
호기심 많은 분석가
[BoostCamp] Week2_Day6. 내가 원했던 수업 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개요
오늘 수업은 정확히 내가 부스트 캠프에서 바라던 모습이랄까? 딥러닝에 대한 기초를 배웠는데 이때까지 제대로 모르고 사용하던 개념들에 대해 정확히 배웠다. 그래서 생각보다 짧은 강의에도 불구하고 시간이 많이 소요돼서 놀랐다. 고려대학교의 최성준 교수님께서 수업해주셨는데 정말 잘하시더라. 내가 듣다가 궁금할 법한 개념들은 꼭 집고 넘어가 주셔서 되게 좋았다. 이번 주 일주일 좀 힘들 것 같지만 파이팅해보자고..! 😏
굿모닝 세션
한 주의 시작을 함께하면서 학습량, 계획, 규칙 등을 가지는 시간을 가지기로 했고, 네이밍은 직관적으로 굿모닝 세션이라고 임의로 지었다. 😝
- 주말 안부 물어보고 인사 나눔
- 기본적으로 공지된 학습 일정을 따른다.
- 선택 과제는 각자, 필수 과제는 그 날 완료하고 다음날 코드 리뷰
- Special 강의인 Data Visualization은 일주일에 1번 올라옴
- 수목이 특강때문에 바쁘니까 월화에 걸쳐서 다 듣기로 함
개인 학습
(01강) 딥러닝 기본 용어 설명 - Historical Review
Introduction
- What make you a good deep learner
- Implementation Skills(구현 실력) - Tensorflow, Pytorch
- 머릿속으로 생각하고 아이디어를 가지고 있는 걸 실제로 돌려보고 결과를 뽑아볼 수 있는 실력
- Math Skills (Linear Algebra, Probability)
- Knowing a lot of recent Papers
- 최근의 트렌드, 논문을 아는 것도 중요하다. → 우리 수업에서는 딥러닝의 근간이 되는 논문들부터 다룰 것
- Implementation Skills(구현 실력) - Tensorflow, Pytorch
- 깊게 들어가기 보단 어떤 것이 있고, 더 깊게 찾아가기 위해선 어떻게 해야 하는지 포인터를 가르쳐줄 것이다.
- Artificial Inteligence - 인간의 지능을 모방하는 것
- Machine Learning - 데이터를 통해 학습하는 것
- Deep Learning - Neural Network 활용하여 학습하는 것
- Machine Learning - 데이터를 통해 학습하는 것

- Key Components of Deep Learning (딥러닝의 기본이 되는 요소)
- The data that the model can learn from
- Ex) 강아지와 고양이 이미지, 자연어의 경우는 위키피디아, 레딧의 말뭉치 비디오 - 유튜브 비디오
- The model how to transform the data
- Ex) 입력이 강아지고 출력이 이게 강아지인지 고양이인지 구분해주는 라벨
- 이미지를 라벨로 바꾸어주는 모델 : CNN, RNN, MLP, ...
- The loss function that quantifies the badness of the model
- Regression - L2norm(RMSE), Classification - Cross Entropy
- The algorithm to adjust the parameters to minimize the loss
- loss를 최소화하기 위한 알고리즘
- adam optimizer, stockchastic gradient descent
- 아래 링크에 adam optimizer에 대한 설명도 함께 있음
- loss를 최소화하기 위한 알고리즘
- The data that the model can learn from
- 왜 위의 4가지가 중요한가?
- 새로운 논문이 나왔을 때 이 4가지 관점에서 바라보면 이 논문이 어떤 장점이 있고, 어떤 Contribution이 있는지 알기 쉬움
Data
- Data depend on the type of the problem to solve.
- 데이터는 우리가 풀고자 하는 문제에 depend 하게 된다.
- 강아지와 고양이를 분류할 때는 이미지가 필요하다
- Semantic Segmentation은 이미지가 주어지면, 각 이미지의 픽셀 별로 어떤 플랫에 속하는지 확인하는 문제
- 이미지가 주어졌을 때 이 픽셀은 도로다, 사람이다, 하늘이다 등등...
- Dense Classification

- Detection이란 Semanic Segmentation이랑 비슷하지만 이미지 안의 물체가 있을 때, 그 물체에 대한 bounding box를 찾고 싶은 것. 그리고 그 영역에 어떤 물체가 있는지 찾는 문제다.
- Pose Estimation
- 이미지에 있는 사람의 3차원 스켈레톤 정보, 2차원 스켈레톤 정보
- 관절(key point -Head, Neck, Sholder, Elbow, Wrist, Hip Knee, Ankle 등)이 어떻게 구성되어 있는지 위치를 측정(Localization)하고 추정하는 문제
- 최근 연구는 이미지에선 2D, 비디오에서는 3D pose 생성에 초점
- Visual QnA
- 이미지가 주어지고, 질문이 주어졌을 때 그것에 대한 답을 구하는 문제

Model
- 이미지가 주어지거나 텍스트, 단어가 주어졌을 때 우리가 원하는 답으로 바꿔주는 것
- Ex) AlexNet, GoogleNet, ResNet, DenseNet, LSTM, Deep AutoEncoders, GAN

- 같은 데이터, 테스크가 주어졌더라도 모델의 성질에 따라서 결과가 확연히 달라질 수 있다.
- 그 결과를 잘 뱉어주게 할 테크닉들을 배울 것
Loss
- 모델이 정해져 있고, 데이터가 정해져 있을 때 모델을 어떻게 학습할지 정하는 것
- 우리는 딥러닝을 다룰 것이기 때문에 어떤 형태로는 NN형태를 가지게 될 것
- NN(Neural Network)라는 것은 weight와 bias로 이루어져 있음
- 그 weight의 parameter들을 어떻게 update를 할 지
- Loss function이라는 것은 우리가 이루고자 하는 것의 근사치에 불과하다.
- Loss가 줄어든다고 우리가 원하는 것이 이루어진다는 보장은 없다. 그 관계를 이해하는 게 굉장히 중요하다. 연관성이 높은 건 맞음.
- 예를 들어 노이즈가 많은 데이터, 즉 아웃라이어가 많은 데이터는 MSE가 굉장히 크게 나와서 학습이 잘 안된다. 그럴 때는 MSE 대신에 L1 norm이라던지, 나오는 다른 loss function을 제안하는 게 중요하다. 일반적으로 Regression에 MSE, Classification에 CE를 쓴다고 해서 반드시 그래야 하는 것은 아니다.
- 이것을 왜 사용해야 하고, 이것이 우리가 풀고자 하는 문제를 어떻게 풀어내는지 이해하는 것이 중요하다.
- Ex) Regression Task - MSE, RMSE Classification - CE(Cross Entropy) Probabilistic Task - MLE (Maximal Likelihood Estimation)

Optimization Algorithm
- 데이터, 모델, 손실함수가 정해져 있을 때 네트워크를 어떻게 줄일지에 대한 이야기
- 일반적으로 우리가 활용하는 Method는 First Order Method, NN의 parameter를 loss function을 1차 미분한 정보를 활용할 것
- 그 정보를 그냥 활용한 것이 Stockchastic Gradient Descent(SGD)인데 사실 여러 가지 이유 때문에 잘 작동을 안 한다.
- 그래서 이것을 변형한 Momentum, NAG, Adagrad 등과 같은 방법들이 사용되게 된다.
- 이 방법론들의 특성을 이해하는 것도 굉장히 중요함!!!
- Regularizer : 학습을 할 때 오히려 학습이 잘 안되게 해주는 방법론들을 추가하게 된다.
- Loss function을 단순히 줄이는 게 목적이 아니라, 이 모델이 학습하지 않은 데이터에서 잘 동작하는 것이 목적이기 때문에 다음과 같은 방법을 함께 사용한다.
- Dropout, Early Stopping, k-fold validation, Weight decay, Batch normalization, MixUp, Ensemble, Bayesian Optimization

- 일반적으로 우리가 활용하는 Method는 First Order Method, NN의 parameter를 loss function을 1차 미분한 정보를 활용할 것
Historical Review
- 1980년대에 등장한 딥러닝이 2012, 13년도에 주목을 받기 시작하고 어떻게 지금의 위상을 갖게 되었는지에 대한 것들을 알아보자
- Deep Learning`s Most Important Ideas - A Brief Historical Review - Denny Britz, 2020.07.29



(02강) 뉴럴 네트워크 - MLP (Multi-Layer Perceptron)
Neural Networks
- Neural networks are computing systems vaguely inspired by the biological neural networks the constitute animal brains. - 위키피디아
- 뉴럴 네트워크는 포유류의 뇌신경망에서 영향을 받은 컴퓨팅 시스템이다.
- 딥러닝이 인간의 뇌를 모방했기 때문에 잘 예측했다고 말하는 경우들이 종종 있는데, 꼭 그렇게까지 볼 필요는 없다 → 이런 의견들이 많음, 뇌신경망을 모방했다고 하면 일반 사람들이 받아들일 때 너무 신격화하는? 다른 세상이라고 생각할 수 있음
- 역전파가 인간의 뇌에서 이루어지진 않는다.
- 아래 그림과 같이 하늘을 날고 싶다고 해서 새처럼 날 필요는 없다.
- 마찬가지로 인간의 지능을 모방하고 싶다고 해서 뇌와 똑같을 필요는 없다.
- 날기 위해 처음엔 새를 모방한 것처럼 처음에는 신경망이 뇌를 모방하고 뉴런의 동작방법을 모방했을지 모르지만 지금의 딥러닝이 동작하는 방법과 트렌트가 인간의 뇌를 모방해서 잘 된다고 말하기엔 너무 많이 갈라졌다. 오늘날의 비행기처럼(F-22)
- 왜 잘 됐는지 모델을 놓고 수학적으로 이야기하는 게 더 옳다고 생각함

- Neural networks are function approximators that stack affine transformations followed by nonlinear transformations. - 수학적 정의
- 뉴럴 네트워크는 내가 정의한 함수를 근사하는 모델이다.
- 어떻게 동작하는? affine transformation : 행렬을 곱하는 nonlinear transformation : activation function이라 불리는 비선형 연산이 반복적으로 일어나는
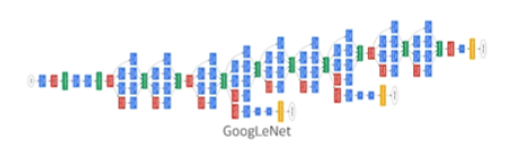
- GoogleNet을 예로 들면 Convolution이라고 불리는 linear 한 연산이 ReLU 같은 nonlinear tranformation을 거치는 Block들이 반복해서 이루어졌다.
Linear Neural Networks
- 가장 간단한 NN은 Linear function이다. (Linear Regression)
- 입력이 1차원, 출력이 1차원인 문제가 있을 때, 이 두 개를 연결하는 모델을 찾자.
- w라는 scalar, b라는 bias를 더함으로써 모델을 만든다.
- 딥러닝으로 가게 되면 w, b 둘만 있는 게 아니라 수십억 개를 parameter를 찾아야 할 수도 있다.

- We compute the partial derivatives w.r.t(with respect to) the optimization variables.
- 우리는 w, b를 찾기 위해 backpropagation을 사용할 것
- loss function을 줄이는 게 나의 목표
- loss function을 나의 parameter로 미분하게 되는 그 방향을 역수 방향으로(음수 방향)으로 parameter를 업데이트하게 되면 loss가 최소화되는 지점에 이른다.
- loss function을 parameter로 편미분 하고 특정 step size만큼 곱해서 빼주는 식으로 update 한다.

- 이런 식으로 w, b를 계속 업데이트해나가는 것을 gradient descent라고 함
- 우리의 데이터가 선형으로 예쁘지 않을 것이다. NN의 정의가 linear 한 변환에 nonlinear 변환도 섞여있기 때문, 딥러닝이기 때문에 한단만 있는 게 아니라 여러 층이 쌓인다. 최종단에서 나오는 loss function 값을 전체 parameter로 다 미분해야 하는 게 backprogation이고, 그 backprogation에서 나오는 파라미터 간의 편미분을 업데이트시키는 게 gradient descent가 된다.
- $\eta$(Stepsize)가 너무 크면 문제가 된다.
- 데이터는 local 한 정보기 때문, 그 근처에서만 유효하다.
- 그래서 Stepsize가 너무 크면 학습이 전혀 되지 않는다.
- 그래서 적절한 스텝 사이즈를 구하는 게 중요한 방법론임
- $\eta$(Stepsize)가 너무 크면 문제가 된다.

- 나의 parameter가 어느 방향으로 움직였을 때 줄어드는지 찾고, 그 방향으로 parameter를 바꿈
- 아래의 계산은 마지막에 -가 하나 없는 게 정상이지만, 역수 방향으로 계산해주기 때문에 -를 추가해준 것
- loss function을 줄이는 게 나의 목표

- Of course, we can handle multi dimensional input and output
- 세상이 선형으로만 이루어지지 않는다. N차원 입력에서 M차원 출력으로 가는 모델을 찾고 싶을 수도 있음
- 이때 행렬을 사용한다. ← 이 변환을 affine transform(linear transformation)이라고 하는 군
- 행렬을 찾는다는 건 두 개의 벡터 스페이스 간의 변환을 찾는다고 볼 수 있다.
- W라는 weight와 b라는 bias로 내가 x라는 입력을 y라는 출력으로 보내겠다.

Beyond Linear Neural Networks
- 딥러닝이라는 것은 결국 layer를 여러 개로 쌓겠다.
- 사실 다음과 같이 쌓으면(bias 무시) 한 단짜리 네트워크랑 다를 게 없음 (선형적이다)

- 그래서 우리는 Nonlinear transform이 필요한 것 - ReLU, tanh 같은 활성 함수
- x라는 입력에서 y라는 출력을 표현할 수 있는 표현력을 극대화하기 위해서는 선형 결합을 n번 반복하는 것이 아니라 그 중간에 활성 함수를 곱해서 nonlinear transformation을 거쳐서 더 많은 표현력을 같게 된다.

- Activation functions
- ReLU : 0보다 큰 값은 그대로 두고, 작은 값은 0으로
- Sigmoid : 항상 출력 값을 0과 1 사이로 제한하겠다
- tanh : 항상 출력 값을 -1과 1로 제한하겠다.
- 어떤 게 가장 좋을지는 문제마다, 상황마다 다르다.
- 하지만 Activation function을 통해 nonlinear transformation을 해줘야만 우리가 깊게 Network를 쌓은 게 의미가 있다.

- 딥러닝이 왜 잘 되는지에 대한 또 하나의 말이 있다.
- 히든 레이어가 하나 있는 뉴럴 네트워크는 대부분의 continuous and measurable 한 function들을 근사할 수 있다. 우리가 원하는 어떤 근사까지
- 히든 레이어가 하나 있는 뉴럴 네트워크는 우리가 생각할 수 있는 대부분의 함수를 다 표현한다.
- 하지만 이 말은 이런 뉴럴 네트워크가 존재한다는 거지, 내가 학습시킨 뉴럴 네트워크가 그렇다는 것은 아니다. 뉴럴 네트워크의 표현력이 굉장하지만, 얘를 어떻게 찾는지는 모른다. 그러니까 이 말도 조심해야 하는 말이다!!

- 히든 레이어가 하나 있는 뉴럴 네트워크는 대부분의 continuous and measurable 한 function들을 근사할 수 있다. 우리가 원하는 어떤 근사까지
Multi-layer perceptrons.
- This class of architectures are often called multi-layer perceptrons.
- What about the loss functions?
- MSE는 제곱의 평균을 내지만, 4 제곱, 절댓값도 가능하다
- 하지만 무조건 MSE를 맞추고자 아웃라이어도 fitting 하면 모델 전체가 망가진다.
- 항상 도움이 되지 않을 수도 있다.
- loss function이 어떤 성질을 가지고 있고 이게 왜 내가 원하는 결과를 얻을 수 있는지를 꼭 알아야 한다.
- 왜 CE(Cross Entropy)가 분류 문제에 도움이 되는가
- 딥러닝에서 Loss Function이 될 수 있는 조건
- 미분이 가능해야 한다. → GD 때문
- Full Batch GD의 Loss와 SGD의 Loss 합이 동일해야 한다.
- 일반적으로 분류 문제의 아웃풋은 원핫벡터로 표현이 된다.
- 내가 찾고 싶은 라벨이 10개면 10차원의 벡터가 출력된다. (0, 1, 0,..., 0)
- 내 NN의 출력 값 중에서 해당하는 클래스의 값만 높이겠다.
- 그 차원에 해당하는 출력 값을 키우는 게 우리의 목적
- 다른 9개의 값에 비해서 높기만 하면 됨. 절대적으로 높을 필요는 없음
- 그것을 수학적으로 표현하기 까다로우니까 CE를 사용하는 것
- 그렇다면 CE가 분류에서 최적이 맞나?
- https://theeluwin.postype.com/post/6080524
- 딥러닝에서 Loss Function이 될 수 있는 조건
- 확률적이나 불확실한 Task를 다룰 때 Probabilistic loss를 많이 사용하는 데 MLE가 대표적이다.
왜 크로스 엔트로피를 쓸까?
(본 글은 유투브 영상을 글로 재구성 한 것입니다.) 머신러닝/딥러닝을 하다보면 크로스 엔트로피(cross entropy)가 자주 등장합니다. 정확히는, 분류(classification) 문제를 풀 때 크로스 엔트로피를 이
theeluwin.postype.com
Multilayer Perceptron (MLP)
- 필수 과제를 수행하면서 알게 된 코드들에 대해 주석
import torch.nn as nn # neural network
import torch.optim as optim # optimization
import torch.nn.functional as F # functional
%config InlineBackend.figure_format='retina' # 화질이 좋아짐
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # GPU를 사용하면 cuda:0이 뜬다Data Iterator
- Torch에서는 Mini Batch Train, 즉 SGD를 하기 위해서, mini batch를 뜯어오는 dataloader를 생성
- shuffle을 True로 해줘야 iteration을 끝내고 다음 epoch으로 넘어갈 때 새롭게 shuffle 시켜줌
# shape이 (2, 784)
x_numpy = np.random.rand(2,784)
# 배치가 2개 있다고 가정하고, xdim 784일 때, 우리가 무언가를 PyTorch에서 돌리기 위해서는
# 우리가 사용하고 있는 device에 넣어줘야함 (CPU or GPU)
# torch.from_numpy <- numpy를 Torch tensor로 변환 후 float으로 변환 / 타입 때문 -> 그리고 device로 넘김
x_torch = torch.from_numpy(x_numpy).float().to(device)
# NN을 통과하고 반환 됨 / 현재 Torch tensor 상태, 신기한 건 forword를 쓰지 않아도 돌아감
# y_torch = M(x_torch) 이렇게 해도 돌아간다. 알아서 forword를 불러온다. 그래도 명시해주는게 가독성이 좋음
y_torch = M.forward(x_torch) # forward path
# 보기 위해선 다시 numpy tensor로 가져와야함
y_numpy = y_torch.detach().cpu().numpy() # torch tensor to numpy arrayCheck Parameters
- Parameter가 20만 개 나오는데 CNN보다 parameter 수가 많음
- AlexNet에서 봤던 것처럼 Dense layer를 정의하기 위한 parameter가 Convolution보다 훨씬 많기 때문
Evaluation Function
# no_grad() : gradient 계산하지 않겠다.
with torch.no_grad():
# model을 돌릴 때 dropout(학습할 때 노드를 몇 개 없는 셈치고 하는 것)이나
# batch_normalization(학습 중 정규화가 깨지는 경우가 있어서 이것을 해줘야함)과 같이
# 학습시에 무시했던 것을 평가할 때는 함께 봐줘야한다.
# training과 execution set이 달라져서 model change 해줘야함
model.eval() # evaluate (affects DropOut and BN)
# view는 reshape를 의미피어세션
Q1. 아래 수식에서 $log\mathcal N(y^{(d)}; y^{(d)},1)$을 어떻게 전개하고, MLE와 MSE가 왜 같은가요?

A. 우선 guassian distribution에서 mean과 std가 주어진 상황에서 input을 넣고, 거기에 log를 씌운 형태인데요. 여기에서 MSE와 같다고 표현한 이유는, 결국 식을 전개해놓고 보면 결국 우리가 원하는 MLE의 optimization 항이 mse loss optimization과 동일하게 나와서입니다. 좀 간략하게 설명드리자면 exponential 안 쪽의 (y_pred - y_label)^2 항을 제외한 부분은 상수 취급돼서 날아가기 때문입니다. https://www.jessicayung.com/mse-as-maximum-likelihood/
MSE as Maximum Likelihood
MSE is a commonly used error metric. But is it principly justified? In this post we show that minimising the mean-squared error (MSE) is not just something vaguely intuitive, but emerges from maximising the likelihood…
www.jessicayung.com
Q2. MLP 구현 코드에서 init_param() 함수에 parameter를 직접 입력해주려면 어떻게 해야 하는가?
A. 내부적으로 구현되어 있는 함수라 커스텀하기 어렵다 torch.nn.init.constant(tensor, val) method 이용하면 가능할 듯
Q3. MLP 코드의 Evaluation Function 파트에서 model.eval()은 왜 필요한가?
A. 현재 시점에서는 모델링 시 training과 inference 시에 다르게 동작하는 layer들이 존재한다. Dropout layer는 학습 시에는 동작해야 하지만, inference시에는 동작하지 않는 것과 같은 예시를 들 수 있다. BatchNorm 같은 경우도 마찬가지다
Pytorch에서 no_grad()와 eval()의 정확한 차이는 무엇일까?
Pytorch에서 no_grad()와 eval()의 정확한 차이는 무엇일까?
.
coffeedjimmy.github.io
Q4. 피어세션 때 모더레이터가 수업 리뷰를 해보자
A. 시도해보자, 그렇게 하면 모더레이터가 피어세션 정리하기 힘드니까, 그다음 순서가 정리하자.
Further Questions
Regression Task, Classification Task, Probabilistic Task의 Loss 함수(or 클래스)는 Pytorch에서 어떻게 구현이 되어있을까요?
torch.nn - PyTorch 1.9.0 documentation
torch.nn — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
정말 재밌는 강의들이었다. 내일부터는 조금 더 전문적인 내용들이 나오겠지...! 발표 준비 파이팅!!
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week2_Day8. 피어세션 때 발표를 하다. (0) | 2021.08.12 |
|---|---|
| [BoostCamp] Week2_Day7. CV vs. NLP 선택의 기로 (0) | 2021.08.12 |
| [BoostCamp] Week1_Day5. 한 주의 마무리 (2) (0) | 2021.08.09 |
| [BoostCamp] Week1_Day5. 한 주의 마무리 (1) (0) | 2021.08.08 |
| [BoostCamp] Week1_Day4. 길잡이, 마스터와의 만남 (0) | 2021.08.06 |



