
호기심 많은 분석가
[BoostCamp] Week3_Day13. 따뜻한 피드백 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개인학습
(06강) 모델 불러오기
💡 PyTorch 모델 저장 및 불러오는 방법과 이어 학습하기(Transfer Learning)를 학습- 요즘 딥러닝은 backbone, 즉 이미 학습이 되어있는 모델을 가져와서 우리 데이터에 맞춰서 다시 학습하는 fine tuning이 대세다.
- 이미지에서는 ResNet 계열들, NLP에서는 Bert 계열 모델들
우리는 학습 결과를 공유하고 싶다. 어떻게?
Tip. Colab에서 작업 끝나면 Slack으로 메세지 보내기
1. model.save()
- 학습의 결과를 저장하기 위한 함수
- 모델 형태 (architecture)와 파라미터를 저장
- 모델 학습 중간 과정의 저장을 통해 최선의 결과모델을 선택
- 만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
1-1. 모델의 파라미터를 표시
# Print model's state_dict
print("Model's state_dict:")
# state_dict : 모델의 파라미터를 표시
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
1-2. 모델의 파라미터를 저장
- 공유할 때는 이 방식을 주로 씀. architecture와 함께 저장하는 방식도 종종 쓰인다
- 코드도 함께 공유하기 때문에
# 모델의 파라미터만 저장 - Orderdict type
torch.save(model.state_dict(),
os.path.join(MODEL_PATH, "model.pt"))1-3. 같은 모델의 형태에서 파라미터만 load
- 당연히 동일한 모델이어야 함
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(
MODEL_PATH, "model.pt")))1-4. 모델의 architecture와 함께 저장, load
torch.save(model, os.path.join(MODEL_PATH, "model_pickle.pt"))
model = torch.load(os.path.join(MODEL_PATH, "model_pickle.pt"))- eval
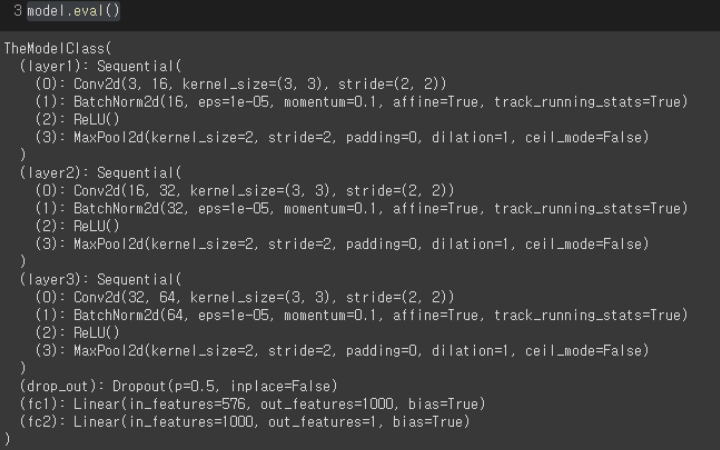
- Summary

2. Checkpoints
- 학습의 중간 결과를 저장하여 최선의 결과를 선택
- earlystopping 기법 사용시 이전 학습의 결과물을 저장
- loss와 metric 값을 지속적으로 확인 저장
- 일반적으로 epoch, loss, metric(Ex. Acc, F1-score,...)을 함께 저장하여 확인
- colab에서 지속적인 학습을 위해 필요

2-1. 모델의 정보 생성
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()2-2. 모델의 정보를 epoch과 함께 저장
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss,
}, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")
# 모든 모델을 저장할 필요는 없으니, 이전 epoch보다 좋아지면 저장한다던가,
# 5번 이상 성능이 좋아지지 않으면 멈춘다던가 하는 조건들을 걸어줄 수 있음2-3. 모델의 정보 load
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']- BCEWithLogitsLoss라는 loss function이 있는데, Binary Classification Cross Entropy를 의미, WthLogitsLoss를 하면 마지막에 sigmoid function을 달아줌
3. Pretrained model Transfer learning
남이 만든 모델을 쓰고 싶다
3-1. Transfer learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 일반적으로 대용량 데이터셋으로 만들어진 모델의 성능 ↑
- 현재의 DL에서는 가장 일반적인 학습 기법
- backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함


3-2. Freezing
- Pretrained model을 활용시 모델의 일부분을 frozen 시킴
- layer의 일부분을 frozen, 잠그고 나머지 layer에 대해서만 backpropagation 시행
- 학습시키고자 하지 않은 레이어는 가중치를 동결시켜서 연산량을 줄일 수 있음
- 한 이미지를 무작위로 변형하여 bottleneck를 여러 개 생성하면 augmentation의 효과를 낼 수 있다.
- layer의 일부분을 frozen, 잠그고 나머지 layer에 대해서만 backpropagation 시행

- 왜 freeze가 필요하고 어디에 사용할까?

- 1사분면
- 큰 데이터셋이 있으나, pre-trained된 모델이 학습한 데이터셋과 도메인이 다름 : frozen없이 전체 모델을 학습시킨다.
- 2사분면
- 큰 데이터셋이 있고, pre-trained된 모델이 학습한 데이터셋과 도메인이 비슷함 : CNN의 최상위 레이어 일부만을 훈련시킨다.
- 3사분면
- 작은 데이터셋이 있고, pre-trained된 모델이 학습한 데이터셋과 도메인이 다름 : 2사분면보다 더 많이 훈련시켜야 하고, augmentation을 고려할 것. 너무 많이 frozen을 푼다면, 과적합 가능성이 있음
- 4사분면
- 작은 데이터셋이 있고, pre-trained된 모델이 학습한 데이터셋과 도메인이 비슷함 : CNN이 추출한 특징을 분류할 새 분류기만 훈련시키면 됨
→ 도메인이 비슷하면 CNN을 최하위 레이어부터 많이 동결시켜도 되고, 도메인이 다르면 CNN을 덜 동결시켜야 한다. 데이터셋이 많으면 더 많은 Layer를 학습시켜도 과적합의 위험이 적다. 또한 freeze를 걸어줌으로써 연산량을 획기적으로 줄일 수 있다. 3사분면이 가장 작업이 어려울 듯하다.
3-3. pretrained model 사용하기
from torchvision import models
vgg = models.vgg16(pretrained=True).to(device)3-4. 모델에 마지막 Linear Layer 추가
- ImageNet 모델의 class는 1000개의 class를 맞추는 거지만, 우리는 지금 개or고양이를 맞추는 것이기 때문에 nn.Linear(1000, 1)을 해준다.
- 1000개의 출력을 이제 고차원의 feature를 다루는 layer의 출력이라고 생각할 수 있다. 1000개의 feature의 합으로 (1x1000 X 1000x1) 개와 고양이 2가지를 분류할 수 있을 것 → 이미 고양이와 개를 구분하게 학습되었기에 입력으로 개와 사람이 들어온다면 성능이 좋지 못할 것이다
- 왜 (1000, 2)가 아닌 (1000, 1)인가? → 하나의 값을 출력해서 1에 가까우면 강아지, 0에 가까우면 고양이로 분류해주기 때문, (1000, 2)를 사용해도 문제없다.
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)3-5. 마지막 레이어를 제외하고 frozen
- 이 코드 모델 부르고 밑에 같이 넣어줘야 한다.
# 모든 파라미터 frozen
for param in my_model.parameters():
param.requires_grad = False
# 학습을 시켜주고 싶은 linear_layer 부분만 True로
for param in my_model.linear_layers.parameters():
param.requires_grad = Truemy_model = MyNewNet()
my_model = my_model.to(device)
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(my_model.parameters(), lr=LEARNING_RATE)
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = my_model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()(07강) Monitoring tools for PyTorch
💡 Tensorboard, weight & biases를 학습합니다.
이를 통해 딥러닝 모델 학습 실험들을 파라미터와 Metric들을 자동으로 저장하는 실험
관리 프로세스를 익힐 수 있고, 코드 버저닝, 협업 관리, 더 나아가 MLOps의
전체적인 흐름을 확인할 수 있습니다.- 긴 학습 시간, 기다림의 기록이 필요 → 좋은 도구들이 많다. Tensorboard, Wandb
1. Tensorboard
- TensorFlow의 프로젝트로 만들어진 시각화 도구
- 학습 그래프, metric, 학습 결과의 시각화 지원
- PyTorch도 연결 가능 → DL 시각화 핵심 도구
# 표현 가능한 것
- scalar : metric(Acc, loss, Pre, Re) 등 상수 값의 연속(epoch)을 표시
- epoch 단위로 x축은 시간, y축은 scalar 값
- graph : 모델의 computational graph 표시
- histogram : weight 등 값의 분포를 표현
- image, text : 예측 값과 실게 값을 비교 표시
- mesh : 3d 형태의 데이터를 표현하는 도구1-1. Tensorboard 준비
- Tensorboard 기록을 위한 directory 생성
- 기록 생성 객체 SummaryWriter 생성
# Tensorboard 기록을 위한 directory 생성
import os
logs_base_dir = "logs"
os.makedirs(logs_base_dir, exist_ok=True)
# 기록 생성 객체 SummaryWriter 생성
from torch.utils.tensorboard import SummaryWriter
import numpy as np1-2. 값 기록
- SummaryWriter에 기록할 위치를 지정해줘서 writer를 만들어줌
- 그리고 writer.type를 반복해주고, 마지막에 flush나 close를 통해서 값 기록해줌
- add_scalar 함수 : scalar 값을 기록
- add_histogram 등 여러 정보를 추가 가능
- Loss/train : loss라는 category안에 train 값을 넣는다
- n_iter : x축의 값
- add_scalar 함수 : scalar 값을 기록
# SummaryWriter에 기록할 위치를 지정해줘서 writer를 만들어줌
writer = SummaryWriter(exp)
for n_iter in range(100):
# writer.type를 반복
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
# 값 기록
writer.flush()1-3. Tensorboard 띄우기
- 아래 방법을 사용하면 Port 6006으로 자동 생성됨
%load_ext tensorboard # jupyter 상에서 tensorboard 수행
%tensorboard --logdir {logs_base_dir}
# 파일 위치 지정 (logs_base_dir) 같은 명령어를 콘솔에서도 사용가능- random 값들이 잘 들어갔음을 확인할 수 있다.

- 우리가 만약 logs_base_dir로 설정한 경로에 여러 개의 log들을 만들어두면 여러 개의 그래프가 겹쳐 그려지게 된다.
- 왼쪽에 보이는 checkbox들로 보고 싶은 log를 골라서 볼 수 있음

- 아래와 같이 여러 개의 폴더를 한 번에 생성할 수도 있다
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(logs_base_dir)
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()- add_histogram
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter(logs_base_dir)
for i in range(10):
x = np.random.random(1000)
writer.add_histogram('distribution centers', x + i, i)
writer.close()- add_image
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img_batch = np.zeros((16, 3, 100, 100))
for i in range(16):
img_batch[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i
img_batch[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i
writer = SummaryWriter(logs_base_dir)
writer.add_images('my_image_batch', img_batch, 0)
writer.close()- add_hparams
- 하이퍼파라미터 저장해주는 건데 굉장히 중요할 듯
from torch.utils.tensorboard import SummaryWriter
with SummaryWriter(logs_base_dir) as w:
for i in range(5):
w.add_hparams({'lr': 0.1*i, 'bsize': i},
{'hparam/accuracy': 10*i, 'hparam/loss': 10*i})- torchvision.utils.make_grid(images)
- image를 넣어주면 알아서 grid까지 생성해주는 좋은 도구
- 이것 외에도 add_figure, add_pr_curve_tensorboard 등의 함수를 만들어서 사용할 수 있다. 이런 것들이 tensorboard에서 가능함을 알고 넘어가자
Weight & biases (WandB)
- 머신러닝 실험을 원활히 지원하기 위한 상용도구
- 협업, code versioning, 실험 결과 기록 등 제공
- MLOps의 대표적인 툴로 저변 확대 중
- 튜토리얼이 있으니까 참고하는 것도 좋음
!pip install wandb -q # wandb 설치
import wandb
# 아래 작업시 API Key를 요구하므로 Setting에서 찾아서 입력
# 프로젝트 이름 # 아이디, 팀 이름도 가능
wandb.init(project="my-test-project", entity='teamlab')
# config 설정, 아래 2개의 프로세르를 프로젝트 템플릿에서 바로 작동되도록 해두는 게 최상
config={"epochs": EPOCHS, "batch_size": BATCH_SIZE, "learning_rate" : LEARNING_RATE}
wandb.init(project="my-test-project", config=config)
# 아래와 같이 할 수 있다는 것도 알아만 두자
# wandb.config.batch_size = BATCH_SIZE
# wandb.config.learning_rate = LEARNING_RATE
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in train_dataset:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
train_loss = epoch_loss/len(train_dataset)
train_acc = epoch_acc/len(train_dataset)
print(f'Epoch {e+0:03}: | Loss: {train_loss:.5f} | Acc: {train_acc:.3f}')
# 기록하는 함수, tensorboard의 writer.add~~ 함수와 동일하다.
wandb.log({'accuracy': train_acc, 'loss': train_loss})- 프로젝트 템플릿이 tensorboard 기반인데 wandb를 사용하거나, 자체 dataloader들을 만들어보는 것을 추천
Wandb, 예전 가짜연구소 해커톤에서 소개받아서 사용해봤다. 역시 한 번이라도 들어본 것들은 왠지 모르게 친숙하고 쉽게 받아들여진다. 그래서 늘 새로운 것이 나오면 시도해보는 자세가 중요하다.
마스터클래스-최성철님
- 가천대학교 산업경영공학과 교수님
- 전 삼성전자 종합기술원 CTO 전략팀
- 모델 성능보다 데이터가 중심이다.

- 모델 개발 / 하이퍼파라미터 튜닝 싸움

- 현장의 ML 분야에서는 Scoping이랑 Deployment가 굉장히 중요하다
- 구글의 System 표, Code는 크게 중요하지 않다.

Data
- 실제 ML 프로젝트에서는 양질의 데이터 확보가 관건
- User generated data
- input, clicks for recommendataion
- System generated data
- logs, metatdata, prediction
- Data Flywheel (데이터 선순환)
- 사용자들의 참여로 데이터를 개선
- Data augmentation
- 데이터를 임의로 추가 확보
Data Feedback Loop
- 사용자로부터 오는 데이터를 자동화하여 모델에 피딩해주는 체계가 필요
- 단순히 ML/DL 코드로만 이루어지는 게 아님
- 네트워크 하드웨어부터 데이터 플랫폼까지의 이해
- 앞으로의 많은 ML/DL 엔지니어가 가져야 할 역량 중 하나
- 특히 대용량 데이터를 다뤄본 경험이 중요할 것
앞으로 알아야 할 것 들
- MLOPs 도구들
- 당연히 데이터베이스
- Cloud - AWS, GCP, Azure
- Spark (+Hadoop)
- Linux + Docker + 쿠버네티스
- 스케줄링 도구들 (쿠브플로우, MLFlow, AirFlow)
ML/DL 기획
- 앞으로 ML/DL 시스템은 다양한 영역에서 확장
- 데이터의 체계적 수립 (Feedback loop 체계 수립)
- 디지털화 but 데이터화 되어 있지 않은 데이터 변환
- 데이터가 있다고 했지만 막상 보면 pdf거나 jpg인 경우가 있다.
- MLOPs 엔지니어와 함께 AI 기반 시스템 설계 인력의 필요성이 증대
- 모델은 AutoML을 써도 되지만 기획은 인간의 영역 ( 프로세스, 데이터, 유저의 사용 방식에 대한 이해)
정리
- 앞으로는 알고리즘 연구자보다 ML/DL 엔지니어 필요성이 더 증대
- 단순히 ML/DL 코드 작성을 넘어서야 함
- 자동화하고 데이터와 연계, 실험 결과를 기반으로 설득, 시스템화
- 좋은 엔지니어이자 좋은 기획자적인 요소들이 필요
- 아직 AI화 되지 않은 영역의 AI화 (데이터를 어떻게 먹일 것인가!)
- Shell script, 네트워크, 클라우드 등 기본적으로 알아야 할 것들이 많음
- sc82.choi@gachon.ck.kr
Q&A
- 클론 코딩으로 많이 배우고 있습니다. 혹시 클론 코딩하면 좋을 유용할 자료를 알고 계실까요?
- hugging face 코드 많이 보심, 오래된 코드 말고 구글에서 만든 코드, 프로젝트 템플릿 코드
- CS 지식이 부족한 편인데, 취업을 하기에 CS의 어떤 부분이 가장 필요하고 빠르게 채워나갈 수 있는가?
- Linux, Database, Shell Script → Cloud → Docker → Spark
- 미래의 목표, Goal
- 알고리즘 쪽에 관심이 많은데 엔지니어 쪽을 공부해서 AI Systemwise한 처음부터 끝까지 기획부터, 시스템 배포까지 할 수 있는 엔지니어가 되고 싶습니다.
- 행복하게 살고 싶은데, 데이터를 만지니까 재밌더라. 이게 재밌을 때까지 해보고 싶다.
- 연구 경험이 중요할까요?
- 연구 경험 : 문제를 정의하고 해결한 문제
→ 비슷한 게 캐글 Competition, 깃헙에 정리하고 커뮤니티에 업로드한다.
- 연구 경험 : 문제를 정의하고 해결한 문제
이번 마스터 클래스는 현실편, 절망편이었달까 AI Engineer가 되기 위한 멀고도 험한 길들을 직시했다. 사실 데이터 분석가, 사이언티스트, 엔지니어를 꿈꾸고 있었지만 다 필요한 역량이다. 앞으로 강조하신 부분들 천천히 익혀나가야겠다.
멘토피드백_Week2

사실 주간멘토피드백은 저번 주부터 진행이 됐다. 하지만 저번 주는 굉장히 형식적이었는데, 멘토님께서 우리의 얼굴과 이름이 매칭이 안돼서 따로 피드백을 못주셨다고 한다. 🤣 그렇게 이번 주는 열심히 피드백해주시기로 했는데 블로그에 대한 따뜻한 피드백과 함께 논문 읽는 법에 대해 여쭤봤는데 친절하게 잘 설명해주셔서 정말 감사했다. 나도 영어 때문에 많은 고통을 받을 예정인데 저 사이트를 애용해야겠다. 감사합니다. 멘토님!
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
data-hun.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week4_Day15. P-Stage의 시작 (0) | 2021.08.25 |
|---|---|
| [BoostCamp] Week3_Day14. 첫 U-Stage를 마무리하며 (0) | 2021.08.24 |
| [BoostCamp] Week3_Day12. 역대 최고의 교육자료, Custom Model (0) | 2021.08.21 |
| [BoostCamp] Week3_Day11. PyTorch를 배워보자! (0) | 2021.08.17 |
| [BoostCamp] Data_Viz_1. Line Plot & Scatter Plot (0) | 2021.08.17 |



