
호기심 많은 분석가
[퓨처스킬] 판다스(Pandas) 기본 본문
포스팅 개요
매일 함께 성장하는 학습 커뮤니티, 퓨처스킬의 베타 서비스에 참여하게 되었습니다. 퓨처스킬은 크리에이터 분들이 각기 다른 주제로 콘텐츠를 구성해주시고 그 콘텐츠에 대한 각자의 의견을 토론하는 커뮤니티입니다.
정답은 없고 서로 토론하며 알아가자는 퓨처스킬의 정신이 멋있고, 검색하며 공부하기 용이하게 검색 키워드도 제공해주는 세심함에 반할 수밖에 없는 커뮤니티입니다.
데이터 분석의 기초부터 심화까지 여러 콘텐츠가 준비되어 있어, 어떻게 공부해야할 지 모르겠는 분께 꼭 추천드리고 싶은 사이트입니다.
퓨처스킬 : https://futureskill.io/
포스팅 본문

퓨처스킬의 첫 콘텐츠로는 김용담 크리에이터님의 판다스 기본을 소비해봤습니다. 총 26문제로 이루어져 있었고, 판다스에 대해 대략적으로 알고 있던 개념들도 다시 한번 되짚어볼 수 있어 좋았습니다.
우선 판다스에 대해 알아보며 시작하겠습니다.
- 데이터 분석에는 3가지 라이브러리가 기본이다.
- Numpy, Pandas, Matplotlib
- Pandas는 파이썬 데이터 분석 라이브러리(Python Data Analysis Library)의 약자로, 표 형태의 DataFrame을 자유자재로 잘 다룰 수 있도록 도와주는 라이브러리이다.
- 이런 표 형태의 데이터를 정형 데이터(Structured Data, Tabular Data)라고 한다.
- Pandas를 통해서 우리는 정형 데이터 분석을 손쉽게 할 수 있다.
- Pandas는 내부적으로 Numpy array를 확장하여 구현되어 있다. Numpy의 기본적인 개념인 모든 dtype이 동일한 것과, fancy indexing, broadcasting 등을 모두 지원한다.
문제들을 해결하며 다시 정립하게 된 개념들을 복기해보겠습니다.
Num3.

- Pandas의 date_range라는 method를 이용하여 날짜를 자동으로 구현할 수 있다.
- pd.date_range('2020-01-01', periods=5)라는 코드로도 같은 결과를 구현 가능하다.
Num14.

- axis는 어느 축으로 합칠건지 정한다.
- 0을 가로축을 기준으로 합친다. 위-아래
- 1은 세로축을 기준으로 합친다. 오른쪽-왼쪽
- ignore_index는 합칠 인덱스를 무시할건지 여부를 정한다.
- True로 할 경우 합칠 DataFrame의 인덱스를 무시하고
- False의 경우 합칠 DataFrame의 인덱스를 보존한 상태로 합친다.
- 추가로 iloc는 위치, loc는 행의 이름으로 접근한다.
Num19.
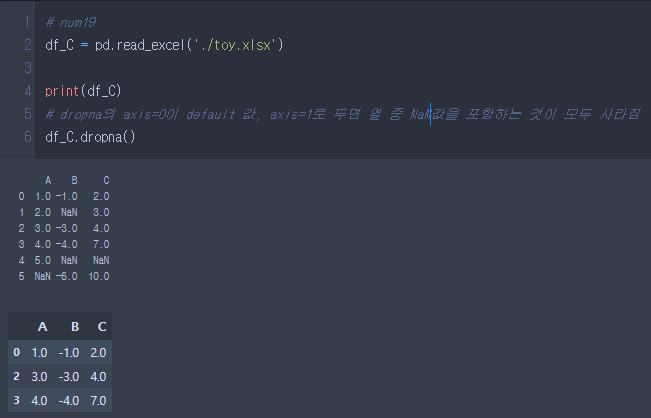
- dropna() method의 경우 axis=0이 defalut 값, 같은 행 중 NaN 값이 있을 경우 그 행을 날려버림.
- axis=1로 둘 경우 열 중 NaN 값을 포함할 경우 모두 사라짐.
Num20 & 21.

- 이번 문제는 정말 유용한 걸 배웠다.
- fillna()라는 함수는 NaN값을 채워주는 함수인데, method로 'ffill' or 'pad'를 사용하면 앞 방향(fill gaps forward)을, 'bfill' or 'backfill'을 사용하면 뒷 방향으로(fill gaps backward) 채워준다.
- limit 변수도 선언해주면 앞/뒤 방향으로 결측값 채우는 횟수도 제한해준다.
- fillna()라는 함수는 NaN값을 채워주는 함수인데, method로 'ffill' or 'pad'를 사용하면 앞 방향(fill gaps forward)을, 'bfill' or 'backfill'을 사용하면 뒷 방향으로(fill gaps backward) 채워준다.
- 그 열 값의 평균으로 NaN값을 채우고 싶을 경우 df.mean()을 fillna() 함수에 넣어주면 된다.
Num24.

- 마지막 행을 추가하고자 할 경우, 보통은 loc로 추가해줬었는데 append를 사용하는 것이 조금 더 깔끔해보인다.
Num25 & 26.

- pivot_table을 자주 써보지 않아 익숙하지 않았는데 gropby().mean()과 동일하게 사용할 수 있다는 것을 배웠다.
Pandas의 경우 평소에 정말 많이 사용하니까 대부분의 기능을 잘 사용한다고 생각했는데, 아직 배울 기술들이 더 많음을 알 수 있었다. 앞으로 또 어떤 것을 배울 수 있을까 기대가 됩니다. :)
'Coding > Machine Learning & Python' 카테고리의 다른 글
| [Python] ImportError : cannot import name 'function' from 'module' (location) 발생 시 (0) | 2021.05.04 |
|---|---|
| [Python] 파이썬(Python) Flask로 웹서버에서 ML model 적용시키기 (2) (0) | 2021.05.04 |
| [Python] 파이썬(Python) Flask로 웹서버에서 ML model 적용시키기 (1) (0) | 2021.05.04 |
| [Machine Learning] Sklearn으로 학습한 model 저장 및 재사용 방법 (0) | 2021.05.03 |
| [Pandas] Pandas 대용량 데이터 처리하기 (0) | 2021.05.02 |
'Coding/Machine Learning & Python' Related Articles
more



