
호기심 많은 분석가
[BoostCamp] Week1_Day5. 한 주의 마무리 (1) 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개요
폭풍 같았던 일주일이 지나갔다. 첫 주는 프리코스 때 들었던 강의만 다시 다뤘던 것이라 내용이 굉장히 많았던 것이고 다음 주부터는 그렇지 않을 것이라 하신다. 하지만 본격적으로 어려운 내용이 다음 주부터 시작이니 조금은 겁이 난다. 아직 첫 주차 내용도 완벽히 이해가지는 않았는데 지속적으로 학습하며 부족한 부분들을 마스터님이나 다른 멘토분들이 추천해주신 사이트를 통해 공부해나가야겠다.
개인 학습
(AI Math 9강) CNN 첫걸음
Convolution 연산 이해하기
- 지금까지 배운 다층 신경망(MLP)은 각 뉴런들이 선형 모델과 활성 함수로 모두 연결된(fully connected) 구조였습니다.
- 주어진 입력 벡터에 대해서 가중치 행렬 W의 행렬곱으로 히든 Variable(잠재 변수)에 해당하는 component를 계산할 수가 있다.
- 문제는 다층신경망의 경우에는 각 성분 $h_i$에 해당하는 가중치 행들이 각각의 i번째 위치마다 필요하다. ← 다층 신경망에서 사용되는 fully connected의 구조의 특징
- 만일 i가 바뀌게 되면 사용하는 가중치도 바뀌어서 구조가 커지게 된다.
- 그래서 학습시켜야하는 parameter의 수가 커지게 된다.

Convolution 연산 이해하기
- Convolution 연산은 이와 달라 커널(kernel)을 입력 벡터 상에서 움직여가면서 선형 모델과 합성함수가 적용되는 구조이다.
- 커널이라는 고정(i에 따라 변하지 않음)된 가중치 행렬을 사용
- i가 변하게 되면 활성화 함수와 커널을 제외하고 Convolution 연산이 x, 입력 벡터 위에서 움직이면서 적용한다 ← MLP와 다름, 이것도 선형 변환에 속한다.
- 모든 i에 대해 적용되는 커널은 V로 같고 커널의 사이즈만큼 x 상에서 이동하면서 적용한다.

- i의 갯수와 상관없이 커널 사이즈가 고정된 상태로 적용되기 때문에 parameter 사이즈를 굉장히 많이 줄일 수 있다.
- Convolution 연산의 수학적인 의미는 신호(signal)를 커널을 이용해 국소적으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것이다.
- Convolution을 수식으로만 이해하는 것은 매우 어렵다.
- x라는 입력에 대해서 전체 정의역에서 f와 g를 z를 움직여가면서 적분하거나 더해주면서 Convolution 연산 시행
- x-z 또는 i-a텀이 들어가 있는 함수를 신호, z나 a만 들어있는 term이 커널

- 엄밀히 말하자면 CNN은 -가 아닌 +를 사용하기 때문에 convolution이 아니라 cross-correlation이라고 부른다.
- 하지만 전체적으로는 +든 -든 상관없기 때문에 범용적으로 convolution이라고 불러왔던 것
- 컴퓨터에 적용할 때는 이것이 중요하므로 엄밀히는 cross-correlation이지만 역사적으로는 convolution이라고 불린다는 사실을 유의해두자

- 커널은 정의역 내에서 움직여도 변하지 않고(translation invariant) 주어진 신호에 국소적(local)으로 적용합니다.
- 파란색의 원래 시그널에 해당했던 함수를 검은색으로 변환시켜서 정보를 확산시키거나 추출하거나 감소시키거나한 연산을 Convolution이 수행한다.

영상처리에서 Convolution
- 다양한 종류의 커널에 따라서 경계선이라던지, 주변 선의 모양이라던지, 노이즈 제거라든지 여러 가지 효과를 사용할 수 있다. → 그래서 Convolution 연산을 영상처리에서 많이 사용하는 것

- Convolution 연산은 1차원뿐만 아니라 다양한 차원에서 계산 가능하다.
- 2D는 2개의 위치(i, j)에 대해 동시에 움직이면서 적용,..
- 데이터의 성격에 따라 사용하는 커널이 달라진다.
- 음성이나 텍스트는 1 dimension-convolution을 주로 사용하고, 흑백 영상은 2D, 컬러 영상은 3D, 형태에 따라 Convolution이 달라짐을 확인할 수 있다.
- 중요한 것은 차원이 높아진다 하더라도(i, j, k가 바뀌어도) 커널$f$의 값은 바뀌지 않는다.

2차원 Convolution 연산 이해하기
우리가 보통 연산에서 CNN을 많이 사용할 텐데, 그때 2차원은 굉장히 많이 사용되는 연산이기 때문에 조심스럽게 살펴봐야 한다.
- 2D-Conv 연산은 이와 달리 커널(kernel)을 입력 벡터 상에서 움직여(x, y 방향으로 1칸씩) 가면서 선형 모델과 함성 함수가 적용되는 구조이다.
- Convolution의 위치에 해당하는 p와 q에 따라서 i, j가 고정된 상태에서 p와 q를 움직여가면서 계산하는 방법이다.
- 2차원 kernel이 0123으로 주어져있는데 입력에 주어진 데이터에 커널의 크기만큼 계산하는 건 1차원에서의 계산과 똑같다.
- $f(p, q)$가 커널 0123을 의미, p와 q가 1, 2번째 위치에 해당한다.
- 1을 행, 2를 열로 계산하는 느낌
- p와 q가 각각 1과 2 값을 가질 수 있기 때문에 (1,1), (1,2), (2,1), (2,2)에 해당하는 게 커널의 위치 좌표이고 p, q에 변화에 따라서 입력 좌표에 i와 j를 넣어주게 되면 그것이 바로 우리가 계산하는 Convolution 연산에 해당한다.
- p와 q가 각각 1과 2 값을 가질 수 있기 때문에 (1,1), (1,2), (2,1), (2,2)에 해당하는 게 커널의 위치 좌표
- 0123 커널의 크기에 맞춰서 입력 언산 0134를 해주면, 행렬 연산이 아니라 element-wise 곱, 즉 성분곱을 해서 더해주는 연산을 해서 더해주게 됨. (첫 번째 연산)
- 이제 한 칸씩 움직이면서 계산해주면 됨.
- 한 칸 우측으로 이동해서 계산해주면 커널은 동일하고, 1245 연산을 해줘서 25가 나오게 됨

- 입력 크기를 (H, W) 커널 크기를 $(K_H, K_W)$, 출력 크기를 $(O_H, O_W)$라 하면 출력 크기는 다음과 같이 계산합니다.
- 이렇게 입력과 커널의 크기를 알면 출력의 크기를 유추할 수 있고, 이걸 통해서 다음 Convolution 연산에서 사용할 수 있고, 최종적으로 결과물을 미리 예측할 수 있다.
- 위에도 입력이 3X3의 경우, 커널의 2X2인 경우 출력이 2X2 임을 확인할 수 있다.

- 채널이 여러 개인 2차원 입력의 경우(2차원 이미지지만 마치 3차원 데이터를 다루는 듯한, 예를 들면 RGB), 2차원 Convolution을 채널 개수만큼 적용한다고 생각하면 된다.
- 3차원부터는 행렬이 아닌 텐서라고 부른다.
- 채널이 여러 개인 경우 커널의 채널 수와 입력의 채널 수가 같아야 한다.
- 각각의 채널 개수만큼 2차원 입력들을 분리를 한 상태에서 각각의 채널 갯수만큼 커널들을 만든 다음에, 각각의 2차원 입력에 커널들을 적용한 후에 그 결과물들을 더해줘서 2차원 Convolution을 수행한다.

- 채널이 여러개인 2차원 입력의 경우 2차원 Convolution을 채널 개수만큼 적용한다고 생각하면 된다. 텐서를 직육면체 블록으로 이해하면 좀 더 이해하기 쉽다.
- 입력과 커널의 높이(채널 개수)가 C로 같음을 확인할 수 있고 결과적으로는 모든 결과물들을 합하므로 1개로 도출되는 것을 확인
- 2차원이 여러 개니까 3차원으로 표현

- 출력이 여러 개의 채널로 나오게 하고 싶다면 어떻게 해야 하는가?
- 간단하다. 커널을 여러 개 연산해주면 된다.
- 커널을 $O_C$개 사용하면 출력도 텐서가 된다.
- 이게 바로 오늘날 2D, image에서 사용되는 CNN 연산에서 사용되는 Convolution operator, CNN 연산의 기본적인 Form이다.
- 이것은 기본적인 Convolution 연산이고, 이렇게 해야만 하는 것은 아니다. 굉장히 많은 변형들이 있기 때문에 그것들의 CNN을 이해하려면 각각의 방법들을 개별적으로 이해해야 하지만 기본적으로 우리가 사용하는 CNN convolution의 정의는 이런 식으로 Input 채널과 Output 채널의 커널 개수를 조절해줌으로써 출력 커널의 개수를 조절할 수 있다.

Convolution 연산의 역전파 이해하기
- convolution 연산은 커널이 모든 입력 데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution 연산이 나오게 된다.
- 아래 그림 참조. g에 프라임만 붙어있을 뿐 같은 convoltion 연산임
- convolution 연산도 linear operator(선형 변환) 인건 마찬가지라서 MLP의 역전파 계산 방법이랑 동일하다.
- Discrete일 때도 마찬가지로 성립한다.

- 그림으로 이해해보자
- 입력 차원은 5, 커널 차원은 3, 그래서 5-3+1인 3이 출력 차원
- 화살표 색깔로 커널 와 입력의 계산을 확인할 수 있다.

- Backpropagation 단계에서 지켜보자.
- Convolution 연산 수행 후에 loss function(손실 함수)에서 손실 값(error)을 계산한 후에 backpropagation이 뒤에서 점차 오게 되면서 출력 벡터에 해당되는 벡터에서는 $\delta_1, \delta_2, \delta_3$라는 미분 값이 각각 출력 벡터 위치에 전달이 된다.
- 그러면 이 역전파 방식에서 $\delta_1, \delta_2, \delta_3$라는 그레디언트 벡터들이 어떤 식으로 X3와 커널에 전달되는지 살펴보자
- 아까 Convolution 단계에서 01, 02, 03에 가중치 벡터로 $w_3, w_2, w_1$이 사용됐다. 적용이 될 때 가중치에 따라서 그레디언트 벡터에 연결되는 가중치를 대응되는 가중치로 사용을 한다.
- 역전파 단계에서 다시 커널을 통해 그레디언트가 전달된다.

- 그렇다면 각각의 커널들에는 어떤 그레디언트들이 전달되게 될까?
- 커널에는 $\delta$에 입력값 $x_3$을 곱해서 전달한다.
- 똑같이 03가 X3에 대해서 W1을 통해서 전달됐기 때문에, 그레디언트도 $\delta_3$에 X3가 곱해져서 W1으로 전달된다.

- 결국 전체를 계산해보면 각 커널에 들어오는 모든 그레디언트를 더하면 결국 convolution 연산과 같다.

(AI Math 10강) RNN 첫걸음
- RNN(Recurrent Neural Network)은 이전 시간에 배운 CNN과 다르게 시계열 데이터, 시퀀스 데이터에 적용이 되는 기법이다. 시계열은 i.i.d(독립 항등 분포) 데이터들과 달리 독립적으로 들어오지 않는 경우가 상당히 많다.
- 그런 데이터에서 어떻게 모델을 설계하고, 어떻게 학습하는지 배울 예정
- RNN은 모델 자체에 대한 설계는 어렵지 않지만, 왜 이렇게 설계하는지에 대해 알아야 함
시퀀스 데이터 이해하기
- 소리, 문자열, 주가 등의 데이터를 시퀀스(sequence) 데이터로 분류합니다.
- 순차적으로 들어오는 데이터
- 시계열(time-series) 데이터는 시간 순서에 따라 나열된 데이터로 시퀀스 데이터에 속한다.
- 문자열 데이터의 경우에는 인위적으로 나열하는 것이 아니라 문법, 문맥, 단어의 사용 같은 문장을 쓸 때 앞에서의 의도도 중요하기 때문에 시퀀스로 분류한다.
- 시퀀스 데이터는 독립 동등 분포(i.i.d.) 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률 분포도 바뀌게 된다.
- 과거 정보 또는 앞뒤 맥락 없이 미래를 예측하거나 문장을 완성하는 건 불가능하다.
- Ex) 개가 사람을 물었다와 사람이 개를 물었다는 데이터의 빈도도 다르고 의미도 확연히 차이가 남
시퀀스 데이터를 어떻게 다루나요?
- 이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부 확률을 이용할 수 있습니다.
- 이전에 배운 베이즈 법칙을 사용한다.
- $\prod$ : Product,

- 이 수식이 어떻게 성립하는 걸까?
- 결합 확률로서 다음과 같은 경의를 가지고 있기 때문에 수식 성립 → 교집합과 비슷하다고 받아들이면 편하다.

- 결합 확률로서 다음과 같은 경의를 가지고 있기 때문에 수식 성립 → 교집합과 비슷하다고 받아들이면 편하다.
- 유의해야 할 게 아래 조건부 확률은 과거의 모든 정보를 사용하는 것처럼 디자인됐지만 실제로 시퀀스 데이터를 분석할 때 모든 과거 정보들이 필요한 것은 아니다
- $X_{t-1}부터\ X_1$까지의 정보가 조건부로 주어진 상황에서, 현재 정보인 $X_t$를 모델링하는 이 조건부 확률분포를 다루는 게 시퀀스 데이터를 다루는 기본적이 방법론에 속한다.

- 시퀀스 데이터를 다루기 위해선 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요합니다.
- $X_t$일 때는 t-1개의 데이터, $X_{t+1}$일 때는 t개의 데이터처럼 데이터의 길이가 변하기 때문에, 이걸 다룰 수 있는 모델이 필요하다.

- 앞에서 언급했다시피 과거의 모든 정보를 사용할 필요는 없다. 그래서 최근의 고정된 길이(몇 년) $\tau$ 만큼의 시퀀스만 사용하는 경우 AR($\tau$) (Autoregressive Model) 자기 회귀모델이라고 부른다.

- 하지만 이 $\tau$ 같은 경우는 hyper parameter, 즉 우리가 사전에 정해줘야 하는 변수기 때문에 이것을 정해주는 작업도 사전 지식(도메인)이 필요하다.
- 이 경우에 어떻게 모델링을 해야 할지 고민될 텐데 그 경우에 사용하게 될 것이 오늘 배울 RNN의 기본 모형인 Latent Autoregressive Model(잠재 자기 회귀 모델)이다.
- 바로 직전 과거의 정보와 그 전의 과거들을 따로 모아서 직전 정보는 $X_{t-1}$로 묶고 그 이전 정보들은 $H_t$라고 잠재 변수로 인코딩을 한다.
- 2가지의 정보만 가지고 미래 시점을 예측할 수 있기 때문에 길이가 가변적이지 않고 고정되어 있어, 과거의 모든 데이터를 이용하여 예측할 수도 있고 또한 가변적인 문제도 해결할 수 있기 때문에 여러 장점을 가지고 있다.
- 여기서의 문제는 무엇일까?
- 과거 정보들의 잠재 변수를 어떻게 인코딩할지가 선택의 문제다.
- 이 문제를 해결하기 위해 등장한 것이 RNN이다.

- 직전 과거의 변수와 이전 잠재 변수를 가지고 현재 잠재 변수를 예측해내는 모델이 오늘 배우게 될 시퀀스 데이터를 학습할 수 있게 설계된 RNN이다.

Recurrent Neural Network을 이해하기
- 가장 기본적인 RNN 모형은 MLP와 유사한 모양입니다.
- 그래서 그전에 앞서 MLP를 다시 복기해보자
- $W^{(1)}, W^{(2)}$은 시퀀스와 상관없이 불변인 행렬입니다.
- 이 모델로는 과거의 정보를 다룰 수 없다.
- 입력 행렬이 T번째만 들어오기 때문에 현재 시점만 들어오는 것
- 그래서 기본적인 MLP는 과거 변수를 담을 수 없다.
- 어떻게 하면 $H_t$에 담을 수 있을까?

- RNN은 이전 순서의 잠재 변수와 현재의 입력을 활용하여 모델링합니다.
- $H_t$ term을 표현할 때 새로운 가중치 행렬이 등장함
- 입력으로부터 전달되는 $W_x$ 가중치 행렬과 이전 잠재 벡터 변수로부터 정보를 전달받게 되는 $W_H$라는 새로운 가중치 행렬을 만들게 됨
- t번째 잠재 변수는 현재 들어온 입력 벡터인 $X_t$와 이전 시점의 잠재 변수인 $H_{t-1}$을 받아서 만들어 주는 것
- 이 잠재 변수를 이용해서 현재 시점의 출력인 $O_t$를 만들어 내는 것
- 잠재 변수인 $H_t$를 복제해서 다음 순서의 잠재 변수를 인코딩하는 데 사용합니다.
- 명심할 점은 3개의 W 가중치 행렬은 t에 따라서 변하지 않는 행렬이다.
- 그래서 t시점에 상관없이 동일하게 모델링이 수행된다.
- t에 따라서 변하는 것은 잠재 변수와 입력이다.

- RNN의 역전 파는 잠재 변수의 연결 그래프에 따라 순차적으로 계산합니다.
- $X_1부터\ X_t$까지 모든 시점에서의 예측이 전부 이뤄진 다음에 맨 마지막 시점에서의 그레디언트가 타고 타고 와서 과거까지 그레디언트가 흐른다.
- 이것을 Backpropagation Through Time(BPTT)이라 하며 RNN의 역전파 방법이다.
- 잠재 변수에서의 그레디언트는 2개가 들어온다
- 다음 시점에서의 잠재 변수에서 들어오게 되는 그레디언트 벡터와 출력에서 전달되는 그레디언트 벡터가 잠재변수에 전달이 되게 된다.
- 이 잠재변수에 들어오는 그레디언트 벡터를 입력과 그 이전 시점의 잠재변수에 전달하게 되고 그렇게 해서 RNN의 학습이 이루어진다.

- BPTT를 통해 RNN의 가중치 행렬의 미분을 계산해보면 아래와 같이 미분의 곱으로 이루어진 항이 계산된다.
- 모든 T 시점에서의 손실 함수를 계산한 다음에 그레디언트를 계산한 형식이다
- 모든 잠재 변수에 대한 미분 텀이 곱해지게 되어서 더해지게 되는데 아래의 빨간 시퀀스 길이가 길어질수록 이 항은 불안정해지기 쉽다.
- 이 값이 1보다 크게 되면 엄청 커지고, 1보다 작으면 엄청 작아질 수도 있다.
- 미분 값이 엄청 커지거나 작아질 확률이 높아짐
- 그래서 일반적인 BPTT를 모든 시점에 적용하면 RNN의 학습이 굉장히 불안정해짐

기울기 소실(Gradient Vanishing)이 해결책?
- Gradient Vanising : 가장 주의해야 하는 gradient가 0으로 줄어들게 되는 것은 큰 문제가 된다.
- 미래 시점에 가까울수록 gradient가 살아있고, 과거 시점으로 갈수록 gradient가 점점 0으로 가게 되면, 과거 시점에 대해 예측 모델 반영이 쉽지 않기 때문에 과거 정보를 유실할 확률이 높아진다.
- 문맥적으로 이전 정보가 필요한 Text 분석이라던지, 긴 시퀀스를 분석해야 할 경우에는 BPTT를 가지고 기울기가 0으로 죽기 때문에 과거의 정보를 잃어버리는 문제가 발생하기가 쉽다.
- 시퀀스 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정해지므로 길이를 끊는 것이 필요하다 → 이것을 우리는 truncated BPTT라 부른다.
- 모든 것을 계산하는 것이 아니라 몇 개의 블록을 정해서 걔네들만 계산한다.
- 미래 시점에서 t+1 시점까지 들어오는 그레디언트를 받다가 $H_t$에 전달하지 않고 오직 출력에서만 들어오는 $O_t$에서만 그레디언트를 받아서 $H_t$에 전달한다.
- 모든 시점에서 전달하지 않고 블록에서 끊어서 나눠서 전달하는 방식이 truncated BPTT라는 방식이다.
- 이것을 통해 gradient vanising을 해결할 수 있음
- 하지만 이게 모든 걸 해결해줄 수는 없음

- 이런 문제들 때문에 Vanilla RNN은 길이가 긴 시퀀스를 처리하는 데 사용하지 않습니다.
- 이를 해결하기 위해 등장한 RNN 네트워크가 LSTM과 GRU입니다.
- 실제 모델링에서도 이런 문제들 때문에 RNN은 쓰지 않고 LSTM과 GRU를 사용한다

(Python 5-1강) File / Exception / Log Handling
Exception
- 예상 가능한 예외
- 발생 여부를 사전에 인지할 수 있는 예외
- 사용자의 잘못된 입력, 파일 호출 시 파일 없음
- 개발자가 반드시 명시적으로 정의해야 함
- 예상이 불가능한 예외
- 인터프리터 과정에서 발생하는 예외
- 리스트의 범위를 넘어가는 값 호출, 정수를 0으로 나눔
- 수행 불가시 인터프리터가 자동 호출
파이썬에서는 Exception을 발생시키고 Exception Handling처리를 하는 것을 권장한다.
- try ~ except 문법
try :
예외 발생 가능 코드
except <Exception Type>:
예외 발생시 대응하는 코드
# if 문과 굉장히 비슷함 - But 파이썬에서는 Exception Handling을 권장
# Exception을 잡아내냐 그렇지 않냐는 프로그램이 계속 진행되냐 안되냐의 차이a = [1,2,3,4,5]
for i in range(10) :
try :
print(i, 10//i)
print(a[i])
except ZeroDivisionError :
print("Error")
print("Not divided by 0")
except IndexError as e :
print(e)
except Exception as ec :
print(ec)
# 위와 같이 전체 Exception을 잡을 수 있지만, 다른 사용자가 어디에서
# 에러가 발생했는 지 모를 수 있음. 그래서 권장 X# try-except-else
for i in range(10):
try : # 예외 발생 가능 코드
result = 10//i
except ZeroDivisionError : # 예외 발생시 동작하는 코드
print("Not divided by 0")
else : # 예외가 발생하지 않을 때 동작하는 코드
print(10//i)
finally : # 예외와 관계없이 항상 실행되는 코드
print(i, "---------", result)# raise 구문
# 필요에 따라 강제로 Exception을 발생
# raise <Exception Type>(예외 정보)
while True:
value = input("변환할 정수 값을 입력해주세요.")
for digit in value :
if digit not in "0123456789" :
raise ValueError("숫자값을 입력하지 않으셨습니다.")
print("정수값으로 변환된 숫자 -", int(value))
# raise 구문이 왜 필요한가? class를 만든 내가 아닌 사용자는 어떻게 사용할 지 모른다
# 문제가 생겼을 경우 강제로 프로그램을 종료시켜줄 필요성이 있음# assert 구문
# 특정 조건에 만족하지 않을 경우 예외 발생
def get_binary_number(decimal_number):
# 함수의 가장 윗 부분에 assert를 이용하여 제대로 된 입력이 들어왔는 지 확인
assert isinstance(decimal_number, int)
return bin(decimal_number)
print(get_binary_number(10.0))File
파일의 종류는 text 파일과 binary 파일로 나뉘는데, text 파일은 인간이 이해할 수 있는 메모장으로 열었을 때 내용 확인이 가능한 파일을 뜻하고, binary 파일은 컴퓨터만 이해할 수 있는 형태인 이진 법형식으로 저장된 파일이며, 메모장으로 열 경우 내용이 깨져 보인다.
Python File I/O
- 파이썬은 파일 처리를 위해 "open" 키워드를 사용함
f = open("<파일 이름>", "접근 모드")
f.close()
# 파일 열기 모드
# r : 읽기모드 - 파일을 읽기만 할 때 사용
# w : 쓰기모드 - 파일에 내용을 쓸 때 사용
# a : 추가모드 - 파일의 마지막에 새로운 내용을 추가시킬 때 사용
f = open("i_have_a_dream.txt", "r") # 파일의 메모리 주소에 연결
contents = f.read() # 파일을 읽어서 변수에 할당
print(contents)
f.close()
# with 구문과 함께 사용하기 - f.close()를 해줄 필요가 없음
with open("i_have_a_dream.txt", "r") as my_file:
contents = my_file.read()
print(type(contents), contents)
with open("i_have_a_dream.txt", "r") as f:
content_list = f.readlines()
# 이렇게 하면 content_list가 list의 형태를 띈다(\n기준으로 분리)
# 한 줄씩 읽고 싶다면 realine을 사용
with open("i_have_a_dream.txt", "r") as my_file :
i = 0
while True:
line = my_file.readline()
if not line :
break
print(str(i)+"==="+line.replace("\n", ""))
i += 1import shutill
# 파일 옮길 때 사용
source = "i_have_a_dream.txt"
dest = os.path.join("abc", "sunghucl.txt")
# abc\\sunghcul.txt - Mac과 Window의 경우 sepeater가 다르기 때문에
# 직접 \\을 더해주는 것보다 join을 권장한다. (파일 경로 설정 시에 사용)
shutill.copy(source, dest)# 요즘은 pathlib 라이브러리를 사용 - Path를 객체로 사용
import pathlib
cwd = pathlib.Path.cwd()
cwd.parent
list(cwd.parent.parents)
## etc..log 파일 생성하기
import os
if not os.path.isdir("log")
os.mkdir("log")
if not os.path.exists("log/count_log.txt"):
f = open("log/count_log.txt", "w", encoding="utf8")
f.write("기록이 시작됩니다.\n")
f.close()
with open("log/count_log.txt", "a", encoding="utf8" as f :
import random, datetime
for i in range(1, 11):
stamp = str(datetime.datetime.now())
value = random.random() * 100000
log_line = stamp + '\t' + str(value) + "값이 생성되었습니다." + "\n"
f.write(log_line)Pickle
객체는 어디에 있을까? 메모리에 있다. 그래서 저장을 안 하면 날아간다. 다음에도 쓰고 싶다면 pickle을 이용해 저장을 해주자.
- 파이썬의 객체를 영속화(persistence)하는 built-in 객체
- 데이터, object 등 실행 중 정보를 저장 → 불러와서 사용
- 저장해야 하는 정보, 계산 결과(모델) 등 활용이 많음
import pickle
f = open("list.pickle", "wb") # 파이썬에 특화된 바이너리 파일로 저장
test = [1, 2, 3, 4, 5]
pickle.dump(test, f)
f.close()
f = open("list.pickle", "rb") # 읽을 때
test_pickle = pickle.load(f)
test_pickle
f.close()Logging Handling
로그 남기기 - Logging
What
- 프로그램이 실행되는 동안 일어나는 정보를 기록하기
- 유저의 접근, 프로그램의 Exception, 특정 함수의 사용
Where
- Console 화면에 출력, 파일에 남기기, DB에 남기기 등등
Why
- 기록된 로그를 분석하여 의미 있는 결과를 도출할 수 있음
- 실행 시점에서 남겨야 하는 기록, 개발시점에서 남겨야 하는 기록으로 나눠짐
그래서 때로는 레벨별(개발, 운영)로 기록을 남길 필요가 있다.
- 모듈별로 별도의 logging을 남길 필요도 있다
- 이러한 기능을 체계적으로 지원하는 모듈이 필요함
logging 모듈
- Python의 기본 log 관리 모듈
import logging
logging.debug("틀렸잖아!")
logging.info("확인해")
logging.warning("조심해")
logging.error("에러났어!!!")
logging.critical("망했다..") # 프로그램 종료 됐을 때
# 이걸 그냥 실행하면 warning부터 출력이 된다. 왜냐면 python의 기본 logging level이 warning부터라서
# 이것을 해결해주기 위해서는 아래와 같이 basciConfig 필요
import logging
if __name__ == '__main__' :
logger = logging.getLogger("main")
logging.basicConfig(level=logging.DEBUG)
# logger.setLebel(logging.INFO) 이 줄이 실행되면 INFO 부터만 보임
# 이 문법을 통해서 log 파일을 생성해줌 / console 창에 띄우는 것보다 활용성이 높음
steam_handler = logging.FileHandler("my.log", mode="w", encoding='utf8')
logger.addHandler(steam_handler)
logging.debug("틀렸잖아!")
logging.info("확인해")
logging.warning("조심해")
logging.error("에러났어!!!")
logging.critical("망했다..") # 프로그램 종료 됐을 때logging level
- 프로그램 진행 상황에 따라 다른 Level의 Log를 출력함
- 개발 시점, 운영 시점마다 다른 Log가 남을 수 있도록 지원
- DEBUG > INFO > WARNING > ERROR > Critical
- Log 관리 시 가장 기본이 되는 설정

- 이러한 설정을 해주는 방법이 두 가지가 있음
- configparser - 파일에
- argparser - 실행 시점에
configparser
- 프로그램의 실행 설정을 file에 저장함
- Section, Key, Value 값의 형태로 설정된 설정 파일을 사용
- 설정 파일을 Dict Type으로 호출 후 사용
# example.cfg 파일로 저장해둠
# :, = 모두 가능
[SectionOne] # Section - 대괄호
Status : Single # 속성 - Key : Value
Name : Derek
Value : Yes
Age : 30
Single : True
[SectionTwo]
FavoriteColor =Green
[SectionThree]
FamilyName : Johnsonimport configparset
config = configparser.ConfigParser()
config.read('example.cfg')
print(config.sections())
for key in config['SectionOne'] :
value = config['SectionOne'][key]
print("{0} : {1}".format(key, value))
config['SectionOne']['Status']argparser
- Console 창에서 프로그램 실행 시 Setting 정보를 저장함
- 거의 모든 Console 기반 Python 프로그램 기본으로 제공
- 특수 모듈도 많이 존재하지만(TF), 일반적으로 argparse를 사용
- Command-Line Option이라고 부름
- Ex) Console에서 —help 쳐서 도움말 얻는 것
import argparse
parser = argparse.ArgumentParser(description="Sum two Integers.")
# 짧은 이름 # 긴 이름 # 표시명 # Help 설명 # Argument Type
parser.add_argument('-a', '--a_value', dest="A_value", help="A integers", type=int)
parser.add_argument('-b', '--b_value', dest="B_value", help="B integers", type=int)
args = parser.parse_args()
print(args)
print(args.a)
print(args.b)
print(args.a + args.b)
# 사용법
python arg_sum.py -a 10 -b 10
# 위와 같이 실행시켜주면 된다. python arg_sum.py만 쓰면 어떻게 입력하라고 힌트를 줌Logging formmater
- Log의 결괏값의 format을 지정해줄 수 있음
formatter = logging.Formatter('%(asctime)s %(levelname)s %(process)d $(message)s')
# Log config file
logging.config.fileConfig('logging.conf')
logger = logging.getLogger()(Python 5-2강) Python data handling
CSV (Comma Separate Value)
- 왜 쓰는가?
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식(Shell만 있는 Linux에서도 사용 가능)
- Text 파일 형태
CSV 객체 활용
import csv
# 이런 모듈이 있는지는 처음 알았음, 자주 안쓰게 될 것
reader = csv.reader(f, delimeter=',', quotechar='"', quoting=csv.QUOTE_ALL)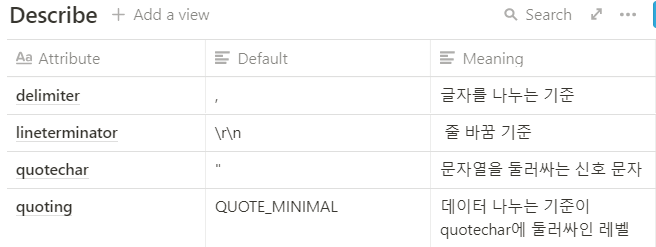

- 위 사진의 u는 unicode를 의미한다.
Web
- World Wide Web(WWW), 줄여서 웹이라고 부름
- 우리가 늘 쓰는 인터넷 공간의 정식 명칭
- 팀 버너스리에 의해 1989년 처음 제안되었으며, 원래는 물리학자들 간 정보 교환을 위해 사용됨
- 데이터 송수신을 위한 HTTP 프로토콜 사용, 데이터를 표시하기 위해 HTML 형식 사용
Web은 어떻게 동작하는가?
- 우리가 요청을 보내면, 백엔드에서 처리를 해서 다시 우리에게 HTML 형식 등으로 반환을 해준다. → 우리가 그것을 다운로드하여서 브라우저가 그것을 랜더링 해서 보여주는 것

HTML(Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현하기 위한 언어
- 제목, 단락, 링크 등 요소 표시를 위해 Tag를 사용
- 모든 요소들은 꺾쇠괄호 안에 둘러 쌓여 있음
- # 제목 요소, 값은 Hello, World
- 모든 HTML은 트리 모양의 포함관계를 가짐
- 일반적으로 웹 페이지의 HTML 소스파일은 컴퓨터가 다운로드한 후 웹 브라우저가 해석/표시
정규식 (regular expression)
- 정규 표현식, regexp 또는 regex 등으로 불림
- 복잡한 문자열 패턴을 정의하는 문자 표현 공식
- 특정한 규칙을 가진 문자열의 집합을 추출
- 정규식 연습장(http://www.regexr.com/)에서 연습 가능
정규식 기본 문법 #1
- 문자 클래스 [] : [와 ] 사이의 문자들과 매치라는 의미, -를 사용해서 범위 지정 가능
- 메타 문자 : 정규식 표현을 위해 원래 의미와 다르게 쓰이는 문자
- . : 줄 바꿈 문자인 \n을 제외한 모든 문자와 매치(all)
- : 앞에 있는 글자를 반복해서 나올 수 있음
- : 앞에 있는 글자를 최소 1회 이상 반복
- {m, n} : 반복 횟수를 지정
- ? : 반복 횟수가 1회
- | : or, ^ : not
- . : 줄 바꿈 문자인 \n을 제외한 모든 문자와 매치(all)
import re
re.findall(r'([A-Za-z0-9]+\*\*\*)', html_contents) # 전체 찾기 ***을 입력해주고 싶어서 \*\*\*로 표현
re.search # 하나만 찾기
# HTML 파일의 경우
re.findall("(\<dl class=\"blind\"\>)([\s\S]+?)(\<\/dl\>)", html_contents)
# 이런 식으로 크롤링해줄 수도 있구나, 어떤 느낌으로 접근해야할지 조금 더 와닿음XML이란
- 데이터의 구조와 의미를 설명하는 TAG(MarkUp)를 사용하여 표시하는 언어
- TAG와 TAG사이에 값이 표시되고, 구조적인 정보를 표현할 수 있음
- HTML과 문법이 비슷, 대표적인 데이터 저장 방식
- 컴퓨터(PC↔스마트폰) 간에 정보를 주고받기 매우 유용한 저장 방식
JSON
- JavaScript Object Notation
- 원래 웹 언어인 Java Script의 데이터 객체 표현 방식
- 간결성으로 기계/인간이 모두 이해하기 편함
- 데이터 용량이 적고, Code로의 전환이 쉬움
- 이로 인해 XML의 대체제로 많이 활용되고 있음
- json 모듈을 사용하여 손쉽게 파싱 및 저장 가능
- 데이터 저장 및 읽기는 dict type과 상호 호환 가능
- 웹에서 제공하는 API는 대부분 정보 교환 시 JSON 활용
- 페이스북, 트위터, GIthub 등 거의 모든 사이트
- 각 사이트마다 Developer API의 활용법을 찾아 사용
# JSON 파일의 구조를 확인 -> 읽어온 후 Dict Type 처럼 처리
import json
with open('json_example.json', 'r', encoding='utf8') as f :
contents = f.read()
json_data = json_loads(contents)
print(json_data['employees'])
# Dict Type으로 데이터 저장 -> json 모듈로 write
dict_data = {'Name':'Zara', 'Age':7, 'Class':'First'}
with open('data.json', 'w') as f :
json.dump(dict_data, f)마지막 날 강의들이 정리할 내용이 많아서 Numpy와 Pandas, 멘토링과 피어세션, 마지막으로 오피스 아워에 대한 내용은 다음 포스팅에서 마무리하겠습니다. 읽어주셔서 감사드리고 언제든지 질문 사항은 편하게 연락 주세요. :)
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week2_Day6. 내가 원했던 수업 (0) | 2021.08.10 |
|---|---|
| [BoostCamp] Week1_Day5. 한 주의 마무리 (2) (0) | 2021.08.09 |
| [BoostCamp] Week1_Day4. 길잡이, 마스터와의 만남 (0) | 2021.08.06 |
| [BoostCamp] Week1_Day3. 예상치 못한 인연의 시작 (4) | 2021.08.05 |
| [BoostCamp] Week1_Day2. 평화롭지만 치열했던. (0) | 2021.08.04 |



