
호기심 많은 분석가
[BoostCamp] Week2_Day7. CV vs. NLP 선택의 기로 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개인학습
(03강) Optimization
- 최적화에는 여러 가지 용어가 나온다. 이것들에 대해서 명확하게 집고 넘어가지 않으면 많은 오해가 생길 수 있다. 그래서 용어의 컨셉을 정확히 잡고 넘어가자
Gradient Descent
- W, b로 이루어진 Linear Function이 있을 때 그것의 loss function을 partial derivative 구해서 그걸로 파라미터를 step size를 곱해서 빼주는 것
- First-order iterative optimization algorithm for finding a local minimum of a differentiable function
- 1번 미분을 반복해서 local minimum을 찾는 최적화 알고리즘
Important Concepts in Optimization
- Generalization
- Under-fitting vs. Over-fitting
- Cross Validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
Generalization
- 많은 경우에 Generalization(일반화) 성능을 높이는게 우리의 목적
- 일반화 성능이 뭘까? 높이면 무조건 좋은걸까? 일반화의 의미를 알아보자
- How well the learned model will behave on unseen data
- Train을 거듭할 수록 training error는 줄어들지만 Test error는 그렇지 않다.
- Training error와 Test error의 차이를 Generalization performance라 한다.
- Generalization이 좋다는 의미는 네트워크의 성능이 학습 데이터와 비슷하다를 보장한다는 것
- Train error와 test error의 gap이 적다
- 하지만 애초에 학습 데이터의 퍼포먼스가 좋지 않다면 아무리 Generalization이 좋다 하더라도 네트워크의 성능이 좋지 않음

Underfitting vs. Overfitting
- Overfitting : 학습데이터에선 잘 동작하지만, 테스트 데이터에서는 잘 동작하지 않는 현상
- Underfitting : 네트워크가 너무 간단하거나 학습을 조금 시켜서 학습 데이터도 잘 못 맞추는 현상
- 그 중간 어딘가가 Balanced.

Cross-validataion
- Cross-validation is a model validation technique for assessing how the model will generalize to an independent (test) data set.
- 학습할 때 Train data와 Validation data를 나눠서 주는 현상
- 그럼 이거를 얼마의 비율로 나누는 게 좋을까?
- 그래서 이것을 해결하고자 하는 것이 Cross-validation(K-fold validation)

- NN으로 학습하는게 굉장히 많은 parameter가 존재, 이 중에서 내가 정하는 값들을 hyper parameter라 한다. - lr, loss function, 네트워크를 얼마나 크게 가져갈지
- 근데 이게 얼마나 해야 하는지 모르니까 Cross-validataion을 해서 최적의 hyper parameter set을 찾고 이 hyper parameter를 고정된 상태에서 모든 데이터를 다 사용해본다.
- Test data는 어떤 방식으로든 학습에 사용되면 안 된다.
Bias and Variance
- Variance : 어떤 비슷한 입력을 넣었을 때 출력이 얼마나 일관적이었나
- Bias : 데이터가 여기저기 분포되어 있더라도 평균을 냈을 때 어떤 주 타깃에 접근을 하면 그 자체로 bias가 낮다고 한다.
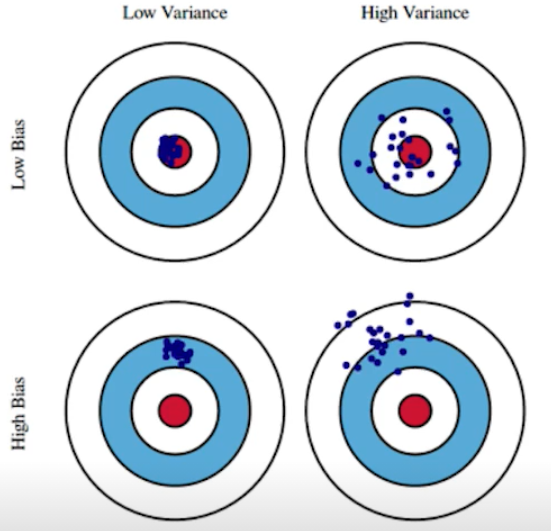
Bias and Variance Tradeoff
- 내 학습 데이터에 노이즈가 껴있다고 가정했을 때, 내가 이 노이즈가 껴있는 data cost를 minimize(L2 norm)하는 3가지로 나뉠 수 있다.
- 내가 minimize 하고자 하는 값은 3가지로 이루어져 있어서 하나가 줄어들면 하나가 커질 수밖에 없다.
- bias를 줄이면 variance가 커질 수 밖에 없다.
- 그래서 noise가 껴있으면 bias와 variance를 둘 다 줄이기 힘들다.
- We can derive that what we are minimizing (cost) can be decomposed into three different parts : ${bias}^2$, variance, and noise

Bootstrapping
- 신발끈을 의미, 신발끈을 들어서 하늘을 날겠다는 격어
- Bootstrapping is any test or metric that uses random sampling with replacement
- 100개의 데이터가 있으면 80개씩 뽑아서 여러 개의 모델을 생성
- 한 값에 대해서 각각의 모델들이 예측하는 consensus(일치)를 이루는 것을 보고, 전체적인 모델의 uncertant(불확실성)을 예측하고자 할 때 사용
Bagging vs. Boosting
- Bagging (Bootstrapping aggregating)
- Multiple models are being trained with bootstrapping
- Ex) Base classifier are fitted on ramdom subset where individual predictions are aggregated (voting or averaging)
- 여러 개의 모델을 random subsampling을 통해 만들고 그 모델들의 아웃풋을 평균을 내겠다. - Ensemble이라고 부르기도 함
- 배깅이 신기한 게 1개의 모델에 100개의 데이터를 넣고 돌리는 것보다 80개씩 여러 개의 독립적인 모델을 생성해서 여기에 voting을 하거나 averaging을 해서 돌리는 게 성능이 더 좋게 나옴
- Boosting
- It focuses on those specific training samples that are hard to classify
- A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
- 학습 데이터가 100개가 있으면 이것을 시퀀셜 하게 바라봐서 모델 하나를 만들고, 이 모델을 학습 데이터에 대해 돌려본다. → 80개 정도는 잘 맞추고 20개 정도를 못 맞춘다. → 20개 잘 안 되는 데이터에 대해서만 잘 되는 모델을 만든다. 이것들을 반복해서 합친다. 이런 하나하나의 연결되어 있는 모델을 weak learner라고 하는데, 이것들을 sequential 하게 합쳐서 strong model을 만듦

Practical Gradient Descent Methods
- Stochastic gradient descent
- Update with the gradient computed from a single sample
- 10만 개 데이터가 있으면 한 번에 한 개만 봐서 그레디언트를 구하고 업데이트, 그것을 엄청 많이 반복
- Mini-batch gradient descent
- Update with the gradient computed from a subset of data
- 전체 중에서 128개, 256개,.. 등등의 데이터를 뜯어서 그레디언트를 구하고 걔로 업데이트하고, 또 전체 중에서 batch-size만큼 뜯어서 반복..
- 대부분의 딥러닝에서는 이 방법을 사용한다.
- Batch gradient descent
- Update with the gradient computed from the whole data
- 한 번에 10만 개를 다 써서 그 10만개 모두의 그레디언트의 평균을 사용하겠다
Batch-size Matters
- It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize
- 배치 사이즈가 1개만 쓰면 너무 오래 걸리고, 한 번에 다 계산하면 GPU가 터져버려서 64개, 128개 등을 쓰는 것처럼 보일 수 있지만 그것보다 더 중요한 의미가 있다.
- We present numerical evidence that supports the view that large batch methods tend to converge to sharp minimizers of the training and testing functions. In contrast, small-batch methods consistently converge to flat minimizers... this is due to the inherent noise in the gradient estimation
- 배치 사이즈가 512, 1024, 혹은 만 개 등 큰 사이즈를 사용하게 되면 sharp minimizer라는 것에 도달한다. 이에 반해서 small size를 사용하게 되면 flat minimizer에 도달한다.
- sharp minimizer와 flat minimizer에 대한 설명은 없었지만 (논문 발췌 글임) flat minimizer가 더 좋다. 그래서 배치 사이즈를 작게 사용해야 한다.
- 아래 그림을 보면 flat minimum은 training function에서 조금 멀어져도 충분히 testing function에서도 낮은 값이다. 즉, training에서 잘 되면 test data에서도 잘 된다. → Generalization performance가 높은 것
- 그에 반해 sharp minimum은 그렇지가 못하다.
- 이 논문이 말하고자 했던 건 배치 사이즈를 줄이게 되면 일반적으로 generalization performance가 좋아진다라는 것을 실험적으로 보이고, 큰 배치 사이즈를 활용하려면 어떻게 해야 할지를 얘기한 논문
- 실험을 많이 하고 배울 점이 많은 논문임
- On Large-batch Training for Deep Learning: Generalization Gap and Sharp Minima, 2017

- 배치 사이즈가 512, 1024, 혹은 만 개 등 큰 사이즈를 사용하게 되면 sharp minimizer라는 것에 도달한다. 이에 반해서 small size를 사용하게 되면 flat minimizer에 도달한다.
Optimizer Select
우리는 어떤 Optimizer를 쓸지 정해야 한다. 그것들이 어떻게 쓰이는지 알아보자
Gradient Descent
얘의 가장 큰 문제는 Learning rate를 적절히 잡아주는 게 어려움

Momentum(관성)
그래서 이것을 발전시키고자, 더 좋은 성능, 더 빨리 학습을 시켜줄 수 있을까 해서 발달된 테크닉
- 이름처럼 우리가 한쪽으로 흐르던 그레디언트가 있으면, 다음번에 조금 다르게 흐르더라도 그 흐르던 정보를 최대한 활용해보자. 왜냐면 우린 Mini-Batch를 사용 중이니까
- $\beta$라고 불리는 hyper parameter가 들어감, 얘가 momentum을 잡게 되고 그것에 그레디언트를 포함한 accumulation으로 학습을 시켜줌

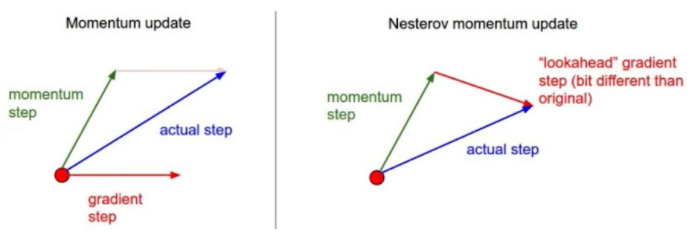
Nesterov Accelerated Gradient
- 원래 모멘텀은 현재 주어져 있는 파라미터에서 그레디언트를 계산해서 그것을 가지고 모멘텀을 어큐물레이션했다. 근데 얘는 a라는 현재 정보가 있으면 그 방향으로 한번 가보고, 그 간 곳에서 그레디언트를 가지고 어큐뮬레이션을 해줌

- 모멘텀을 관성이라고 봤을 때 local minimum을 뛰어넘어 갈 경우 관성 때문에 local minimum으로 converge 하기 어렵다. 그에 반해 NAG는 넘어간 후에 그레디언트를 계산하기 때문에 local minimum으로 converge 하기 더 쉽다.
Adagrad
- Agagrad adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters
- 뉴럴 네트워크의 파라미터가 얼마큼 지금까지 변해왔는지, 그리고 안 변해왔는지 보게 된다. 많이 변한 파라미터는 적게 변화시키고, 안 변한 파라미터는 많이 변화시키고 싶음
- 그러기 위해서는 이제까지 변한 파라미터에 대한 정보를 저장해야 한다. 그것이 바로 변수 G
- numerical stability는 0으로 나눠주지 않기 위한 값
- Adagrad의 가장 큰 문제는 $G_t$가 무한으로 가게 되면 분모가 계속 커지니까 결국 0이 되어서 W의 업데이트가 이루어지지 않을 것
- 뒤로 갈수록 학습이 멈춘다. 그걸 해결하고자 adam과 같은 방법론들이 제시되는 것

Adadelta
- Adadelta extends Adagrad to reduce its monotonically decreasing the learning rate by restricting the accumulation window
- Adadelta라는 것은 Adagrad의 $G_t$가 계속 커지는 현상을 최대한 막겠다.
- how? 현재 Time step t가 주어졌을 때, 시간에 대한 gradient 제곱에 대한 변화를 보겠다. 근데 window size를 100으로 잡게 되면 이전 100개 동안의 g라는 정보를 갖고 있어야 하는데 이 자체의 parameter가 크면 GPU가 못 버틴다.
- 그래서 이때 Exponential Moving Average를 통해 $G_t$를 업데이트함으로써 해결
- Adadelta의 가장 큰 특징은 learning rate가 없다는 것이다. 그래서 우리가 바꿀 수 있는 게 많지 않고 자주 쓰이지 않는다.

RMSprop
- RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture
- 논문을 통해 제안된 것이 아니라 제프리 힌턴이 강의를 하다가 사용해보더니 좋다고 알림으로써 퍼짐
- Stepsize를 추가해준 것

Adam
- Adaptive Moment Estimation (Adam) leverages both past gradients and squared gradients
- 그레디언트와 그레디언트 square의 크기에 따라서 learning rate를 바꾸는 것과 이전의 그레디언트의 정보에 해당하는 모멘텀을 잘 합친 게 Adam이다.
- 모멘텀, EMA정보, learning rate, $\epsilon$, 4가지의 hyper parameter가 있고 이것을 적절히 조정하는 것도 중요하다.
- $\epsilon$이 $10^{-7}$으로 default 되어 있는 데 이것을 바꿔주는 것도 중요함
- 모멘텀, EMA정보, learning rate, $\epsilon$, 4가지의 hyper parameter가 있고 이것을 적절히 조정하는 것도 중요하다.

- 이 관계들을 더 알아보기 위해 다음의 사이트를 소개한다.

Gradient Descent Optimization Algorithms 정리
Gradient Descent Optimization Algorithms 정리
Neural network의 weight을 조절하는 과정에는 보통 ‘Gradient Descent’ 라는 방법을 사용한다. 이는 네트워크의 parameter들을 $\theta$라고 했을 때, 네트워크에서 내놓는 결과값과 실제 결과값 사이의 차이
shuuki4.github.io
GitHub - LiyuanLucasLiu/RAdam: On the Variance of the Adaptive Learning Rate and Beyond
GitHub - LiyuanLucasLiu/RAdam: On the Variance of the Adaptive Learning Rate and Beyond
On the Variance of the Adaptive Learning Rate and Beyond - GitHub - LiyuanLucasLiu/RAdam: On the Variance of the Adaptive Learning Rate and Beyond
github.com
GitHub - clovaai/AdamP: AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights (ICLR 2021)
AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights (ICLR 2021) - GitHub - clovaai/AdamP: AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant...
github.com
Regularization
학습에 반대되도록 규제를 걸어서 Generalization을 잘 되게 하고 싶음
아래의 것들은 내가 가진 도구라고 생각하면 된다. NN에 넣었을 때 결과가 좋으면 사용하면 되는 것
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
Early Stopping
- Test data가 아닌 Validation data를 구해서 Error가 커지는 순간 전에 일찍 멈춤

Parameter Norm Penalty
- NN parameter가 너무 커지지 않게 하는 것
- Parameter들을 다 제곱해서 더한 그 숫자를 줄인 것
- 이왕이면 네트워크를 학습할 때 그 숫자들이 작으면 작을수록 좋다
- 부드러운 함수일수록 Generalization performance가 좋을 거다라고 가정하고 부드러운 함수를 만들어주는 것
- 데이터가 한쪽으로 치우쳐지지 않게 만들어준다.

Data Augmentation
- NN, DL, ML에서 가장 중요한 것이 Data이다. 데이터가 무한히 많으면 웬만하면 다 잘 된다.
- 데이터가 적으면 전통적인 ML 방식이 더 성능이 좋다. 하지만 데이터가 많아질수록 그 데이터를 표현할 수 있는 표현력이 부족해지게 된다. 근데 딥러닝은 파라미터의 수가 많다 or Universal Approximation Theorem 등 여러 이유 때문에 그 많은 데이터를 표현할 수 있는 능력이 된다.

- 문제는 뭐냐? 데이터는 한정적이다. 만들어낼 수가 없으니까, 그래서 Augmentation을 하는 것
- More data are always welcomed
- However, in most cases, training data are given in advance
- In such cases, we need data augmentation
- 강아지를 돌리고 늘이고 줄여도 강아지다. label preserving augmentation이라 하는데 변환을 해도 라벨이 변하지 않는 이미지를 augmentation이라고 한다.
- 예를 들면 6은 뒤집으면 9가 되므로 라벨이 바뀐다. 이런 경우만 아니면 됨

Noise Rebustness
- 왜 잘 되는지는 아직도 의문이 있다.
- 입력 데이터에 노이즈를 집어넣는 것, data augmentation과 비슷하지만 다른 점은 weight를 학습시킬 때도 사용한다.
- 인풋 및 웨이트 훈련 시에 노이즈를 집어넣어 주면 실험적으로 좋은 결과를 보이더라

Label Smoothing
- Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data
- data augmentation이랑 비슷한데 차이점을 굳이 말하자면, 데이터 2개를 뽑아서 이 두 개를 섞어주는 것이다.
- 분류 문제에서 내 이미지들이 살고 있는 공간 속에서 decision boundary를 찾고자 하는 것
- 얘를 가지고 분류가 잘 되게 하는 것이 목적
- 이 Decision boundary를 부드럽게 만들어준다.

- 어떻게 동작하는가
- CutMix constructs augmented training examples by mixing inputs with cut and paste and outputs with soft labels of two randomly selected training data
- 이미지를 2개 골라서 이미지도 섞고, 라벨도 섞는다
- CutMix는 이미지를 섞어줄 때 blending 하게 섞는 것이 아니라 이미지의 특정 영역에는 고양이를 집어넣고 다른 영역에는 강아지를 집어넣는다
- 왜 잘 되는지를 설명하기보다 이 방법들을 사용하면 일반적으로 성능이 올라간다.
- 생각보다 많이 올라간다고 하심
- 코드도 간단해서 많은 시간이 걸리지도 않음

- CutMix : Regularization Strategy to Train Strong Classifiers with Localizable Features, 2019
Dropout
- In each forward pass, randomly set some neurons to zero.
- 뉴럴 네트워크의 일부 weight를 0으로 바꾸는 것
- Dropout ratio(p)가 0.5라면 학습할 때 50%의 뉴런의 weight를 0으로 만들어줌
- 각각의 뉴런들이 로버스트 한 피처가 잡을 수 있다.

Batch Normalization
- Batch normalization compute the empirical mean and variance independently for each dimension (layers) and normalize.
- NN의 각각의 레이어를 정규화시켜줌

- There are different variance of normalizations
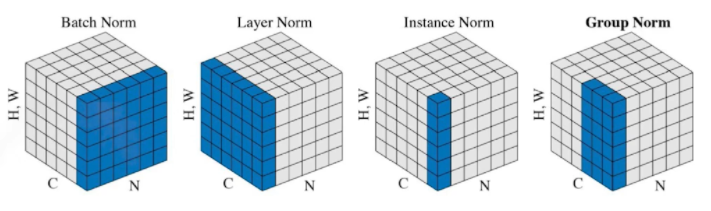
정리
Regularization이 왜 잘 되는지를 설명하는 데 집중하기보다 좋은 Tool들을 가지고 있으니까 이 방법들을 적용해보면서 좋은 성능을 보이는 것을 실험적으로 사용하자
도메인 특강
CV 도메인 특강
Upstage AI Engineer 박선규님

- Taskonomy ( CVPR 2018 best paper )
- 굉장히 많은 Task가 있다, 연구분야가 굉장히 넓고 다양함

- 이미지 속의 물체를 인식하는 데 시작한 CV가 컴퓨터 그래픽에서 노이즈를 줄이는 데도 사용함 → 이미지를 만드는 데 드는 비용을 획기적으로 줄일 수 있음
- 다른 분야의 CV로 가더라도 크게 어렵지 않게 작업할 수 있다.
- Convolution기반 모델이 굉장히 자주 쓰였는데, 요즘은 Vision Transformer라는 것을 사용하고자 한다.
- 이미지도 단어처럼 해석함으로써 높은 성능을 보임 (NLP에서 자주 쓰이던 모델)
- Convolution기반 모델이 굉장히 자주 쓰였는데, 요즘은 Vision Transformer라는 것을 사용하고자 한다.
Conclusion
- CV라 함은 이미지와 같은 시각 정보에 포함되는 것들을 다루는 기계 학습
- 이미지, 이미지가 들어가서 텍스트가 나온다던지
- 생각보다 다양한 테스크를 포함하는 방대한 분야
- 자신이 흥미를 느끼는 파트를 찾아보자
- Convolution, CNN에 대해서 깊게 배우게 될 것인데 앞으로도 상당한 기간 동안 유용하게 쓰일 것이다
NLP 도메인 특강
Upstage AI Engineer 서대원님
- 언어학, CS, AI의 subfield
- 사람의 언어로 쓰인 document를 이해하는 데 목적이 있다.
NLP Applications are Everywhere
- Search
- 정확히 일치하는 단어가 없더라도 연관된 문서를 보여줌
- Voice Assistant
- 현재는 다양한 pipeline들이 결합되어 있는 상태
- Translation
- 번역을 통해 데이터를 늘릴 수 있다. 한국어 문서를 영어로 번역했다가 다시 한국어로 변환시켜줌으로써
- Trend1. Large Scale model
- 암기력이 좋고 똑똑한 아이한테 도서관 가서 책을 모두 읽히는 격
- Trend2. Retrieval-based Model
- 질문이 주어졌을 때 관련된 document를 찾고, 그 안에서 답을 찾는 방법 DPR
- Trend3. Multimodality
- 자연어로 사진에 대한 설명이 들어가면 이미지를 생성 DALL-E
ML Engineers Implement ML Systems
- CNN, RNN, Transformer 내용 이해, 새로운 논문 구현 능력 → 성능 업그레이드
- Model Serving을 위한 능력
- CS 지식 기본기 탄탄히 하고, ML 지식의 기본기도 탄탄히

Q&A
- 이 분야 일을 하면서 가장 보람 있었던 순간, 왜 그 분야를 선택하게 되었는가?
- 선규님 : 무료 폰트들에서 한글 글자를 뽑아서 MNIST처럼 만들어서 분류 모델을 만들어보자. 이 계기로 시작하게 되었음.
- 대원님 : 사회의 불평등을 해소하고 싶다. 기술로 가능하다고 생각했다. 커피숍에서 나이가 있으신 분들은 서서 주문을 하고 어린 분들은 스마트폰으로 앉아서 주문하는 걸 보고 정보격차다. 그래서 음성으로 주문을 하게 만들고 싶었다. NLP를 하다 보니까 Multimodality에 관심을 가지고 있다.
- 분야의 바이블 같은 책 같은 것이 있는가?
- 선규님 : 책의 형태의 데이터들은 너무 늦는 게 아닌가 싶다. 너무 빠르게 발전하기 때문
http://nlp.seas.harvard.edu/2018/04/03/attention.html
대원님 : Attension is All you need라는 논문을 여러 번 읽어보는 것을 추천, Transformer의 시조 - https://github.com/KimDaeUng/PLM-Implementation/tree/main/01_Vanilla-Transformer
- 이미 경험해본 분야와 이제 막 관심이 생기는 분야 중 어떤 선택이 취업에 유리한가?
- 선규님 : 깊이 파는 것, 다양한 분야를 접해보는 것, 다 장점이 될 수 있다.
- 대원님 : CV, NLP 둘 다 굉장히 유망한 분야라고 생각한다. 더 재밌는 거 고르는 걸 추천
CS, 자료구조, 알고리즘 지식 탄탄하게 쌓아두자
- 각 분야에서 중요하게 봐야 할 점은?
- 대원님 : KLUE를 하면서 어떤 Task가 있는지 파악, 언어 모델에 대한 이해, 어떤 언어 모델이 어떤 분야에서 잘 되는지 중점적으로 생각
선규님 : CV에서는 각 Task마다 엔지니어링적인 요소가 들어가는 것이 있다. 네트워크 자체가 어떤 식으로 학습되는 지를 알아두면 좋다.
- NLP의 경우 각 언어마다 모델링을 하거나 할 때 많은 차이가 있는가? CV와 NLP의 기술의 차이가 클까?
- 대원님 : 있긴 하다. 한국어의 경우 토큰부터 분리하고... → 하지만 트렌드는 점점 언어 Dependency가 없어지는 방향으로 가고 있음
- 기존 인력 대비 차별점을 가지려면 어떠한 스킬들을 개발하면 좋은가?
- 선규님 : 개인적인 생각으로는 인력이 포화상태가 되어있지 않음. 기본기만 탄탄해도 뽑기 좋은데, 차별점을 가지려면 한 가지 테스크를 깊게 파봤다. 아니면 여러 가지 테스크를 넓게 파봤다.

- 지극히 옳은 방법들, 그대로 정진하시면 될 것
피어세션
- 오늘은 주영님이 수업해주시고 내가 피어세션 정리를 함
Q1. Cross-validation을 하는 이유가 적합한 hyper parameter를 찾기 위해서만 사용하는가?
A. 그렇다
Q2. Noise가 없는 Data는 bias와 variance를 둘 다 줄일 수 있는가?
A. Noise는 데이터 자체로 가지는 값이고, bias와 variance를 둘 다 줄일 수는 없다. 그것이 Trade-off
Q3. Boosting의 Sequential의 Model들은 다 다른 Model들인가?
A. 다 다른 모델로 알고 있다... 요것도 조금 더 찾아보자...
Q4. Small Batch는 왜 flat minimum에 수렴하고, large batch는 왜 Sharp minimum에 수렴하는가
A. 실험적으로 그렇게 된 것으로 판단한다. batch_size가 작아지면서 sharp 한 value들을 피할 수 있는 확률이 높아지지 않을까?
Q5. 모멘텀에서 $\beta$의 의미?
A. 이전 결과를 얼마나 유지를 할지? 관성의 정도
Q6. Parameter Norm Penalty에서 Total cost의 가중치에 l1norm이나 l2norm을 더해주는 꼴로 생성되는데, 왜 파라미터의 절댓값 크기가 작은 게 일반화 성능에 도움이 되는가?
A. 데이터셋이 한쪽에 치우쳐있는 것을 줄여줌으로써 일반화에 도움을 준다.
Q7. Weight에 noise를 추가하는 기법은 뭐가 있을까?
A. 요것도 찾아보는 걸로
마스터클래스
Data Literacy & Data Visualization
- 데이터 시대의 필수 역량, 데이터 시각화
안수빈님
- 서울대학교 Human-Comper Interaction 석박통합과정
- Kaggle Notebooks Grandmaster
Contributor
- 누구에게 기여할 것인가?
- 개발과 연구는 혼자 하는 게 아니다. 개인은 시간과 능력에 한계가 존재한다.
- (좋은 집단으로 가면) 코딩을 잘하는 개발자는 많다.
- 순위와 실력은 유지하기 어렵다.
- 지속 가능한 개발자란 Expert를 support 하고, 대다수의 beginner를 끌어줄 수 있어야 한다.
- 내 분야에 대한 실력은 기본, 함께하고 싶은 개발자가 되어야 한다.
Awesome Developer
- 이 모든 것을 적절히 표현하기 위해 데이터 시각화를 시작했다.
Data Literacy
- 데이터 리터러시는 데이터를 건전한 목적과 윤리적인 방법으로 사용한다는 전제하에, 현실 세상의 문제에 대한 끊임없는 탐구를 통해 질문하고 답하는 능력
데이터 시각화
- 데이터를 필요에 맞게 시각적 요소로 변환하여 이해하기 쉽게 시각적으로 전달
- Data Manipulataion & Encoding
- Goal & Target Audience
- Prevent Misleading
- Observation & Aesthetic
Data Science에서 Visualization을 하는 이유
- 시각화를 하는 과정에서 데이터를 살피며 데이터에서 인사이트 얻기
- Dashboard 등의 시각화는 단순 정보를 시각화하고, 사용자는 탐색하며 인사이트 획득
- 결과를 효과적으로 보여주기
- 데이터 중심 커뮤니케이션을 위해서는 단순히 정보만으로는 불가능
- 설득의 핵심은 이성 + 감성 + 신뢰! 이성과 감성을 자극하자
Data Visualization 종류
- Information Visualization
- 기존 데이터의 통계치 등의 정보를 시각적으로 전달
- Scientific Visualization
- 이미지, 오디오, 3D 객체 등의 객체 관찰 또는 시물레이션을 효좌적으로 살피기 위한 시각화
- Infographic
- 전달하고자 하는 메시지를 데이터를 통한 스토리텔링으로 전달
- Data Art
- 데이터를 사용하여 예술적으로 표현
AI에서 Data Visualization이 중요한 이유
결국 AI를 사용하는 것은 사람!
- 데이터를 사용한 설득
- 의료, 경제 등 실질적 손실이 가는 분야일수록 신뢰가 필요
- 기계가 하는 걸 어떻게 믿어요? 와 사람이 하는 걸 어떻게 믿어요의 커넥션
- Metric에 따라 높은 Score를 가지면 좋은 AI Model일까?
- 기본적인 성능과 안정성은 필수
- 그다음은 Product이고, 그때부터는 UX!! (사용자 경험)
- 제한적인 환경(논문, 서비스 등)에서 최대한으로 보여줄 수 있어야 한다.
- 시각화는 UX의 다양한 고려점 중 하나이자 좋은 연습 도구
Fred Hohman
Fred Hohman is a Research Scientist at Apple creating interactive interfaces and data visualization for machine learning.
fredhohman.com
데이터셋 탐색 도구 : Facet
인터랙티브 논문 및 Article : Distill
방법론을 알자
Data Viz Project | Collection of data visualizations to get inspired and finding the right type.
Collection of data visualizations to get inspired and finding the right type.
datavizproject.com
인지적 관점

- wandb 기억하자
- 캐글을 하다 보니 1-10등까지는 another class였지만 그 밑으로는 0.1점씩 밖에 차이가 안 났다. 그게 앞으로 내가 만들 product에 얼마나 큰 영향이 있을까 해서, 그렇다면 그걸 더 잘 표현할 수 있을까 하여 시각화를 공부하게 되었다.
CV와 NLP 중 하나를 골라야 할 때가 다가오고 있다. CV만큼 여기에서 배우기에 좋은 게 어딨나 싶어 고민되기도 하고, 요즘은 NLP를 기본적으로 다룰 줄 알아야 구직에 유리할 것 같아서 고민이 된다. 사실 둘 다 너무 재밌어서 더 재밌는 거로 결정해라 하기에는 조금 어려운 부분이다.
오늘 들은 Optimization 부분은 꽤 충격적이었다. 27분짜리 강의를 모르는 개념들 다 찾아가면서 정리하다 보니 3시간을 훌쩍 넘겼다. 그만큼 새로운 것을 많이 알게 되었고, 기본적으로 알고 있었어야 할 개념들을 너무 모르고 있었다란 생각이 든다. 배우는 게 참 즐거워..!
캐글 코리아 단톡방에 있으면서 안수빈님을 참 자주 뵀었는데 여기서 마스터로 만나 뵈니까 반가웠다. DM도 보냈는데 친절히 답변해줘서 영광인 기분.. 마스터 클래스를 들으면서 참 열심히 사신 분이라는 느낌을 받았고, 마지막 시각화를 시작하게 된 계기가 너무 공감 갔고 대단했다. 저 생각이 들면서 저런 식으로 행동 실천이 되는구나를 봤고, Data Viz 강의를 얼른 듣고 싶다.
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week2_Day9. "Key"word. Transformer (0) | 2021.08.14 |
|---|---|
| [BoostCamp] Week2_Day8. 피어세션 때 발표를 하다. (0) | 2021.08.12 |
| [BoostCamp] Week2_Day6. 내가 원했던 수업 (0) | 2021.08.10 |
| [BoostCamp] Week1_Day5. 한 주의 마무리 (2) (0) | 2021.08.09 |
| [BoostCamp] Week1_Day5. 한 주의 마무리 (1) (0) | 2021.08.08 |



