gradient)
- 그래서 RNN을 할 때 ReLU를 잘 안 쓰고 학습이 어렵기도 하다.
Long Short Term Momory (LSTM)

- $X_t$ : Input, Ex) language model이라면 단어
- $h_t$ : Output (hidden state)
- Previous cell state : 내부에서만 흘러가고, time step t까지의 정보를 summarize해준 것
- Previous hidden state(output)
- LSTM의 Input : 이전의 출력 값(previous hidden state), previous cell state, $X_t$, 들어오는 것 3개, 나가는 것도 3개지만 실제로 밖으로 나가는 아웃풋은 $h_t$하나뿐
- sigmoid 3개, tanh 1개 있다. 하나하나 볼 것
뜯어서 설명해보자
- Core idea

- 중간에 흘러가는 cell state이다.
- Time step t까지의 정보를 summarize해준 것, 마치 컨베이어 벨트에 물건들이 올라와있고, 그 물건들의 정보를 조합해서 어떤 것이 유용하고, 그렇지 않은지를 가지고 다음번에 넘겨주는 것
- 어떤 걸 올리고 빼고 넘겨줄지를 결정하는 것이 바로 Gate, 문이다
- Gate는 총 3개로 이루어져 있다. Forget Gate, Input Gate, Output Gate
- Forget Gate : 현재의 입력 $x_t$와 이전의 아웃풋 $h_{t-1}$이 들어가서 $f_t$라는 숫자를 얻어내게 된다. sigmoid를 통과하기 때문에 항상 0에서 1 값 사이를 가짐
- 뒤에서 이 $f_t$가 이전의 cell state에서 나오는 그 정보 중에 어떤 것을 버리고 살릴지를 정하게 된다.
- Input Gate : 현재 어떤 입력이 들어왔을 때 어떤 정보를 올릴지 말지를 정함
- Update cell : 이전의 $C_{t-1}$에 어떤 것을 버릴지 $f_t$를 곱하고, $C_t$에 어느 값을 올릴지 $i_t$를 곱해서 더해줌으로써 새로운 cell state로 update 하는 것
- Output Gate : 그 값들에 sigmoid와 tanh 연산을 적절히 조합해줌으로써 출력 값을 뽑아내 준다
- Forget Gate : 현재의 입력 $x_t$와 이전의 아웃풋 $h_{t-1}$이 들어가서 $f_t$라는 숫자를 얻어내게 된다. sigmoid를 통과하기 때문에 항상 0에서 1 값 사이를 가짐

정리
이전까지의 정보를 현재 입력을 바탕으로 지울지, 새롭게 쓸지, 이 두 정보를 취합하는 게 update cell이고, 이 취합된 cell state를 한번 더 조합해서 어떤 값을 밖으로 빼낼지 정하는 게 Output Gate이다.
Gated Recurrent Unit (GRU)
- 일반적으로 우리가 tensorflow나 pytorch를 사용하게 되면 일반적으로 사용하게 되는 LSTM model류가 3가지이다. 1. Vanila RNN, 2. LSTM, 3. GRU
- LSTM과 다르게 Gate가 2개뿐이다.
- Simpler architecture with two gates (reset gate and update gate)
- No cell state, just hidden state → output gate가 필요 없어졌음

- LSTM에 비슷하며 단순해진 모델
- 생각보다 여러 Task에서 LSTM보다 GRU를 사용할 때 성능이 높아지는 경우를 종종 본다.
- 네트워크가 적은데 비슷한 Output을 출력하기 때문
- 하지만 최근엔 이 모든 것들이 잘 안 쓰인다. Transformer로 대체되는 중
정리
RNN이 가지는 단점이 Long Term Dependency를 잘 못 잡는다. → 그래서 LSTM이 등장했고, LSTM이 Gate가 3개 필요해서 파라미터가 많이 필요하니까 파라미터를 하나 줄인 게 → GRU, 그렇게 성능이 증가했다.
(08강) Sequential Models - Transformer
Sequential Model
- What makes sequential modeling a hard problem to handle?
- 기존의 sequence를 몇 개 생략하거나 밀리거나 순서가 조금 바뀌거나
- 이런 문제를 해결하고자 했던 것이 transformer인 것 같고, 기본적으로 self attension이라는 구조를 사용하게 됨
Transformer
Attention is All You Need, NIPS, 2017
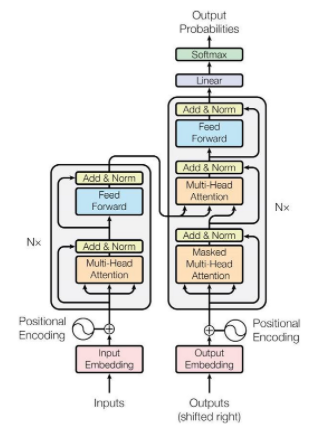
- Transformer is the first sequence transduction model based entirely on attention
- Transformer는 RNN과 같은 재귀적 형태가 없고 attention이라고 불리는 구조를 활용했다. → 이게 Key-Point!
- 원래 논문이 처음 시도되었던 NMT(기계어 번역) 문제에서 어떻게 적용되었는 지를 통해 설명하겠다.
- 이 방법론은 sequential 한 data를 처리하고, 이 data를 encoding 하는 방법이기 때문에 NMT 문제에만 적용되지가 않는다.
- 이미지 분류, 이미지 디텍션, DALL-E 등에서도 쓰이기에 이 방법론을 꼭 잘 알아두자
- From a bird`s-eye view, this is what the Transformer does for machine translation tasks

- If we glide down a little bit, this is what the Transformer does
- 불어 문장이 주어지면 영어 문장으로 출력하는, sequence to sequence model

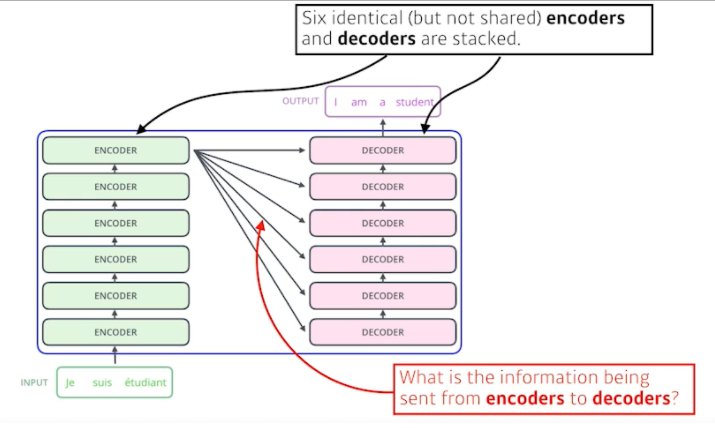
- 위 사진을 보면 입력은 3개의 단어, 출력은 4개의 단어로 이루어져 있음
- 입력과 출력의 개수가 다를 수 있다.
- 입력 sequence의 domain과 출력 sequence의 domain이 다를 수 있다.
- RNN은 3개의 단어를 넣으면 3번 재귀적으로 돌았겠지만, Transformer는 그렇지 않음. 100개를 넣어도 한 번에 encoding, 물론 generation 할 때는 한 개씩 Autoregressive 하게 만든다.
- Encoder부분, self-attention이라고 부르는 구조에서는 한 번에 n개의 단어를 처리할 수 있는 구조다.
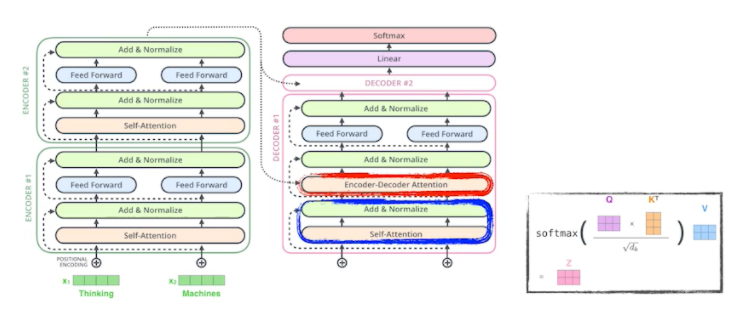
- 동일한 구조를 같지만, 네트워크와 파라미터가 다르게 학습되는 encoder와 decoder가 stack 되어있는 구조
이해해야 할 것
- N개의 단어가 어떻게 Encoder에서 한 번에 처리가 되는지
- encoder와 decoder 사이에 어떤 정보를 주고받는지
- decoder가 어떻게 generation 할 수 있는지
- 이것은 조금 덜 다룰 것 - 시간적 제약
- N개의 단어가 어떻게 Encoder에서 한 번에 처리가 되는지
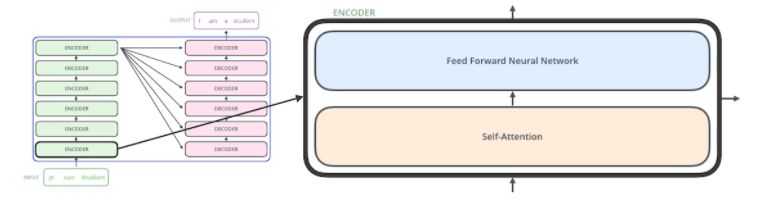
- 예전과 같이 이미지 1장이 들어가는 것이 아니라 N개의 단어가 입력된다.
- Self-Attention이라는 구조와 Feed Forward Neural Network, 2단을 거치는 게 하나의 Encoder이고 그 출력대로 나오는 N개의 출력 값이 2번째 Encoder에 들어가는 형식...
- The Self-Attention in both encoder and decoder is the cornerstone(주춧돌) of Transformer
- Self-Attention이라는 게 Transformer가 왜 잘 되는지 나타내 주는 것
- Feed Forward Neural Network은 MLP랑 똑같다.
- 우리가 NMT 문제를 푼다고 가정하고 3개의 단어만 들어온다고 두겠다.
- First, we represent each word with some embedding vectors
- 이 단어를 기계가 번역할 수 있게 하기 위해 각 단어마다 특정 숫자로 벡터화시킴
- 그렇다면 주어진 건 3개의 벡터
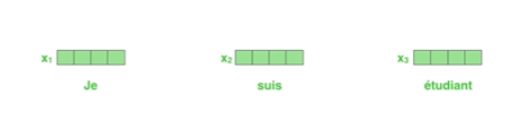
- Then, Transformer encodes each word to feature vectors with Self-Attention
- Transformer는 어떤 것을 해주냐, 정확히는 Self-Attention이 어떤 것을 해주냐?
- 3개의 단어가 주어지면 3개의 벡터를 다 찾아줌
- 여기서 중요한 것은 하나의 벡터 $x_1$이 $z_1$으로 넘어갈 때 단순히 $x_1$의 정보만 활용하는 것이 아니라 $x_2, x_3$정보를 같이 활용하는 것
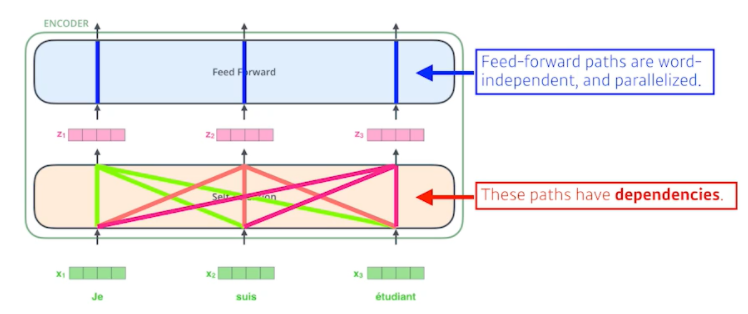
- Self-Attention at a high level
- The animal didn`t cross the street because it was too tired

- 이 문장을 이해하려면 뒤에 있는 it이 어떤 단어에 depend 하는 지를 알아야 함
- 하나의 문장에서 단어를 설명하려면 그 단어 자체로만 이해하는 것이 아니라 그 문장 자체에서 다른 단어들과 어떻게 interaction이 있는지 이해하는 것이 중요함
- Transformer가 어떤 것을 해주냐면 it이라는 단어를 encoding(표현)을 할 때 다른 단어와의 관계성을 보게 되고 특별히 학습된 결과를 보면 it이 animal과 굉장한 관계가 있다고 알아서 학습이 되는 것
- 이렇게 학습이 되었기 때문에 더 잘 단어를 표현할 수 있고 기계가 더 잘 이해할 수 있게 되는 것
- Suppose we are encoding two words :
- 좀 더 단순한 이해를 위해 2개의 단어만 주어졌다고 가정하겠다.
- Thinking and Machines
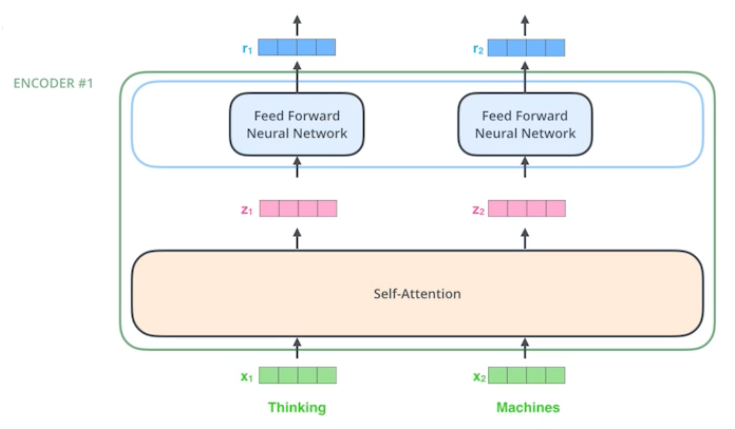
- 단어가 주어졌을 때 Self-Attention 구조는 3가지 벡터를 만들어내게 된다.
- 3가지 벡터를 만들어내는 건 3개의 Neural Network를 가지고 있다고 생각하면 됨
- 그 벡터가 바로 Query, Key, Value, Q, K, V이다.
- 이 3개의 벡터를 통해서 $x_1$이라는 첫 번째 단어에 대한 embedding vector를 새로운 벡터로 바꿔줄 것이다.

- Suppose we are encoding the first word : 'Thinking' given 'Thinking' and 'Machines'.
- Thinking과 Machines이라는 단어가 있을 때 Thinking이라는 단어를 Encoding 해줄 것
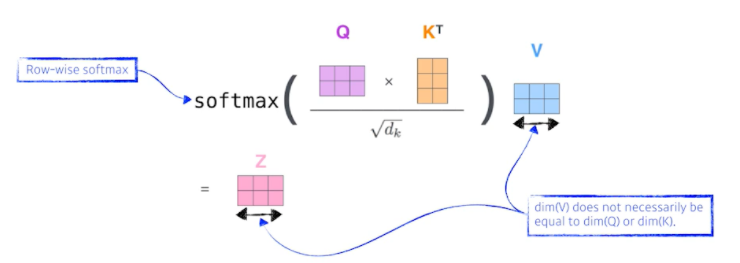
- 첫 번째는 score vector라는 것을 만들게 됨
- Score vector : i번째 단어에 대한 score vector를 계산할 때 내가 encoding 하고자 하는 query vector와 나머지 모든 n개에 대한 key vector를 내적 하는 것
- i번째 단어가 자기 자신 포함 나머지 n개의 단어와 얼마나 유사도가 있는지, 관계가 있는 지 정하게 된다. → 이것을 알아서 학습하게 되고, 이게 Attention이다. (누구와 연관 있는 지를 확인하게 되니까)
- 그리고 이것을 normalize 해줌 → 어떻게? key vector의 dimension에 루트를 씌워 나눠준다. key vector를 몇 차원으로 만들지는 hyper parameter임, 값이 너무 커지지 않게 만들어주는 과정
- 마지막으로 Softmax를 취해줌으로써 0과 1 사이 값으로 변환시켜준다. (Attention Rate)
- Score vector : i번째 단어에 대한 score vector를 계산할 때 내가 encoding 하고자 하는 query vector와 나머지 모든 n개에 대한 key vector를 내적 하는 것
- 결과적으로 Thinking이라는 단어가 자기 자신과의 interaction은 0.88이 되고, Machines라는 단어와의 interaction은 0.12가 된다.
- The final encoding is done by the weighted sum of the value vectors.
- 이 값은 scalar 값이므로 Values vector에 곱해줌으로써 Softmax X Value vector를 만들고 그것들의 합으로 최종적으로 Thinking이라는 embedding vector에 어떤 encoding 된 vector를 만들어준 것

- 여기서 주의해야 할 점
- 항상 query vector와 key vector는 차원이 같아야 한다. → 두 개를 내적 해야 하므로
- Value vector는 달라도 된다. weighted sum만 해주면 되니까
- 최종적으로 나오는 Thinking이라는 encoding 된 vector의 차원은 value vector의 차원과 동일하다 ← 이 세팅에서는 그럼
사실 이거 행렬로 계산하면 조금 더 간편함
- Calculating Q, K, and V from X in a matrix form.

- X가 의미하는 건 2x4, 단어가 2개 있음을 의미하고, 각 단어마다 4차원이라는 뜻
- Q, K, V를 찾아내는 $W^Q, W^K,W^v$라는 MLP가 하나 있다는 것
- 이 MLP는 encoding 된 단어마다 shared 된다.
- 최종적으로 2개의 단어가 주어졌으니까 2개의 Query vector, Key vector, Value vector가 나오게 된 것
- 그것들의 위의 계산 과정을 거치면 아래와 같이 embedding vector가 나오게 된다.
- 이게 왜 잘 될까? 이미지 하나가 주어졌다고 생각해보자
- 이것을 Convolutional Neural Network나 MLP으로 dimension을 바꾸면 input이 fix 되어 있으면 output이 고정됨
- Transformer는 하나의 input이 고정되어 있다고 하더라도 내가 보고자 하는 단어와 그 옆에 있는 단어에 따라 값이 달라지게 된다. MLP보다 조금 더 flexible 한 모델인 것
- 그래서 훨씬 더 많이 표현할 수 있는 게 Transformer 모델이다.
- 더 많은 걸 표현할 수 있기에 더 많은 competition이 필요하다.
- n개의 단어가 주어지면 기본적으로 NxN짜리 Attention-map을 만들어야 함
- RNN은 한 번에 처리해야 할 10000개의 sequence가 주어지면 10000번 돌리면(재귀적으로) 된다. 더 많이 주어져도 오래 걸릴 뿐 돌아는 간다.
- 그런데 Transformer는 10000개의 단어를 한 번에 처리해야 하고 10000*10000 matrix 계산을 해야 하기 때문에 length가 길어질수록 처리할 수 있는 한계가 명확해진다.
- 하지만 이런 단점이 있더라도 훨씬 더 flexible 하고 더 많은 걸 표현할 수 있는 네트워크를 만들 수 있다.
Multi-headed attention
- Multi-headed attention (MHA) allows Transformer to focus on different positions
- MHA는 앞에서 언급했던 attention을 여러 번 하는 것
- 하나의 embedding 된 vector에 대해서 query, key, value를 하나만 만드는 게 아니라 N개 만드는 것

- 이걸 N개의 Attention을 반복하게 되면, N개의 encoding 된 벡터가 나올 것
- 아래의 경우 하나의 embedding 된 vector가 있으면 8개의 encoding 된 vector가 나온다
- If eight heads are used, we end up getting eight different sets of encoded vectors ( attention heads)

- 고려해야 할 것은 encoding 된 것이 다음번으로 넘어가게 된다. 그것을 위해선 입력과 출력의 차원을 맞춰줘야 함
- 근데 위만 보더라도 8개의 vector가 나왔다. 한 개의 dimension이 10이라면 총 80 dimension이 되는 데 이것을 어떻게 해결할 수 있을까?
- We simply pass them through additional (learnable) linear map
- 80x10 matrix를 곱해서 10차원으로 줄여버린다

- 정리하자면 다음과 같다
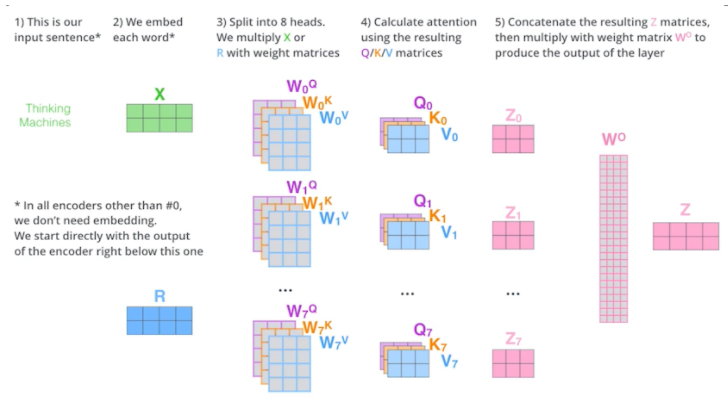
- 하지만 실제 구현체를 보면 이렇게 구현되어 있지는 않음
- 원래 내 embedding dimension이 100이었고, 10개의 head를 만들고 싶으면, 10개로 나눈다. Q, K, V를 만드는 건 10 dimension을 가지고 돌아간다.
- 자세한 설명은 코드를 보고 하겠다.
- 그다음은 positional encoding이라는 것이 추가됨
- 입력에 특정 값을 더해주는 것(bias)
- Why do we need positional encoding?
- Transformer 구조를 잘 생각해보면 우리가 n개의 단어를 sequential 하게 넣어줬다고 치지만 사실 sequential 한 정보가 포함되어 있지는 않음
- ABCDE를 넣어거나 BCDEA를 넣거나 각각의 Encoding 되는 값은 달라질 수가 없음
- 하지만 단어의 순서는 중요하다. 그래서 positional encoding 값을 더해준다.

- 그래서 positional encoding는 특정 방법으로 vector를 만들게 된다.
- This is the case for 4-dimensional encoding
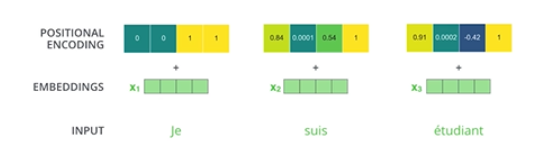
- 다음은 실제 논문에 사용된 512 dimensional encoding 값인데 각 i번째의 값에 i번째 값을 더해준 것

- 최근에는 다음과 같이 값이 바뀌었다고 함
- Recent (July, 2020) update on positional encoding
- 이 값들은 Predefined 방법, 미리 정해진 방법으로 만들어지지만 특정 값을 더해줌으로써 단어의 order를 부여하는 것

- Self-Attention으로 n개의 단어가 주어지면 n개의 encoding 된 vector가 나오고, 주의해야 할 점은 i번째 단어를 encoding 할 때는 나머지 모두의 정보를 활용해서 i번째 encoding vector를 찾는다.
- Encoding vector z가 나오면 Layer Normalization을 하고 그다음에 여러 가지 Feed Forward를 돌리고 그걸 계속 반복한다. Feed Forward란 독립적으로 동일한 NN을 동작하게 된다.
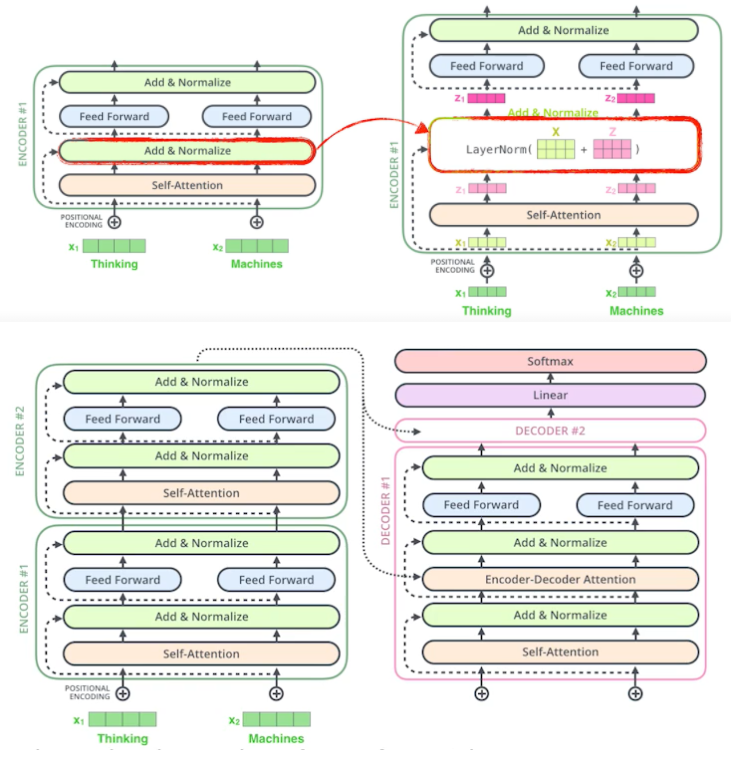
- 이제 Encoder는 우리가 어떤 단어를 표현하는 거였고, Decoder는 그걸 가지고 어떤 것을 생성해낸다. 중요한 점은 Encoder에서 Decoder로 어떤 정보가 전해지는지가 중요하다.
2. encoder와 decoder 사이에 어떤 정보를 주고받는지
- Transformer transfers key (K) and value (V) of the topmost(가장 높은) encoder to the decoder
- Transformer는 결국 Key와 Value를 보내게 됨
- 우리가 r번째 단어를 만들 때 r번째 단어의 query vector와 나머지 vector의 key vector를 곱해서 attention을 만들고, 거기 value vector를 weight sum을 한다.
- input에 있는 단어들을 decoder에 있는(출력하고자 하는 단어들에) 대해서 attention을 만들려면 input에 있는 단어들의 key vector와 value vector가 필요하고, 가장 상위 layer의 단어들을 만들게 된다.
- 그렇게 해서 decoder에 들어가는 단어들로 만들어주는 query vector와 encoder(입력)으로 주어진 단어들로 얻어지는 Key vector와 Value vector를 가지고 최종적인 값을 얻어내게 된다.
3. decoder가 어떻게 generation 할 수 있는지
- The output sequence is generated in an autoregressive manner.
- K, V 입력이 주어지면 그 값을 이용해서 I를 만들고, 그 정보를 이용해서 am을 만들고, 다시 I am을 이용해서 a를 만들고 최종적으로 I am a를 이용해서 student까지 생성해줌 (autoregressive)
- 그리고 마지막으로 end of sentence, eos라는 토큰이 나오면 종료
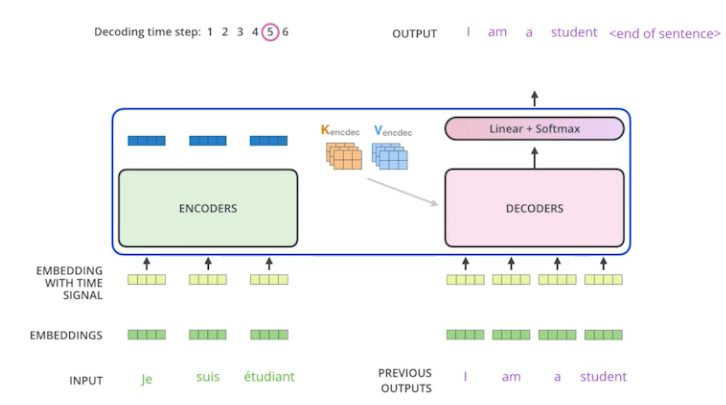
- In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step
- 학습 단계에서는 정답을 다 알게 되면 의미가 없으니까 이전 단어들만 dependent 하고 뒤에 단어들은 dependent하지 않게 만드는 마스킹이라는 것을 시행해줌
- The "Encoder-Decoder Attention" layer works just like multi-headed self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values from the encoder stack
- Encoder-Decoder Attention이라는 게 Encoder, Decoder 사이의 관계, 지금 decoder에 들어간 단어들만 가지고 query를 만들고, key, value는 encoder에서 나오는 값들을 이용한다.
- The final layer converts the stack of decoder outputs to the distribution over words.
- 마지막 layer는 단어들의 분포를 만들어서 그 단어들을 매번 sampling 하는 방식으로 돌아가게 된다.

Vision Transformer
- 지금까지 봐왔던 건 2017년도 논문이었고, NMP, 번역 문제에만 활용이 됐었는데 최근 들어서 Transformer, Self-Attention이라는 구조가 단어들의 sequence를 sequence로 바꾸는 것뿐만 아니라 이미지 domain에도 많이 사용하고 있다.
- VIT는 이미지 분류를 할 때 Encoder만 활용하게 되고, encoding 해서 나오는 첫 번째 encoded vector를 classifier에 집어넣게 됐다. 차이점은 문장이 있으면 단어들의 sequence가 주어지는 데, 그것을 이미지에 맞게 하려고 이미지를 특정 영역으로 나누고, 각 영역의 subpatch들을 어떤 linear layer를 통과시켜서 그 값을 마치 하나의 입력인 것처럼 다룬다. 물론 여기서도 positional encoding이 들어가게 된다. 왜? 구조 자체는 order invariant 하니까

DALL-E
- OpenAI에서 나온 네트워크 방법론은 문장이 주어지면 문장에 해당하는 이미지를 만들어 냄. 반대도 가능.
- 정말 엄청난 일이다.
- Transformer의 Decoder만 활용했다. 이미지도 16x16 grid로 나눠서 sequence로 transformer에 집어넣고, 문장도 역시 단어들의 sequence로 집어넣고 그것들을 조합해서 새로운 문장이 주어졌을 때 그 문장에 대한 이미지를 from scratch로 만드는 방법론을 제시했다. → GPT-3을 활용했다고 함

Further Reading
The Illustrated Transformer
저번 글에서 다뤘던 attention seq2seq 모델에 이어, attention 을 활용한 또 다른 모델인 Transformer 모델에 대해 얘기해보려 합니다. 2017 NIPS에서 Google이 소개했던 Transformer는 NLP 학계에서 정말 큰 주목을
nlpinkorean.github.io
Language Modeling with nn.Transformer and TorchText — PyTorch Tutorials 1.9.0+cu102 documentation
Note Click here to download the full example code Language Modeling with nn.Transformer and TorchText This is a tutorial on training a sequence-to-sequence model that uses the nn.Transformer module. The PyTorch 1.2 release includes a standard transformer m
pytorch.org
github특강2
- .git이 저장소를 의미함
- 나머지 장소들을 human이 work 하는 working directory라 함

- 동그라미를 head라고 함. head는 현재 working directory가 어느 버전인지 가리킨다.
- head를 바꾸면 버전을 바꿀 수 있다
- checkout을 사용해서 head를 변화시킬 수 있음
- 마스터는 마지막 버전이 어디였는지를 가리킨다.
- 시간 여행에서 돌아올 때는 마스터에서 체크아웃을 해줘라
- 실험을 하고 싶을 때는 Create Branch
- 실험이 성공해서 master에 합치고 싶을 때는 branch에서 merge into current branch
- 다 사용했으면 delete branch로 지워준다.

- 브랜치는 2가지의 장점이 있다
- 버리기 쉽다
- 병합하기 쉽다
- add remote를 통해 local repo를 remote repo로 올릴 수 있음
- 다음 내 깃 주소 입력하고 origin 입력하면 된다.
- 인증이 필요하면 내 OS의 password 입력
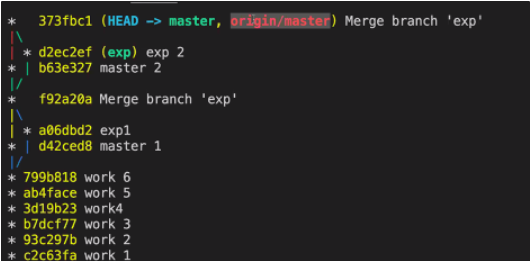
- git log —oneline
- 로컬저장소의 master와 원격저장소(origin/master)의 head가 다 373fbc1을 가리키고 있다.

- git log --oneline --graph --all
- conflict가 일어나면 VS code는 눌러서 고칠 수 있음
- 위에가 local, 아래가 원격 → 고친 후에 add 해줘야 함
피어세션
- 어제 강의 내용이 남아서 오늘의 발표도 내가 진행하게 되었다.
- 세션정리 : 조현동 캠퍼님
Q1. Skip connection의 의미가 잘 이해되지 않습니다.
A. x에 f를 씌워준 f(x)의 값은 convolution을 거듭할수록 값이 소실될 수 있습니다. 이것을 엄청 간단하게 x, 그 자체 값을 더해줌으로써 해결해준 것. 차이만 학습해주면 되니까 연산에는 큰 무리가 안 가면서 값은 유지해줌으로써 문제는 해결해준 것이다.
Q2. 작은 커널을 사용하는 게 큰 커널을 사용하는 것보다 적은 파라미터를 사용할 수 있다고 하는데, 그렇다면 2x2 커널을 사용하면 안 되나요?
A. 관습적으로 홀수 커널을 사용하게 되는데, 그 이유는 그 전 이미지 레이어 픽셀의 정보를 symmetrical(대칭적)으로 뽑을 수 있기 때문입니다. 아래 이미지처럼 홀수 커널은 중간의 output pixel 주위의 픽셀들을 elementwise multiplication과 sum을 통해 symmetrical 하게 뽑아 주변의 픽셀 정보를 그다음 레이어로 보내줍니다. 하지만 짝수의 경우에는 이렇게 주위에 있는 픽셀들을 대칭적으로 뽑을 수 없게 되고, 그 때문에 aliasing 같은 distortion이 생기게 됩니다.

Q3. Fully Convolutional Network가 input dimension에 independent 하다는 것이 어떤 의미인가?
A. input image의 size가 커지더라도 output의 image가 커질 뿐 모델에는 영향을 끼치지 못한다. 다음은 왜 FC layer가 존재하면 input size가 fixed 되는가에 대한 자료입니다.
Why must a CNN have a fixed input size?
Right now I'm studying Convolutional Neural Networks. Why must a CNN have a fixed input size? I know that it is possible to overcome this problem (with fully convolutional neural networks etc...), ...
datascience.stackexchange.com
Q4. Selective search는 어떤 방식으로 이루어지나요?
[객체 탐지] Selective Search for Object Recognition
[참고 자료] Paper : http://www.huppelen.nl/publications/selectiveSearchDraft.pdf [1] https://donghwa-kim.github.io/SelectiveSearch.html Selective Search for Object Recognition 방식은 R-CNN 계열의..
go-hard.tistory.com
Q5. RPN에 대한 추가 자료
RPN(Region Proposal Network) 정리
velog.io
오피스아워
- 선택과제에 대한 해설과 튜터분들의 공부 방식, AI가 실제로 사용되는 사례들과 악용사례들도 보여주셨다
- 다시금 내가 왜 AI를 선택했는지 알법한 흥미로운 영상들이 많았고, 음성변조 AI의 경우 보이스피싱으로 악용될 수 있는 여지가 너무 많아서 디펜스가 생기기 전까지 공개하지 않았다는 이야기를 듣고 놀랍기도 했다. 특히 프레디 머큐리가 한국 노래를 부르는 게 가장 인상 깊었다
- 딥러닝을 시작할 때 어떤 논문 위주로 시작하는 게 좋은가
- MLP → CNN (list 찾아보기) → NLP → RNN, LSTM, GRU → Transformer
→ RCNN → YOLO → Transformer
- MLP → CNN (list 찾아보기) → NLP → RNN, LSTM, GRU → Transformer
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Data_Viz_1. Data Visualization Introduction (0) | 2021.08.15 |
|---|---|
| [BoostCamp] Week2_Day10. 딥러닝의 기본을 알다. (0) | 2021.08.15 |
| [BoostCamp] Week2_Day8. 피어세션 때 발표를 하다. (0) | 2021.08.12 |
| [BoostCamp] Week2_Day7. CV vs. NLP 선택의 기로 (0) | 2021.08.12 |
| [BoostCamp] Week2_Day6. 내가 원했던 수업 (0) | 2021.08.10 |



