
호기심 많은 분석가
[BoostCamp] Week7_Day31. Instance/Panoptic Segmentation 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
📙개인학습
(07강) Instance/Panoptic Segmentation and Landmark Localization
Segmentation과 object detection의 연구들을 살펴보면 18년도 이후로는 진행이 안되고 있다. 각각의 Task보다 Instance/Panoptic Segmentation 문제로 고도화되었기 때문이다.
1. Instance segmentation
1-1. What is instance segmentation?

- Instance와 Semantic의 차이는 같은 클래스의 물체라도 객체(Instance)가 다를 때 구분이 가능한지 여부이다.
- Instance Segmentation = Semantic segmentation + distinguishing instances
- 기본적으로 Object detection을 기반으로 구할 수 있음
1-2. Instance segmenters
Mask R-CNN, Faster R-CNN의 업그레이드 버전
- RoI extraction through RoIAlign, an improved version of RoI Pooling
- 이전의 RoI pooling은 정수 값만 취급했었는데, Mask R-CNN은 interpolation을 통해 소수점까지 취급하여 정교함을 더했다. → 성능 ↑
- RoIAlign을 통과시키며 각 pixel별로 Binary Mask를 씌워준다(Instance인지 아닌지)

- 기존의 Faster R-CNN에서는 pooling 된 feature위에 올라가 있던 head가 classification과 box regression, 2개가 있었다 + 그 헤드들에 Mask branch를 추가함
- 7x7x2048 → 14x14x256으로 upsampling하면서 채널 수는 줄임
- 그다음 80개의 class로 binary classification 하는 구조
- 하나의 bbox에 대해서 일괄적으로 모든 class에 대한 Mask를 생성한다. 그다음 classification head에서 class가 무엇인지 Mask를 참조한다.

- Summary of the R-CNN family

Instance Segmentation을 위한 Single Stage 구조
- YOLACT (You only Look At CoefficienTs)
- 마스크의 프로토타입을 추출해서 사용
- Mask RCNN에서는 실제로 사용하지 않더라도 80개의 독립적인 마스크를 한 번에 생성했었다. 그리고 그중에서 classification 된 결과에 따라서 하나를 참조했음
- 프로토타입은 마스크는 아니지만 마스크를 합성해낼 수 있는 기본적인 Soft segmentation component들이다. Like 선형대수학의 Basis, Basis를 linear combination 해서 뭐든 만들 수 있으므로 마스크를 basis의 span으로 보는 것
- 그래서 Prediction head에서 prototype에 쓸 수 있는 coefficient들을 도출하여 segmentation 함
- 정말 Fancy 한 기술
- 키포인트는 마스크를 생성하기 위해서 Mask RCNN처럼 object의 개수를 80개씩 생성하는 것이 아니라 적당히 작은 prototype의 개수로 선형 결합하여 다양한 object를 만드는 것이다.

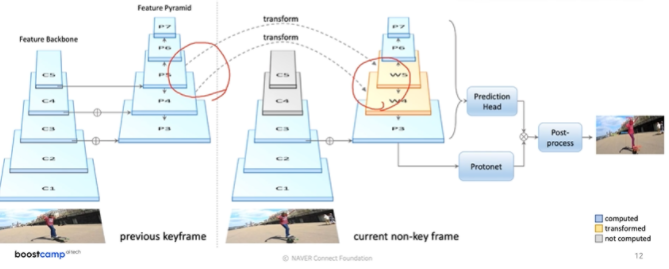
- YolactEdge
- 소형화시키기 위해
- 이전 Frame 중에서 key frame의 feature를 전달받아서 특징 맵의 연산량을 획기적으로 줄임
- 성능은 비슷하되 속도를 굉장히 높임
2. Panoptic segmentation
2-1. What is panoptic segmentation?
- 기존의 instance segmentation은 배경에 관심이 없었다. 그래서 배경에 관심이 있다면 semantic segmentation이 유리했는데, 객체들을 구분할 수 없었다 → 그래서 탄생한 것이 Panoptic segmentation

2-2. UPSNet

- 마지막 과정을 조금 더 자세하게 표현
- 각 헤드에서 나온 결과는 Instance head에서 나온 mask, semantic head에서 나온 물체와 배경(stuff)을 예측하는 mask
- 물체에 대한 mask를 instance의 mask와 더해줘서 최종 출력에 삽입함
- instance와 배경 이외에 소속되지 않는 unknown class의 물체들을 제거하기 위해 instance로 사용된 부분들을 제외해서 나머지 배타적인 부분들을 모두 한 채널로 합쳐서 추가하게 됨

2-3. VPSNet
두 시간 차이를 가지는 파이라는 모션 맵을 사용 해서 각 프레임에서 나온 feature map을 모션에 따라서 매핑을 해줌
1. Align reference features onto the target feature map (Fusion at pixel level)
- 현재 프레임으로 표현되지 않던 특징들을 이전 특징들과 합쳐서 더 높은 detection 성능을 보여줌
2. Track module associates different object instances (Track at instance level)
- 기존의 RoI들과 현재 RoI들이 어떻게 서로 연관이 되어있는지를 알아봄
3. Fused-and-tracked modules are trained to synergize each other

3. Landmark localization
3-1. What is landmark localization?

- 얼굴이나 포즈를 tracking 하는 기술, 특정 물체에 대해서 중요하다고 생각하는 특징들(landmark)을 정의하고 추적하는 것
- Landmark localization (=keypoint estimation) : Predicting the coordinates of keypoints
3-2. Coordinate regression vs. heatmap classification
- Coordinate regression
- 각 포인트의 x, y 위치를 바로 예측하는 regression 방법 → 부정확함, 일반화의 문제가 있음
- heatmap classification
- semantic segmentation처럼 한 채널들이 각 keypoint들을 담당
- 각 키포인트마다 하나의 클래스로 생각해서 키포인트가 발생할 확률 맵을 픽셀 별로 classificatoin
- 높은 성능을 보이지만 연산량이 너무 많음

- Landmark location to Gaussian heatmap
- x, y가 가우시안의 평균을 나타낸다. 그 주위에 분포를 씌운다.

3-3. Hourglass network

- 영상 자체를 작게 만들어서 receptive field를 키움 + skip connection을 추가해서 low level feature를 참고해서 정확한 위치를 특정하게끔 유도
- 이것을 여러 번 거쳐서 점점 큰 그림과 디테일을 구축해나가는 구조
- Stacked hourglass modules allow for repeated bottom-up and top-down inference that refines the output of the previous hourglass module
- UNet과 굉장히 비슷한데 조금 다른 점은 skip connection을 취해줄 때 concat이 아니라 더해줌으로써 dimension이 늘지 않고, convolutional layer를 통과해서 전달해야 함

3-4. Extensions
몇몇 개의 주요한 landmark만 찾는 sparse 한 방법들 외에도 신체 전체에 대해서도 찾는 방법을 알아보자
- DensePose
- 각 파트별로(머리, 몸통) 3D 표준모델에서 어떤 부위에 해당하는지 좌표를 색상으로 나타낸 것 → UV맵 표현이라 함

- UV Map is a flattened representation of 3D geometry, Also UV map is invariant to motion

- DensePose R-CNN = Faster R-CNN + 3D surface regression branch

- RetinaFace
- FPN의 각 Task에 필요한 branch들을 여러 개(얼굴의 판별, box regression, 5개 landmark detect, mesh regression) 넣어서 다양한 방식을 한 번에 풀게 함
- RetinaFace = FPN + Multi-task branches
정리
backbone network 위에 본인이 관심 있는 target-task의 branch만 넣어주면 된다. 현재 CV의 큰 디자인 패턴 중 하나

4. Detecting objects as keypoints
4-1. CornerNet & CenterNet
- Bounding box = {Top-left, Bottom-rihgt} corners
- 코너들 페어를 찾아서 bbox를 찾아주는 싱글 stage 구조에 가깝고 성능보단 속도에 집중함

- 센터 넷에서는 센터 포인트의 역할이 성능에 있어서 중요하다. 그래서 그것을 박스 구성 요소에 추가
- CenterNet(1)
- Bounding box = {Top-left, Bottom-rihgt, center} corners

- CenterNet(2) - 최신 연구
- Bounding box = {Width, Height, center} corners
- 최소 정보로 표현, center를 알면 굳이 두 좌표가 필요가 없다
- 성능도 뛰어나고 속도가 가장 빠름


- Task들이 대부분 비슷한 디자인 패턴을 갖는다. 디자인 패턴을 따라 설계하면 쉽다.
- 데이터 또는 출력을 변경하는 것으로 속도나 성능 향상을 크게 가져올 수 있다. 데이터 표현이 중요하다.
🌱피어세션
Q mask r-cnn에서 class가 object를 참조하는 게 무슨 의미인지 모르겠다. 그리고 같은 class의 object를 어떤 식으로 색을 구별할 수 있는지???
A1. mask R-CNN을 통해서 나온 각각의 class confidence와 mask를 통해 confidence가 가장 높은 class에 mask를 결합하는 방식으로 연산이 진행된다.
A2. 각각의 RoI patch에 대해서 연산을 진행하기 때문에 각 patch마다 다른 instance를 부여하면 된다.
Q protonet이 어떻게 생성되는지?? 어떻게 학습되는지?
A1. protonet은 convolution Network로 구성되어 미리 정해진 k개의 mask를 생성해 image의 각 부분을 다르게 activate 하는 기능을 가지고 있다. 이런 기능과 mask coefficient 값을 가지고 object를 activate 할 수 있다.
Q Mask R-CNN이 하나의 RoI에 대해서 모든 class mask를 생성하는 이유
A. 아마도 class confidence를 구한 뒤 mask를 구하면 속도 측면에서 느리기 때문에?? 속도와 리소스의 trade off가 아닐까?
Q instance segmentation에 배경 class를 넣고 한 번에 처리해버리면 되지 않음??
A. 중요한 건 배경을 인식하는 것이 아니라 배경의 물체의 모양까지 인식하는 것이기 때문에 단순히 배경을 하나의 class로 넣고 instance segmentation 하는 것으로 해결되지 않는다.
Q. cornetNet에서 center point가 왜 존재할까?
A1. center point를 통해 좌상단, 우하단의 값을 조정할 수 있기 때문에 사용!
Q. 기존의 object detection에서 왜 cornetNet을 사용하게 되었고 이를 사용해서 성능이 향상됐을까?
속도적인 부분도 고려한 것 같다.
→ 논문을 읽어보면 나올 듯!!
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
data-hun.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [Boostcamp] 온라인의 인연을 오프라인에서 (4) | 2021.10.04 |
|---|---|
| [BoostCamp] Week7_Day32. Conditional Generative Model (0) | 2021.09.28 |
| [BoostCamp] Week7_Day30. CNN Visualization (0) | 2021.09.27 |
| [BoostCamp] Week6_Day29. 새로운 멘토님 (0) | 2021.09.21 |
| [BoostCamp] Week6_Day28. 팀원 찾기 (0) | 2021.09.21 |



