
호기심 많은 분석가
[Pandas] Pandas 대용량 데이터 처리하기 본문
포스팅 개요
데이터 분석할 때 Pandas 이용을 많이들 하실 겁니다. 저 또한 편리하기에 주로 쓰는 Library였습니다. 하지만 Pandas는 기본적으로 data type을 동일하게 불러오기 때문에 데이터 용량이 커지는 상황이 종종 발생합니다.
그러던 와중 오승우 님의 뚱뚱하고 굼뜬 판다(Pandas)를 위한 효과적인 다이어트 전략이라는 좋은 자료를 보게 되어 공유하고자 포스팅을 하게 되었습니다. 우리 함께 판다의 다이어트를 도우러 가시죠!

포스팅 본문
대용량 데이터를 다룰 때는 Memory가 버티지 못할 때가 많습니다. 간단한 두 가지 방법을 통해 줄여보겠습니다.
1. 코드화
문자열로 된 데이터를 숫자 / 영어로 변환하여 데이터 크기 축소
- 남자 -> 0
여자 -> 1
- 서울특별시 -> 11
대구광역시 -> 45
- 정상 -> 0
비정상 -> 1
이 작업을 수행 시 다음과 같은 결과를 얻을 수 있습니다.
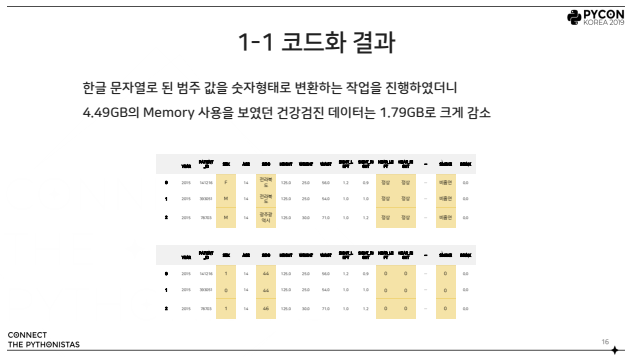
2. 데이터 형식 변환
이번 작업에서 가장 도움을 많이 받은 방법입니다.
데이터 형식에 따라 표현하는 값의 범위와 사용하는 메모리 크기 달라집니다. Pandas는 컬럼마다 고정된 크기(Fixed-length)로 할당하기 때문에 크기가 작은 데이터 형식을 사용하면 메모리 사용량을 크게 줄일 수 있습니다.
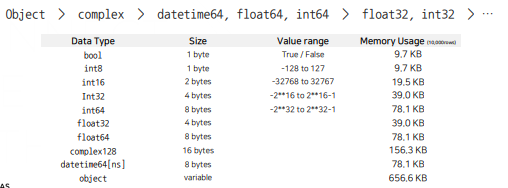
데이터 형식 변환 방법에는 3가지가 있습니다.
1. 각 컬럼의 데이터 형식을 아는 경우
data_types = {'col1' : 'int8', 'col2' : 'float32'}
df = pd.read_csv(data_path, dtype=data_types)2. 데이터를 불러왔지만 크기를 줄이고 싶은 경우
df = pd.read_csv(data_path)
data_types = check_dtypes(df)
df = df.astype(data_types)3. 데이터가 커서 불러오지도 못하는 경우
columns = pd.read_csv(data_path, rows=0).columns
data_tpyes = {col : check_dtypes(df[col]) for col in columns}
df = pd.read_csv(data_path, dtype = data_types)여기서 check_dtypes()라는 함수는 데이터 형식을 바꾸어주는 함수입니다.

이번 작업에 유용하게 쓴 같은 분의 함수인 reduce_mem_usage()도 소개해보겠습니다.
# 참조 : https://www.mikulskibartosz.name/how-to-reduce-memory-usage-in-pandas/
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
이렇게 2가지 간단한 방법을 통해 대용량 데이터를 처리해볼 수 있었습니다. 이 외에도 좋은 방법들이 많으므로 포스팅
개요에 첨부되어 있는 파일을 참고해보시면 좋을 것 같습니다. 다들 즐거운 데이터 분석하시길 바랍니다. :)
'Coding > Machine Learning & Python' 카테고리의 다른 글
| [Python] ImportError : cannot import name 'function' from 'module' (location) 발생 시 (0) | 2021.05.04 |
|---|---|
| [Python] 파이썬(Python) Flask로 웹서버에서 ML model 적용시키기 (2) (0) | 2021.05.04 |
| [Python] 파이썬(Python) Flask로 웹서버에서 ML model 적용시키기 (1) (0) | 2021.05.04 |
| [Machine Learning] Sklearn으로 학습한 model 저장 및 재사용 방법 (0) | 2021.05.03 |
| [퓨처스킬] 판다스(Pandas) 기본 (0) | 2021.04.28 |



