
호기심 많은 분석가
[BoostCamp] Week7_Day33&34. Multi-modal Learning 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
📙개인학습
(09-1강) Multi-modal Learning
- Multi-modal : 한 타입의 데이터가 아니라 다른 데이터도 같이 학습하는 학습법
- Ex. 텍스트 + 사운드
1. Multi-modal learning overview
- 시각에 청각도 함께 사용하는 것을 Multi-modal, 맛처럼 하나만 사용하는 것을 Unimodal이라 함

- Multi model의 어려움 - 데이터들이 다 표현 방법이 다름
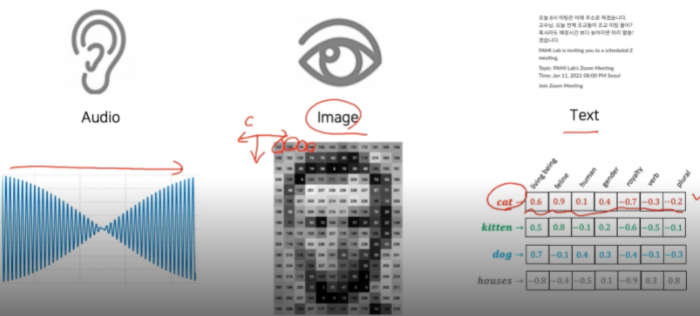
- 서로 다른 모달리티에서 오는 정보의 양도 언밸런스하고 피쳐 스페이스에 대한 정보도 언밸런스하다.
- avocado 모양의 armchair를 요구했을 때 나올 수 있는 가짓수가 너무 많음 1-N

- 머신러닝에서 모델을 사용해서 학습할 때 여러 모달리티를 썼을 때 공평하게 정보를 주더라도 쉬운 정보를 크게 받아들이고 어려운 정보는 무시하는 Bias가 생길 수도 있음
- 우리도 보통 시각으로 많은 것들을 판단하는 것처럼 뉴럴 네트워크도 가끔 소리 데이터로 판단하고 대부분 시각으로 판단하다 보니 시각으로 편향이 심해짐

- 하지만 이런 어려움에도 불구하고 여러 개의 감각기관에서 오는 데이터를 가지고 multi-modal을 하는 것은 굉장히 중요하고, 이제껏 못하던 것도 할 수 있다
- 서로 다른 데이터 타입을 공통된 스페이스로 보내서 매칭할 수 있는 구조를 만들어서 사용
- 하나의 모델을 다른 modal로 translation해서 사용
- 하나의 모델에서 다른 modal을 참조함으로써 같은 modal로 결론을 도출

2. Multi-modal tasks(1) - Visual data & Text
2-1. Text embedding
- Text의 character(글자 하나)만 사용하는 것은 어렵다 → 그래서 word level을 주로 사용함
- 이런 것과 연관이 있을 것이다라는 feature vector로 표현

- 학습 방법 - word의 dense한, embedding 한 vector가 주어졌다.
- Surprisingly, generalization power is obtained by learning dense representation
- 일반화되는 능력이 생긴다
- cat와 kitten은 가깝고, dog과 cat에 비해 cat과 houses의 거리가 먼 것을 확인할 수 있음
- 심지어 man과 woman의 차이를 king에 더해주니 queen이 나오는 단어 사이의 연관성이 있음을 파악할 수 있었음
- Surprisingly, generalization power is obtained by learning dense representation

- 어떻게 학습하는가? word2vec이라는 모델 사용 - Skip-gram model
- Trained to learn W and W`
- Rows in W represent word embedding vectors
- 001000 식으로 원핫형태로 Row가 이루어져 있으면 거기 W, weight을 곱해주면 cat vector만 추출된다.
- 출력된 embedding vector가 hidden layer가 되고 W`을 곱해서 output layer를 추출해서 이전에는 어떤 단어가 오고 이후에는 주로 어떤 단어가 많이 나오는지 데이터 패턴을 학습시킴

- 주위의 N개의 word를 예측하는 방식으로 학습하게 됨, 하나의 워드와 그 주변 워드와의 관계성을 이해하는 방향으로 학습하는 것
- 3번째 라인을 보면 brown이 input으로 the, quick, fox, jumps가 output으로 나오도록 pair를 지어줘서 4개의 pair를 학습하는 것

2-2. Joint embedding
- matching을 하기 위한 공통된 벡터들을 학습하는 것
- 주어진 이미지로부터 tag를 생성할 수도 있고, 주어진 태그 키워드로부터 이미지를 나타낼 수도 있다

- 어떻게 구현하는가? 프리트레인된 unimodal들을 합쳐줌
- Text Data든 Image Data든 feature vector로 표현해줌
- 그다음 같은 dimension으로 같은 space를 공유할 수 있게 해 준 뒤
- 마지막으로 호완성이 있도록 joint embedding을 시행

- Image tagging - Metric learning in visual-semantic space
- text와 image를 embedding 해준 다음 그 distance를 줄이는 방향으로 학습해줌
- 매칭 되지 않은 pair 사이에서는 distance를 키우도록 페널티를 줌

- input 데이터에서 dog를 빼고 cat을 넣으면 이제 고양이들이 검색될 건데 그중에서도 강아지의 배경이 유지되는 것들이 우선 검출된다.

- Application - Image & food recipe retrieval

- Recipe text (sentence) vs. food image
- Recipe는 text인데다가 순서까지 있으므로 RNN 계열의 NN를 통해서 하나의 fixed vector로 만드는 것이 첫 번째 + Instruction들도 encoding 해주고 concat 해줌 → text를 대표하는 embedding vecotr
- image는 cnn 백본 네트워크를 이용해서 하나의 feature vector로 만들어주고 dimension vecotr로 만들어줌
- 최종적으로 Recipe와 image의 cosine similarity를 구해서 판단한다.
2-3. Cross modal translation
- Image captioning
- 이미지가 주어지면 이미지를 가장 잘 설명해내는 문구를 생성해주는 연구
- image-to-sentence - CNN for image & RNN for sentence를 사용하는 게 적합함
- 한 단어를 출력해주면 그것을 다시 인풋으로 넣어주고, 반복

- 그렇게 CNN과 RNN을 합친 방법이 Show and tell
- 먼저 이미지가 인풋으로 들어오면 그것을 fix-dimensional vector로 바꿔주기 위해선 Encoder가 필요한 데 그 Encoder로는 ImageNet에서 프리트레인 된 CNN을 사용
- 그렇게 출력이 되면, 이것을 condition으로 제공하고, LSTM에 시작 token으로 넣어줌, 이것을 end가 출력될 때까지 반복해줌

- Show, attend, and tell - Example results
- sentence를 보고 이미지를 출력할 때 그 단어가 가리키는 것을 더 주목해서 보는 법

- 진행과정
- input image를 넣어주고 CNN을 통해서 feature map을 뽑아주는 데, 그냥 fixed된 dimensional vector를 뽑아주는 것 대신에 14x14의 공간 정보를 담고 있는 feature map을 출력해줌 → 그다음 RNN에 넣어줘서 하나의 word를 생성할 때마다 이 14x14를 referencing 해서 여기가 referencing 되어 있을 때 어떤 단어를 출력해야 하는지 예측을 해나가면서 단어를 생성하는 것

- Show, attend, and tell → Attention
- 사람이 얼굴을 볼 때 위에서부터 sliding window로 보지 않는다. 눈과 코 입 그 다음 주변을 살핌 (이것이 Attention의 기원)
- 그래서 Attention 매커니즘은 spatial 한 feature가 들어오게 되면 RNN을 넣어서 어디를 보고 있는지 heatmap을 만들어주게 되고 이 heatmap과 feature를 잘 결합해서 z라는 vector를 만들어줌 (weighted sum)

2-4. Cross modal reasoning
Visual question answering
- 이미지와 질문이 주어지면 그것에 대한 답을 도출하는 Task

3. Multi-modal - Audio
3-1. Sound representation
- 사운드 데이터는 어떻게 표현할까
- 보통 사운드 데이터는 시간축에 대해서 1d-form(Wave)으로 존재한다
- 대중적으로 Fourier transform을 사용한다. 그중에서도 Short-time Fourier transform (STFT)를 사용 → 전체 구간이 아니라 아주 짧은 구간에 대해서만 Fourier transform을 적용

- 오버랩시켜가면서 띄워줌
- 퓨리에 트랜스폼은 왜 해주나? 주파수의 삼각함수가 어느 정도의 성분으로 이루어져 있는지 분해해줌
3-3. Cross modal translation
Speech2Face
- 음성을 듣고 그 사람의 얼굴을 생성해내는 네트워크
- 이 네트워크를 학습시키기 위해서 Module networks를 잘 활용함
- 인터뷰가 있으면 그 사람의 얼굴을 Face Recogniton에 input으로 넣어서 Face Feature를 뽑아냄
- 그다음 우리가 학습시키고 싶은 Speech2Face Model을 통과시켜서 Feature Vector를 뽑게 됨
- 이 두 Feature가 호완이 되도록 학습시켜줌
Image to speech 모델도 있음
- 사운드와 이미지가 주어지면 이미지의 어디에서 사운드가 나는지 맞추는 모델도 있음
- Visual Net + Audio Net → Attention Net

(09-2강) Image Captioning
- Encoder를 Image-Captioning을 위해 Pretrained 된 Resnet101을 사용할 것이고 공간정보가 담긴 네트워크를 사용할 것이기 때문에 list(resnet.children())[:-2]를 사용한다.
- resnet은 임시 변수고 self.resnet으로 실제로 사용

- 나온 결과를 이제 RNN에 넣어주게 됨. 이것을 Decoder라 한다
- Beam search에서 k값을 설정하면 그만큼의 후보군을 도출하기 때문에 더 적합한 결과를 뽑아낼 수 있다

(10강) 3D Understanding
1. Seeing the world in 3D perspective
1-1. Why is 3D important?
We live in a 3D space
- AI agents operate in the real world, which is a 3D space

- 이 중요한 3D가 어디에 활용되는지 살펴보자 - AR/VR, 3D Printing, Medical applications



1-2. The way we observe 3D
우리가 3D를 어떻게 관찰하는가?
- An image is a projection of the 3D world onto a 2D space
- 고대시대부터 3D 물체를 그림으로 잘 그리기 위해 노력했음

- The camera is a projection device of the 3D scene onto a 2D image plane
- 카메라는 projection device다
- 재밌는 사실은 2D image 2개가 있으면 다시 3D를 복원할 수 있음
- Triangluation - The way to obtain a 3D point from 2D images

1-3. 3D data representation
How is 3D data represented in computer?
- A 2D image is represented by RGB values of each pixel in 2D array structure

- 3D data representation is not unique

1-4. 3D datasets
1. ShapeNet
- Large scale synthetic(인조의) objects (51300 3D models with 55 categories)
- 3D 데이터를 학습하기 위한 데이터셋 - 디자이너들이 가상으로 만든 데이터

2. PartNet (ShapeNetpart2019) - ShapeNet의 개선 버전
- Fine-grained dataset (하나의 오브젝트에 대해서 그 디테일들이 어노테이션 되어있는 데이터), useful for segmentation ( 573,585 part instances in 26,671 3D models)

3. SceneNet
- 5 million RGB-Depth synthetic indoor images (RGB 이미지와 Depth pair의 영상들, 실내의 이미지들을 시뮬레이션을 통해서 RGB-Depth로 랜더링 해서 가지고 있는 데이터셋)

4. ScanNet
- RGB-Depth dataset with 2.5 million views obtained from more than 1500 scans
- 인조 데이터가 아니라 실제 데이터를 스캔한 것

5. Outdoor 3D scene datasets (typically for autonomous vehicle applications)
- 대부분 자율주행 자동차를 연구한 데이터

2. 3D tasks

2-1. 3D recognition
- Various tasks for 3D data
- 우선적으로 recognition이 있을 것
- 2D랑 거의 비슷함, 3D data가 들어오면 Volumetric CNN 같은 3D 모델로 라벨을 뱉어냄

2-2. 3D object vDetection
- 무인차 애플리케이션에서 유용하게 사용될 수 있고, 3D 형태의 bbox를 취해줌

2-3. 3D semantic segmentation
- Semantic segmentation of 3D data, such as neuroimaging

2-4. Conditional 3D generation
- Mesh R-CNN
- Mask R-CNN과 비슷함, input은 2D image, output은 3D Meshes of detect objects
- Mask R-CNN의 head를 mesh형태로 modification 함으로써 구현할 수 있다
- 인풋 이미지가 들어오면 디텍션 하고 그 후 3D Voxels나 Meshes로 바로 변환

- Mask R-CNN의 branch를 remind 해보면 branch는 bbox와 classes, mask를 예측하는 것으로 구성되어 있다 → 아웃풋을 낼 때 하나의 ROI를 share 해서 각각의 feature로부터 각각의 출력을 prediction
- Mesh R-CNN은 여기서 3D branch를 추가해 3D mesh를 생성하는 구조

- 더 복잡한 3D reconstruction model들도 있음
- 3D object를 조금 여러 개의 sub-problem으로 decompose 하면서 더 정교한 3D를 구성하기 위한 방법
- sub-problems : physically meaningful disentanglement, 서브 프라블럼들은 물리적으로 의미 있는 분류, 중간 구성이 사람이 판별 가능한 것들의 구성
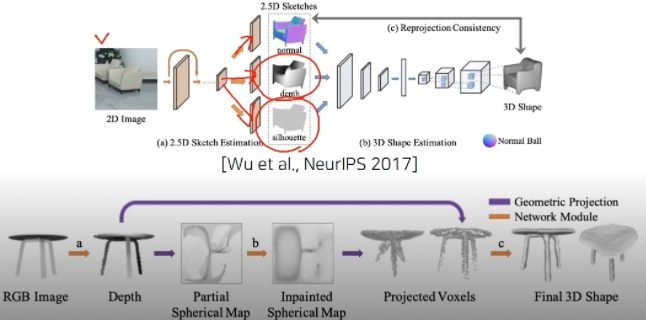
- 2D image가 주어지면 CNN의 multi-task head를 이용해서 depth, mask인 실루엣, surface normal을 추정하도록 함. 이것들을 합성해서 Full 3D를 생성
- 다른 방법은 RGB image를 depth형태로 표현 → Spherical Map이라는 도메인으로 바꿔줌, Center점에서부터 방사형 방향으로 값들을 바라보는 map을 생성 → 보이는 부분은 값이 있고 그렇지 않은 부분은 없다, 이것을 추적을 해서 채워줌 → 그 후 3D로 다시 옮겨온다(Voxel)
🌱피어세션
- 수업 어땠는지 이야기 나눔
- 추상적인 느낌
- 푸리에 변환이 너무 어렵다
- 사운드에서 Spectrogram이 어떻게 이루어지는지 모르겠다

- Spectogram의 의미가 무엇일까?
- 스펙트럼이 소리 데이터를 주파수 별로 나눠서 보는 것이고 histogram은 누적해서 쌓아간다는 의미이므로 소리 데이터를 쌓아가는 의미 아닐까요?
- 멘토님에게 여쭤보자
- joint embedding의 경우 두 개의 다른 타입의 데이터를 n개의 피쳐를 뽑는 모델을 사용해서 피쳐 추출해주고, 그 추출된 피처 벡터를 한 개의 embedding space로 mapping을 하고 그 space안에서 연관이 있으면 거리를 가깝게 그렇지 않다면 멀게 훈련을 한다.
- word2vec의 경우 embedding vector를 학습하는 건가요?
- 그렇습니다. word2vec은 비슷한 context를 가질 경우 비슷한 meaning을 가진다고 가정한 것이다.
- 기타 해결되지 않은 질문들은 멘토님께 질문하기로!
- 멘토링 시간이 남으면 어떤 것들을 요청드릴지 함께 고민
- 딥러닝 산업 관련 리뷰
- 강의
- 프로젝트 팁
- 현업에서 프로젝트 과정
- 현업에서 새로운 기술을 적용하실 때 정보를 얻는 방법
👨💻마스터클래스-오태현님
- Boostcamp CV 강의 == Stepping stones
- 넓은 범위의 디딤돌을 가르쳐주고 그 사이를 메꾸는 것은 스스로의 역할

넘쳐나는 논문들.. 내가 봐야 하는 논문 선정법
거꾸로 거슬러 올라가기
웹브라우저 시작 페이지 활용
- ArXiv Sanity (by A. Karpathy)
Top recent / Last week을 선택.

Deep learning을 바라보는 우리의 자세
- 왜 해야 할까를 생각해보자, wording and direction
- Case study1
- 시각장애인 분들은 걸어 다니면서 모든 물건들이 위험할 수 있다. 그러한 위험에서 벗어나실 수 있게
- 세상을 바꿀 수 있는 주제로 만들어보는 건 어떨까
- 하지만 언제나 장애인 분들을 언급하거나 사용할 때 따라야 할 가이드라인이 있음
- Guidelines for Writing and Referring to People with Disabilites
- 시각장애인 분들은 걸어 다니면서 모든 물건들이 위험할 수 있다. 그러한 위험에서 벗어나실 수 있게
- Case study 2
- DeepFake vs. Privacy
Deep learning이 직업이 되었을 때, 현실

Deep learning 할 때 흔히 실수하는 것들
- 정말 생각보다 많은 사람들이 이런 실수를 함
- 변인통제!!!
- 한정된 시간, 그리고 실적의 압박 → 동시에 두세 가지 바꿔서 commit & 실험
- 학위의 의미
- 석사 - Problem solver
- 박사 - Problem definer
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3a8yc79
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [Boostcamp] 멘토님, 마스터님, 그리고 우리 팀 (2) | 2021.10.21 |
|---|---|
| [BoostCamp] Week9_Day37. New P-Stage (0) | 2021.10.13 |
| [Boostcamp] 온라인의 인연을 오프라인에서 (4) | 2021.10.04 |
| [BoostCamp] Week7_Day32. Conditional Generative Model (0) | 2021.09.28 |
| [BoostCamp] Week7_Day31. Instance/Panoptic Segmentation (0) | 2021.09.27 |
'Coding/BoostCamp' Related Articles
more



