
호기심 많은 분석가
[BoostCamp] Week4_Day15. P-Stage의 시작 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
🙋🏻♂️타운홀미팅
P-Stage가 시작하니만큼 우리가 모르는 여러 사항들이 있을 수 있으니, 오랜만에 타운홀미팅으로 한 주를 시작했다.
P-Stage에 대한 소개와 이번 주에는 어떤 일들이 있을지, AI Stage 사용법 등을 배웠다.
1. P Stage 소개
- Project - 대회 형 실습
2. P Stage 학습 안내
2-1. 학습 정리 제출
- '나는 어떤 방식으로 리더보드 점수를 올렸는지', '어제와 비교해서 무엇을 개선하고 시도해봤는지, 어떤 효과가 있었는지'도 포함해주시면 됩니다.
- 스스로 회고하는 것은 여러분의 소중한 기록이 됩니다.
2-2. Wrap UP 리포트
- P Stage 별 마지막 날에 학습 정리를 종합하여 프로젝트 결과와 함께 'Wrap UP 리포트'를 작성하여 제출
- (팀) 리포트 (분량 제한 2-3장) - 면접관이 봤을 때 어떤 대회를 진행했고, 어떤 모델링을 수행했는지 명확히 알 수 있도록 요약정리
- (팀) 대회 최종 코드
- (개인) 대회 회고글 (분량 제한: 1~3장)
- Wrap UP 리포트에는 모든 학습을 모아서, 하나의 논리적 구조로 연결하고, 회고해보며 느낀 점을 포함해주세요.
→ AI Stage 사용법을 개발자분들이 소개해주시고, 이번 이미지 분류 대회에 대한 설명이 주를 이뤘다.
📙개인학습
(1강) Competition with AI Stages!
김태진 - 번개장터, Kaggle Expert
What is P Stage?
"백문이 불여일견, 백견이 불여일타"
- 경진대회를 통한 프로젝트 실습
- U Stage에서 경험한 이론을 바탕으로 실제 데이터와 코드 베이스를 통한 이해
- 실습 위주의 Practical skills 학습
- Competition 형태의 실습을 통해 점진적인 모델 성능 향상을 경험
- 전처리, 학습, 추론까지 전체적인 과정
- 머신러닝 파이프라인의 한 부분을 경험
1. Competition with AI Stages
Overview를 꼭 봐야 한다. → 방향성을 제시
- 어떤 문제점이 야기되고, 그 문제점을 fancy 하게 해결할 수 없을까? 그것을 고민하는 것이 데이터 사이언티스트의 역할이다. Overview를 통해 어떻게 문제가 발생했고, 어떻게 해결할지를 고민하는 것 → 그것을 집요하게 들여다보는 습관이 중요
Overview Example

- Here’s the background: When the Conversation AI team first built toxicity models, they found that the models incorrectly learned to associate the names of frequently attacked identities with toxicity. Models predicted a high likelihood of toxicity for comments containing those identities (e.g. "gay"), even when those comments were not actually toxic (such as "I am a gay woman")
- 리플들을 분석해봤을 때 머신러닝을 이용하기엔 문제가 있더라, 잘못된 연관성을 학습했다. gay라는 단어가 언제나 나쁜 단어는 아닌데 그렇게 분류되는 게 난관이었다.
- 이런 동음이의어의 문제를 NLP적으로 어떻게 다루느냐가 핵심
- 이렇게 Overview를 읽어보면 내가 집중해야 할 핵심을 찾을 수 있다.
❗ 반드시 해야하는 것
Problem Definition (문제 정의)
- 내가 지금 풀어야할 문제가 무엇인가?
- 이 문제의 Input과 Output은 무엇인가?
- 이 솔루션은 어디서 어떻게 사용되어지는가?2. Data Description
- File 형태, Metadata Field 소개 및 설명 - "데이터 스펙 요약본"
- 읽다 보면 내가 모르는 용어들이 나올 텐데, 이것을 공부하는 것도 도메인 지식을 익히는 데 도움이 된다.
3. Discussion
- 등수를 올리는 것보다, 문제를 해결하고 싶은 마음 → 이게 우리는 잘 안된다. 노력해보자
Machine Learning Pipeline
- Simple Machine Learning Flow
- Competition의 경우
- 2가지를 제외한 많은 것들을 경험할 수 있음 → 그래서 P Stage는 Competition으로 선정
- Domain Understanging - Overview → 충분히 진행하고 넘어가자
(2강) Image Classification & EDA
- 이미지를 어떻게 class로 분류할 수 있을까
1. EDA (Exploratory Data Analysis)
탐색적 데이터 분석 - 데이터를 이해하기 위한 노력
- 어떤 인풋과 아웃풋을 가졌으며, 나는 어떤 것을 끌어내야 하고, 이 대회는 왜 열렸는 가 등등
- 내가 궁금한 사항들을 검증해보는 과정
- 도중에도 떠오르는 아이디어 때문에 다시금 확인해볼 필요가 생기기도 한다.
2. Image Classification
Image - 시각적 인식을 표현한 인공물 (Artifact)
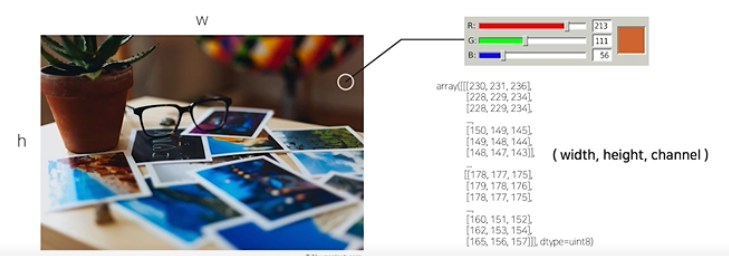
2-1. Model
결국 classification이라는 것은 input을 model에 넣어서 output을 뽑아내는 것

Special Mission - EDA
EDA 방법으로는 3가지 방법으로 나눌 수 있다.
- input이 될 X에 대한 분석
- target이 될 y에 대한 분석
- X, y 관계를 확인할 수 있는 분석
위 같은 케이스를 Image classification으로 가져온다면
- input이 될 X에 대한 분석 X는 Image가 된다. X에 대한 특성(feature)은 어떤 것이 있을까??
- 이미지 사이즈
- 분석 대상이 되는 객체의 위치
- RGB 채널별 통계 값
- target이 될 y에 대한 분석 y는 저희가 맞추고자 하는 값이며 y값에 대한 특성은 어떤 것이 있을까요??
- y값에 독립적 분포 확인 ex) y_1의 분포는?
- y값 들간의 관계 분포 확인ex) y_1, y_2 정보를 섞은 분포는?
- X, y 관계를 확인할 수 있는 분석 X특성과 y의 특성 간의 분포 차이는 어떻게 있을까요??
- 이미지 사이즈와 y 특성의 관계
- RGB 통계 값과 y 특성의 관계
- 객체의 위치와 y 특성의 관계
- 데이터의 노이즈 확인 ex) y 값이 잘못 부여된 것이 있을까??
위의 방향으로 고민하고, 실제 데이터에도 천천히 적용해보자
🕵🏻♂️마스크상태_분류 대회
1. Task Description
COVID-19의 확산으로 우리나라는 물론 전 세계 사람들은 경제적, 생산적인 활동에 많은 제약을 가지게
되었습니다. 우리나라는 COVID-19 확산 방지를 위해 사회적 거리두기를 단계적으로 시행하는 등의
많은 노력을 하고 있습니다. 과거 높은 사망률을 가진 사스(SARS)나 에볼라(Ebola)와는 달리
COVID-19의 치사율은 오히려 비교적 낮은 편에 속합니다. 그럼에도 불구하고, 이렇게 오랜 기간 동안
우리를 괴롭히고 있는 근본적인 이유는 바로 COVID-19의 강력한 전염력 때문입니다.
감염자의 입, 호흡기로부터 나오는 비말, 침 등으로 인해 다른 사람에게 쉽게 전파가 될 수 있기
때문에 감염 확산 방지를 위해 무엇보다 중요한 것은 모든 사람이 마스크로 코와 입을 가려서 혹시
모를 감염자로부터의 전파 경로를 원천 차단하는 것입니다. 이를 위해 공공 장소에 있는 사람들은
반드시 마스크를 착용해야 할 필요가 있으며, 무엇 보다도코와 입을 완전히 가릴 수 있도록 올바르게
착용하는 것이 중요합니다. 하지만 넓은 공공장소에서 모든 사람들의 올바른 마스크 착용 상태를
검사하기 위해서는 추가적인 인적자원이 필요할 것입니다.
따라서, 우리는 카메라로 비춰진 사람 얼굴 이미지 만으로 이 사람이 마스크를 쓰고 있는지, 쓰지
않았는지, 정확히 쓴 것이 맞는지 자동으로 가려낼 수 있는 시스템이 필요합니다. 이 시스템이
공공장소 입구에 갖춰져 있다면 적은 인적자원으로도 충분히 검사가 가능할 것입니다.2. Problem Definition (문제 정의)
- 내가 지금 풀어야 할 문제가 무엇인가?
- 이미지가 주어졌을 때, 마스크 착용 여부, 나이, 성별을 구분하여 정해진 라벨을 반환해야 한다.
- 이 문제의 Input과 Output은 무엇인가?
- Input은 Image, Output은 18개 클래스 중 하나
- 이 설루션은 어디서 어떻게 사용되는가?
- 공공장소 등 마스크 검사가 필요한 많은 곳에서 불필요한 자원 감소를 위해 사용될 것이다.
3. EDA
- 라벨 기준
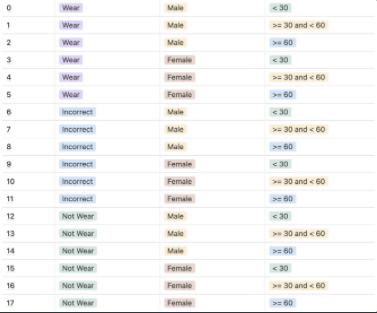
- 우리는 마스크 착용 여부, 성별, 나이를 분류할 것이다
- 한 번에 처리하는 모델도, 각각을 따로 처리하는 모델들을 결합하는 방법을 생각해볼 수 있다.
- 비교적 성별은 분류하기 쉬울 것이고, 마스크 착용 여부도 분류하기 쉬울 것이나, incorrect 즉 코스크나, 턱스크의 경우 구별하기 힘들 것으로 추정
- 데이터는 굉장히 일관적으로 잘 찍혀있고, 배경이 좀 있어 제거하는 것도 하나의 Key요소가 될 수 있지 않을까
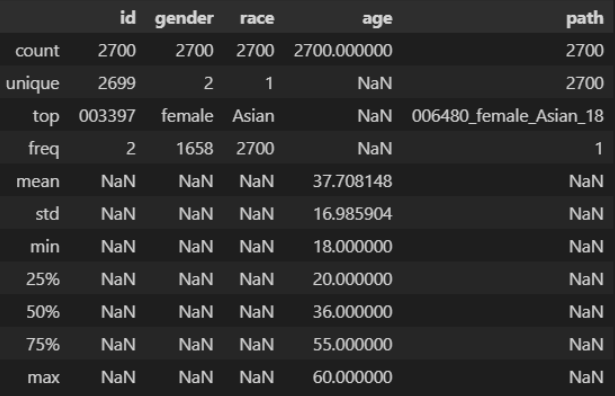
1. Data Info
- id의 경우 unique 해야 하는 데, 데이터에 오류가 있는 걸 확인
- Race는 우리에게 필요하지 않은 변수이므로 삭제
- Path는 데이터에 맞는 이미지의 경로 표시
- 라벨링이 되어 있지 않고, 심지어 이 데이터 프레임만 가지고는 라벨링을 구현할 수 없는 어려움에 당도
- 이런 경우 라벨링을 어떻게 해줘야 할지 몰라 어려움을 겪음
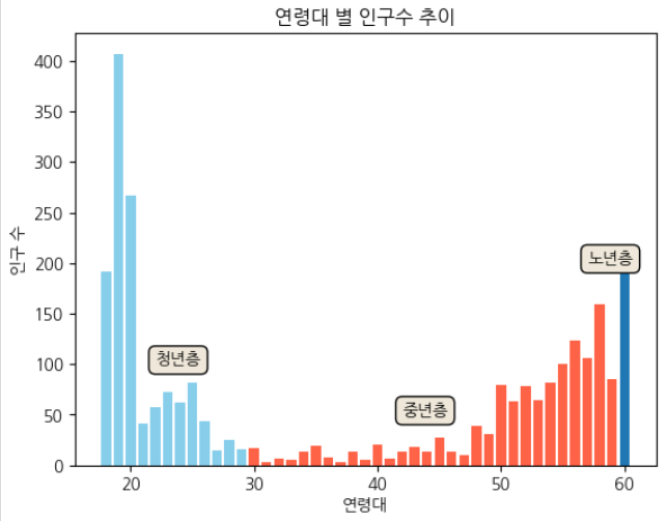
- 연령대별 인구수 추이
- 굉장히 극단적인 데이터가 많은 것을 판단할 수 있다.
- 30대 미만과 그 이후는 수월하게 구분 가능하지만, 50대와 60대의 분류에 어려움을 겪을 것으로 예상 → 신경 써주자
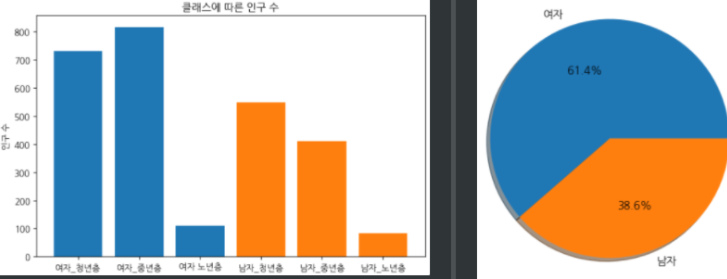
- 클래스에 따른 인구수 추이
- 여자의 수가 남자보다 많고, 청년층과 중년층의 순위가 다름을 확인
- 노년층의 경우 데이터가 너무 imbalanced 함을 알 수 있다 → 다른 조치 필요
4. 기타 사항
4-1. 협업
1. PyTorch Project template 사용
- Github으로 협업함은 물론이고 수업 때 배운 project template 사용을 하기로 함
- 처음 써보는 구조라 이것을 익히는 데 첫 날을 거의 다 보냄
GitHub - minsuk-sung/pytorch-deep-learning-template: PyTorch Deep Learning Template for Academic Purpose
PyTorch Deep Learning Template for Academic Purpose - GitHub - minsuk-sung/pytorch-deep-learning-template: PyTorch Deep Learning Template for Academic Purpose
github.com
2. Google Sheet
- 기본적으로는 제출한 내용과, 스코어, 변화된 내용, 파라미터 등을 기록하는 구글 시트를 만들어서 협업에 도움을 받고자 하였다. → 현재는 제출 내용이 없기에 작업 진행상황 기록

4-2. 서버 ssh 이용해서 VS code 연동
- 단비와 일하면서 배운 것들이 여러모로 유용하다.
👨👨👦👦 피어세션
굿모닝 세션 😉
- 1주 차 편하게 각자 진행
- 베이스라인 코드 나오면 다시 얘기해보기
- 강의 리뷰는 강의 들어보고 피어 세션 때 다시 얘기해보기
- 멘토님께 이번 주 피드백을 어떻게 할까요?
- 이미지 분류에 어떤 걸 쓰면 좋을지, 어떤걸 읽어보면 좋을지 여쭤보기.
- 강의 듣고 개별적으로 코드 작성
- 피어세션때 코드,강의관련해서 얘기
- 멘토님께 참고할만한 자료, 고려할만한 것들 여쭤보기.
피어세션 ☹️
0824 피어세션 : 오전 10시~ 11시 / 오후 17시 ~ 18시!
해보자 ~!
- wandb 써보기
- CutMix 써볼까?

- opencv에 눈, 코, 입 검출하는 게 있지 않나!
- 능력 닿으면 해 보겠습니다.
- 사진에서 얼굴 자르기(opencv facedetection), 18 vs 3, loss 클래스별로 가중치 주기,
50대 60대 나누기 힘들다. - 얼굴 자르기의 결과가 이상하다 싶으면 얼굴 안자르는 모듈로 하기
- 특정 % 이상 얼굴이라고 확신하면 그대로 학습 / 아니면 전체 이미지로
- 얼굴을 자른 이미지랑 안 자른 이미지 둘 다 활용하기
- →근데 얼굴 몹시 잘 잘릴 거 같다..
- Incorrect 분류가 어렵겠다.
내용
- 강의 리뷰보다 대회 토의하기
- 주영님 클래스 별로 디렉터리 나눈 거 확인.
- 스카프는 마스크인가.. → 맞다.
- vscode 연결하기.
- 깃으로 정리, 공유
- 피어세션 나눠서 하기 (오전 1시간 (10~11 시) ↔ 오후 1시간 (5~6 시))
- 얼굴 자르기 팀 ↔ 안 자르기 팀으로 나눠서 진행해보기?!
- 일단 첫 주차에는 개인별로 해보기?!
- 그 두 개 비교해야 되니깐 팀을 나눠보기?!
- 잘랐을 때와 안 자랐을 때 진행해야 되는 일이 많이 다를 경우 빨리 결정해야 하지만 그런 류의 일이 아니라서 빠르게 팀을 나눌 필요는 없지 않을까 싶습니다.
- → 팀 안 나누고 각자 하고 싶은 거 다해 보기!
- 학습을 어떻게 시켜야 할지 모르겠네요...
- 수요일에 각자의 코드 리뷰하기.
- 클래스에서 하이퍼 파라미터를 입력할 수만 있게 만들면 같이할 때 문제가 없지 않을까 싶습니다.
- 내일 만날 때는 그 템플릿에 대한 구조를 한 번 정리하고 시작할까요?
- 분류가 되는 원리가 뭘까?!
✍🏻학습회고
오늘은 부스트캠프를 시작하고 가장 힘든 날이 아니었을까. 이미지 분류 대회를 시작하게 되었는 데 이미지 데이터를 다뤄본 경험도 많지 않고, 베이스라인 코드도 없어서 어떻게 시작해야 할지 모르는 막막한 상태에 쳐해 있었다.
첨부된 train.csv를 EDA 하며 데이터가 좀 극단적이고, imbalanced 하며 오류도 꽤 있음을 발견했다. 그러고 캐글을 참고해서 여러 작업을 하려 했는데, 프로젝트 템플릿 형식으로 협업하자는 의견이 나왔다. 나에게는 너무 어려운 구조였다. 빠르게 모델을 생성하고 싶었는데, 협업이 더 중요하므로 오랜 시간 뜯어보다가 다른 팀원 한 분과 줌으로 함께 공부해서 익혔다. 힘들었지만 언젠가는 꼭 배웠어야 했고 사용할 프로세스이기 때문에 이번 기회를 통해 배워서 다행이다. 새로운 것을 더 열린 마음으로 편하게 받아들이는 마음을 키우자. 해서 못 배운 것이 없고 늘 잘 배우니까 뿌셔보자.🦾
이번 대회를 통해 많은 부분에서 성장할 것이 기대된다.😄
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
data-hun.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week4_Day17. 여러번의 실패와 깊은 이해 (0) | 2021.08.30 |
|---|---|
| [BoostCamp] Week4_Day16. 모델의 완성 (0) | 2021.08.27 |
| [BoostCamp] Week3_Day14. 첫 U-Stage를 마무리하며 (0) | 2021.08.24 |
| [BoostCamp] Week3_Day13. 따뜻한 피드백 (0) | 2021.08.21 |
| [BoostCamp] Week3_Day12. 역대 최고의 교육자료, Custom Model (0) | 2021.08.21 |



