
호기심 많은 분석가
[BoostCamp] Week6_Day29. 새로운 멘토님 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
(05강) Object Detection
1. Object detection
- Object detection란?
- 요즘 Semantic segmentation에서 Instance segmentation, Panoptic segmentation까지 구현한다. 그것들을 가능케하려면 한 가지가 필요한데 그것이 바로 Object detection이다. Class별로 구분된 물체들에서 각각을 구별하기 위해 사용된다.

- Object detection은 Classification과 Box localization을 동시에 하는 Task이다. (여담이지만 애기가 참 귀엽군요)

- 어디에 주로 활용되는가?
- 대표적인 사례가 자율주행, 글자 인식(OCR)

2. Two-stage detector
- 요즘 Object detection은 2 track으로 발전 중이다 → two-stage detector vs. one-stage detector
2-0. Traditional methods - hand -crafted techniques
- 이전에는 어떤 방식을 사용했을까?
- Gradient-based detector (e.g., HOG = Histogram of Oriented Gradients)
- 사람 경계선의 평균들을 내서 이미지를 만들었더니 1번 사진처럼 실루엣이 잘 묻어 나오는 것을 확인할 수 있었다. 그래서 경계선의 특징을 잘 알기 위한 엔지니어링을 수행 (SVM 사용)

- Selective search
- 다양한 물체 후보군에 대해서 영역을 특정해서 제한해줌 → Bounding Box를 제한
(Box proposal) - 시행 알고리즘
- 영상을 비슷한 색끼리 잘게 분할함 (Oversampling)
- 잘게 분할된 영역들을 비슷한 영역끼리 합쳐준다. → 비슷함의 기준을 색인지, 그레디언트의 분포인지를 정의해줘야 함
- 각자 큰 Segmentation을 포함하는 bounding-box를 tight 하게 추출해서 물체의 후보군으로 사용
- 다양한 물체 후보군에 대해서 영역을 특정해서 제한해줌 → Bounding Box를 제한
2-1. R-CNN
- 딥러닝을 이용한 object-detection의 시작
- Selective search를 이용하여 2천 개 이하의 region proposal을 구해줌
- 각 Region을 image classification NN의 input size에 맞게 warpping을 해줌 (Ex. Alex - 224x224)
- CNN에 넣어서 카테고리를 Classification 해줌

- 단점
- Region Proposal 하나하나마다 모델에 넣어서 processing을 해야 하기 때문에 속도가 굉장히 느리고,
- hand-design(selective search)된 이미지기 때문에 학습을 통한 성능 향상에 한계가 있다.
- Classification시 CNN을 통해 추출한 벡터를 가지고 각각의 클래스 별로 이것이 해당 물체가 맞는지 아닌지를 구분하는 SVM Classifier를 학습시킨다. 왜 그럴까?"그냥 CNN Classifier를 쓰는 것이 SVM을 썼을 때보다 mAP 성능이 4% 정도 낮아졌다. 이는 아마도 fine tuning 과정에서 물체의 위치 정보가 유실되고 무작위로 추출된 샘플을 학습하여 발생한 것으로 보인다."
- 이제는 쓰이지 않는 방법이라고 한다.
- 저자들의 답변
- 그렇다면 Output이 2천 개일까? 각각의 박스가 모두 필요한 것일까?
- 그렇지가 않다. SVM을 통과하며 각각의 박스들은 어떤 물체일 확률 값(Score)을 가지게 되었기에 스코어가 가장 높은 박스만 남기고 나머지는 제거한다. 이 과정을 Non-Maximum Supperssion이라 함.


- 서로 다른 두 박스가 동일한 물체에 쳐져 있음을 어떻게 확인할까?
- 여기서 IoU(Intersection over Union)의 개념 적용
- 두 박스의 교집합을 합집합으로 나눠준 값 → 두 박스가 일치할수록 값이 1에 가깝다
- 논문에서는 IoU가 0.5보다 크면 동일한 물체를 대상으로 한 박스로 판단하고 Non-Maximum Supperssion을 적용

2-2. Fast R-CNN
- 언급했듯이 R-CNN은 너무 느렸다. 이를 개선하고자 영상 전체에 대한 feature를 한 번에 추출하고 이를 재활용해서 여러 오브젝트들을 디텍션 해줌
- 원본 이미지에 Convolution layer를 거쳐 feature map을 뽑아준다
→ (H, W, C)를 갖고 있는 Tensor형태의 output / Fully Convolutional 한 layer만 지나기 때문에 입력 사이즈와 관계없이 가능하다 - RoI Pooling layer를 거침, RoI feature extraction from the feature map through RoI pooling
(ROI = Region of Interest : Region proposal이 제시한 물체의 후보 위치)
bounding box가 주어지게 되면 RoI에 해당하는 feature만을 추출 → 일정 사이즈로 Resize, dimension을 공통시켜주기 위하여- RoI에 해당하는 부분만 max-pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소하는 단계 (고정된 작은 윈도우 사이즈로 나눠줌, 아래 그림 참조)
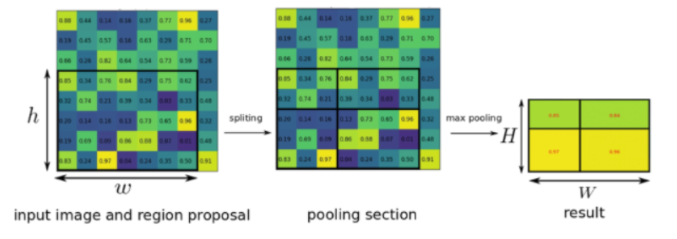
- 더 정확한 bbox를 위하여 bbox regressor을 취해주고 classifier를 취해줌

- 이렇게 Feature만 재활용했는데 기존에 비해 18배가 빨라졌다. BUT, Region Proposal이 Selective search를 통해 이루어지기 때문에 학습을 통한 성능 향상이 어려운 것은 여전히 문제로 남았다.
2-3. Faster R-CNN
- 드디어 Region proposal을 Neural Network 기반으로 대체 → Object Detection에서 최초의 모든 네트워크가 NN 기반인 End-to-End 모델 개발
- 그에 앞서 기본 개념을 알고 넘어가자
- Anchor boxes
- 각 위치에서 발생할 것 같은 box들을 미리 정의해둔 후보군
- IoU with GT (Ground Truth, 실제값) > 0.7 → positive sample
- IoU with GT (Ground Truth, 실제값) < 0.3 → negative sample
- 이렇게 하나의 Anchor box를 정해서 IoU가 0.7 이상이면 positive sample로 두고, 나머지를 negative를 둬서 이에 대한 loss를 줘서 학습하게 됨

- 이제 Faster R-CNN의 가장 큰 변화를 살펴보자
- Time-consuming selective search → Region Proposal Network (RPN)
- 영상 하나에서 공유되는 Feature map을 뽑는다.
- RPN에서 Regoin proposal을 여러 개 뽑는다
- RoI Pooling을 수행하고 bbox regressor, classifier 수행

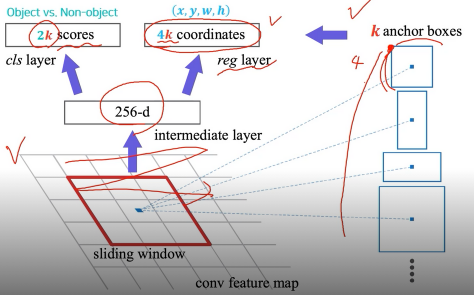
- RPN을 조금 더 자세히 살펴보면 feature map에서 fully convolution 하게 sliding window 방식으로 돌면서 매 위치마다 고정된 k개의 anchor box를 고려함
- 매 위치마다 256 dimension의 feature vector 추출
- Object인지 아닌지 판별하는 2k 개의 classification score들을 뱉어냄 (object vs. Non-object)
- k개의 bbox의 정교한 위치를 파악하는 Regression branch가 따로 있음 → 4k 개의 coordinates (x, y, w, h)
Summary of the R-CNN family

3. One-stage detector
3-0. Comparison with two-stage detectors
- One-stage vs. two-stage
One-stage detector는 정확도를 조금 포기하더라도 속도를 높여서 real-time detection이 가능하도록 설계하는 데에 목적을 둠, Region proposal을 기반으로 한 RoI를 사용하지 않고, 곧바로 Box Regression과 Classification을 하기 때문에 구조가 단순하고 빠른 수행 시간을 보여준다.

3-1. You only look once (YOLO)
- Input image를 SxS grid로 나눈다
- B개의 box를 4개의 좌표와 confidence score를 예측하고 그것에 따른 class score를 또 따로 예측함

- YOLO 구조는 CNN의 구조와 비슷하다.
- 총 30 channel의 결과가 나옴. bbox의 anchor는 2개, B는 2이다. 그리고 Object class는 20개
- B 1개에 x, y, w, h, object score 5개씩 이므로 5B+C = 30

3-2. Single Shot MultiBox Detector (SSD)
- YOLO는 맨 마지막 layer에서만 prediction 하기 때문에 localization 정확도가 떨어지는 경향이 있었음 → 그래서 이를 보완하고자 SSD가 등장
- multi-scale object를 더 잘 처리하게 되어서 각 해상도에 적절한 bbox를 추출하도록 도움

- VGG를 backbone으로 사용해서 conv4 블록에 중간 feature map 출력에서부터 최종 결과들을 출력하게끔 classifier가 붙어 있음
- 각 scale마다 object detection 결과를 출력하도록 설정해서 다양한 scale의 object들에 대해서 더 잘 대응하도록 설계하였다
- 흥미롭게도 YOLO보다 훨씬 빠르고 높은 성능은 물론 Faster R-CNN보다 높은 성능을 보여줌
4. Two-stage detector vs. one-stage detector
4-1. Focal loss
- Single-stage 방법들은 RoI pooling이 없다 보니까 모든 영역에서의 loss가 발생되고 일정 gradient가 발생된다. 이게 왜 문제가 되는가?
- 일반적인 Detection 문제의 경우 물체보다 배경이 훨씬 많다. 그러다 보니 positive 한 영역이 적고 class imbalance 문제가 생기는 것 → 이것을 해결하기 위해 Focal loss가 등장
- Cross Entropy의 확장
- 감마가 클수록 틀렸을 때의 gradient(기울기) 값이 크기 때문에 크게 변화함, 맞았을 때는 거의 변하지 않음 → 어려운 문제일수록 강한 weight를 주고 쉬운 문제일수록 작은 weight를 주는 학습법

4-2. RetinaNet
RetinaNet is a one-stage network
- FPN을 활용해서 Low level의 특징 layer들과 high level의 특징을 잘 활용하면서도 각 scale별로 물체를 잘 찾기 위해 중간중간 feature map 더하기 operation이 사용됨
- class헤드와 box헤드가 따로 구성이 되어서 classification과 box regression을 dense 하게 각 위치마다 수행하게 되는 것
- SSD보다 조금 높은 속도와 훨씬 높은 성능을 보임

5. Detection with Transformer
- NLP에서 높은 성과를 낸 Transformer를 이용해서 CV에서도 성과를 내고자 하는 흐름
- ViT (Vision Transformer) by Google
- DeiT (Data-efficient image Transformer) by Facebook
- DETR (DEtection TRansformer) by Facebook
- DETR
- Transformer를 object detecion에 활용
- CNN의 feature와 각 위치의 multi-dimension을 표현한 encoding을 쌍으로 해서 입력 token을 만들어줌
- encoding이 되고 나서 transformer encoder를 거치고 난 후 추출된 특징들을 decoder에 넣어줌
- 그다음 object query라는 것으로 질의를 해줌
- 어떤 물체가 있는지, box는 어떻게 그리는지에 대한 출력을 뱉어줌

👨🏻🏫 멘토링
- Computer Vision 회사에서 재직 중!
Q1. GoogLenet에서, 여러 auxiliary classifier 간의 차이로 인한 gradient gap을 어떻게 학습하는가?
Low level의 Auxiliary classifier로 인한 강한 Gradient가 악영향을 끼칠 수 있을 것 같은데, 해결하는 방법은?
- Gradient에 0.3을 곱한다. 실험적 값, 강력한 영향을 끼치는 값은 아닌가하지만 현재로서는 좋은 구조로 판단되지 않고 있기 때문에 신경을 덜 써도 된다. 사용하지 않는 중
- auxiliary classifier가 없을 때 gradient vanishing이 발생함 → 있는 것이 훨씬 도움이 된다.
Q2. He Initialization으로 그레디언트를 제어하는 것이 맞나? Forward시 degradation 제어 아닌가?
He Initialization이 gradient에 미치는 영향이 무엇인가?
- Each Layer에 나오는 Activation 값을 잘 조정해서, Gradient가 충분히 큰 값을 가지도록 유도Xavier Initialization으로 하면, Layer가 깊어져도 0 activation이 많지 않고, -1, 1 값도 많지 않음He는 ReLU 구조에서 레이어가 깊어져도 meanless activation이 많지 않음

- Xavier를 ReLU에 사용하면 depth가 있는 네트워크에서 다시 activation이 0이 많아짐
- Normal Distribution in → Normal Distribution Out : 하지만, tanh activation을 취했을 때 0이 대부분, Std를 올리면, -1/1 값이 많이 나오는데 미분하면 0임
Q3. He Initialization를 한다는건 relu를 사용하기 때문이라고 생각하는데, 강의에서는 skip이 되기 때문에 he를 사용한다고 설명, relu때문이 아니라 skip때문인가?
- Relu가 많아서 사용한 듯하다. He가 아니면 Variance Controllability가 떨어짐

[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
speckle-meadow-e3a.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week7_Day31. Instance/Panoptic Segmentation (0) | 2021.09.27 |
|---|---|
| [BoostCamp] Week7_Day30. CNN Visualization (0) | 2021.09.27 |
| [BoostCamp] Week6_Day28. 팀원 찾기 (0) | 2021.09.21 |
| [BoostCamp] Week6_Day27. Image Classification (0) | 2021.09.19 |
| [BoostCamp] Week6_Day26. 양날의 검, Pseudo-labeling (2) | 2021.09.14 |
'Coding/BoostCamp' Related Articles
more



