
호기심 많은 분석가
[BoostCamp] Week4_Day16. 모델의 완성 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
🕵🏻♂️마스크상태_분류_대회
1. Data labeling
- 이미지는 18900장이 주어졌으나, train.csv의 row는 2700개뿐, 심지어 라벨링도 되어있지 않았다.
- 그래서 주최측이 정한 labeling 기준에 맞춰 train.csv를 18900개의 row와 18 종류의 class 값을 가지는 데이터프레임으로 변경시켜주었다.
- 우선 여기서 이미지 모델은 input때 train을 대체 어떻게 시켜주나 했는데, 정형 데이터와 비슷하게 DataFrame에서 label을 뽑아내고 그것에 해당하는 이미지를 tensor로 변환해서 넣어준다는 것을 배웠다. 사실 이 과정을 정확히 몰라서 어제는 이 작업을 진행하지 못했다. → 코드 공유를 보고 이런 식으로 해도 됨을 깨달았다.
2. Data Split
- 데이터 imbalancing을 해결하기 위해 sklearn의 StratifiedKFold를 사용해주고, ensemble해주었다.
- 이 과정에서 코딩 실수를 많이 해서 시간을 잡아먹었는데, 한 모델이 모든 fold들을 번갈아서 학습하면 과적합이 일어나니까, 5개의 모델이 각각 한 fold씩을 학습하는 방향으로 진행해야함
3. Model Train&Test
- 수업에서 배웠던 내용을 토대로 Dataset, Dataloader 구현하고, transforms, batch_size, lr, epoch, loss_function, optimizer 등을 구성하였다.
- 우리는 CrossEntropyLoss를 사용하는 데, 원래라면 CrossEntropyLoss를 softmax 취해준 뒤 argmax 값을 구해야하지만, 어차피 CrossEntropyLoss의 argmax와 softmax를 취한 값의 argmax가 동일하므로 굳이 softmax를 취해주지 않는다. But, 우리는 ensemble을 사용하기 때문에 각 모델마다 CrossEntropyLoss 값의 범위가 다를 수 있어 softmax를 취해줘야한다.
4. 기타 사항
4-1. Q&A
- Batch_size는 클수록 좋은가?
- 그렇지 않다. 적절한 Batch_size를 구해줘야 함. batch_size가 커질수록 일반화 성능이 줄어들기 때문
- GPU가 남음에도 불구하고 왜 num_workers가 다운되는가?
- shm 크기는 도커 컨테이너 실행시 --shm-size 라는 인자로 이미 결정이 되어서 GPU와 관계없이 그런 일이 벌어진다.
4-2. 배운 것과 사용할 것
- Wandb 사용해보자
- Black, isort
- 언제나 스윗하신 우리 멘토님, 생각보다 꽤 도움이 돼서 놀랐다.
설치도 사용도 간편한데 깔끔하게 잘 정리해준다
- 언제나 스윗하신 우리 멘토님, 생각보다 꽤 도움이 돼서 놀랐다.
- 윈도우에서는 폴더의 이름이나 사용자 이름이 한글로 지정되는 경우가 상당히 많은 데
그런 경우 git bash 에서 한글을 잘 읽지 못하는 현상이 발생한다.
이때는git config --global core.quotepath false를 입력해주시면 문제가 해결된다!
📙개인학습
(3강) Dataset
전처리의 개념, Generalization(일반화) 관점에서 생각해 볼 몇 가지 SkillVanila Data를 우리의 모델에 넣기 위해 여러 과정을 거쳐 Dataset을 생성해줌
1. Pre-processing(전처리)
- 가장 핵심이 되는 사진 → 실제 데이터는 노이즈가 너무 많기 때문
- 이미지 대회는 다행이도 이상치가 많지 않다.
- 이미지가 큰 경우나 용량이 큰 경우 처리가 어려움
- CV이기 때문에 회전하고, 색을 변환하고, Gaussian noise를 넣는 과정들의 이해가 필요하기 때문에 깊게 들어가면 어려울 수 있다.
- 모델에 좋은 데이터를 넣는 과정은 성능이 크게 바뀌므로 너무나도 중요하다. 그것이 수행되는 단계가 전처리 단계

1-1. Bounding box
- 가끔 필요 이상으로 많은 정보를 가지고 있기도 한다. → 우리 대회에도 진행해보자
- Tip. 우리 데이터는 정갈하기 때문에 일괄적으로 Crop하는 것을 추천한다.

1-2. Resize
- 계산의 효율을 위해 적당한 크기로 사이즈 변경
- 작업의 효율화, 적당한 화질이더라도 우리의 모델은 구분할 수 있기에 연산량을 높이기 위해 Resize 및 normalize를 시행

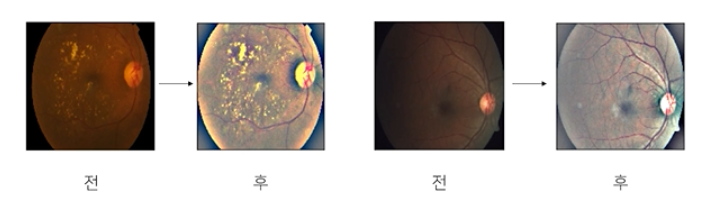
1-3. Example: APTOS Blindness Detection
- 도메인, 데이터 형식에 따라 정말 다양한 Case가 존재
- 특히 의학 이미지들은 전처리를 거쳤을 때 성능이 크게 바뀜
2. Generalization
- Dataset의 일반화를 어떻게 찾을 수 있을까, 어떤 의미가 있고 왜 중요한가
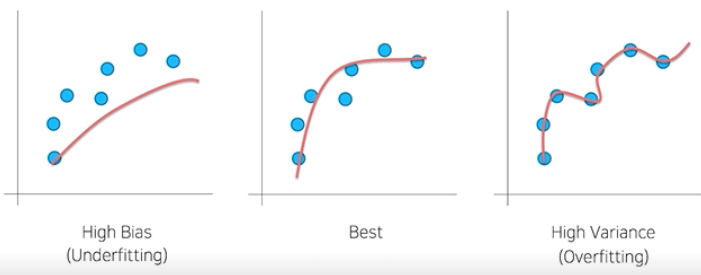
2-1. Bias & Variance
- 학습이 너무 안 됐거나, 학습이 너무 됐거나
2-2. Train / Validation
- 훈련 셋 중 일정 부분을 따로 분리, 검증 셋으로 활용
- 일반화 됐는 지 확인하기 위한 절차

2-3. Data Augmentation
- 주어진 데이터가 가질 수 있는 Case(경우), State(상태)의 다양성
- 문제가 만들어진 배경과 모델의 쓰임새를 살펴보면 힌트를 얻을 수 있다.
- Ex. 실내면 눈이나 비를 고려할 필요는 없다

torchvision.transforms
- image에 적용할 수 있는 다양한 함수들
- 사진을 찍을 경우 항상 정자세로 찍는건 아니니까, 하지만 Flip의 경우 우리가 사진을 뒤집어서 찍는 경우가 있나? → 이런 것들을 생각해줘야 함

- 종류는 많고, 사용은 간단하다.

- albumentations Library
- 더 다양하고, 더 빠르다.
- Single Core내에 통과시킨 갯수

'무조건'이라는 단어를 제일 조심하세요.
- 항상 좋은 결과를 가져다 주지는 않습니다.
이러한 함수들은 여러가지 **도구** 가운데 하나일 뿐입니다.
그리고, 무조건 적용 가능한 **마스터키 같은 것도 사실 없습니다.
앞서 정의한 Problem(주제)**을 깊이 관찰해서 어떤 기법을 적용하면 이러이러한 다양성을
가질 수 있겠다 가정하고 실험으로 증명해야 합니다.(4강) Data Generation
1. Data Feeding
- 모델에 먹이(Data)를 주다
- 먹이를 주다 = 대상의 상태를 고려해서 적정한 양을 준다
- 다른 예로 공장은 설계 → 제작 → 포장 과정을 거치는 데 생산량을 늘리기 위해서 제작 단계에서만 많이 찍어내면 될까? 그렇지 않지, 포장이 따라오지 않으면 생산량은 증대될 수 없음
- 혹시, 모델 학습을 할 때 비슷한 오류를 범하고 있진 않나요?
- Model의 초당 배치가 20이라면 Generator도 따라와야한다.
- 그래서 Data Generator의 성능을 확인해보는 것이 굉장히 중요함
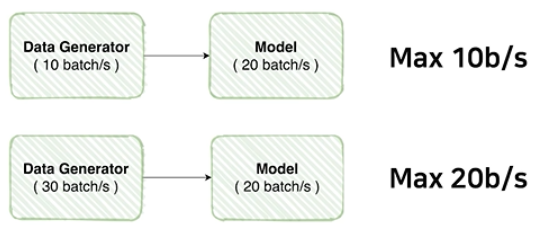
1-1. Dataset 생성 능력 비교
- Resize의 위치에 따라서도 속도가 굉장히 많이 변함, 300x300을 rotation하는 것과 1024x1024를 rotation하는 것의 계산량의 차이 → 순서도 확인해줘야한다.
for i, data in enumerate(tqdm(dataset)):
if i == 300 :
break
2. Datasets
- Dataset 구조 → 우리가 항상 MNIST와 같이 미리 준비된 데이터셋이 아니라 직접 만들어서 사용해야하기 때문에 Dataset 구조를 알아야 한다.
# torch.utils.data의 Dataset 라이브러리 상속
from torch.utils.data import Dataset
# import한 Dataset 상속해준 것, Dataset내에서 정의된 메소드들 사용할 수 있음
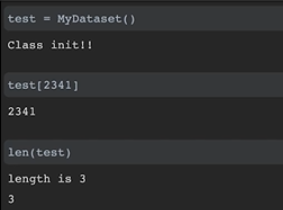
class MyDataset(Dataset):
# MyDataset 클래스가 처음 선언되었을 떄 호출
# 초기 설정해야하는 데이터의 위치라던가 절대적인 경로 등을 initialize해줌
def __init__(self):
print('Class init!!')
pass
# MyDataset의 데이터 중 index 위치의 아이템을 리턴
# list[1]처럼 대괄호의 역할을 해준다
def __getitem__(self, index):
return index
# MyDataset 아이템의 전체 길이 : 이건 넘을 수 없다
def __len__(self):
print('length is 3'
return 3- 데이터셋이라는 것을 클래스로 커스텀한다는 것은 위와 같이 Dataset을 해당 패키지 경로에서 import하여야하고 그 import한 데이터셋 Class를 내가 만든 Dataset에 상속해줘야함
- 상속 : 내가 만든 데이터셋 클래스가 상속받은 Dataset이라는 클래스와 비슷하다, Dataset 행세를 할 수 있다, 근데 행세를 하기 위해서는 PyTorch의 데이터셋이라면 마땅히 해야하는 건 할 수 있어야한다. 그것이 상단 코드의 3가지 함수이다.
- 파이썬 내부에 구현되어 있는 slicing과 len() 함수를 구현해줌으로써 pythonic하게 사용할 수 있다
3. DataLoader
- 내가 만든 Dataset을 효율적으로 사용할 수 있도록 관련 기능 추가
- 우리가 이제까지 어떻게 Dataset을 만들어내야하고, transforms를 어떻게 입히는 지 등 Dataset을 잘 구성을 했다. → 이걸 더 효율적으로 뽑아낼 수 있지 않을까? DataLoader

- 병렬 처리도 가능
- 한 번에 하나씩이 아닌 여러개 씩 작업해주기 위해 batch_size 설정
- 32나 64로 잘랐을 때 애매하게 남을 수가 있다, 그것을 살리기도 학습시키기도 애매한데 drop_last=True를 하면 그 데이터를 버릴 수 있음
- CPU는 데이터는 loader할 때, GPU는 그 데이터를 학습(계산)할 때 사용되기 때문에 두 개의 성능 모두 중요하다.
정리
Dataset과 DataLoader는 분리되는 것이 좋다.
- 엄연히 하는 일이 다르다.
- DataLoader는 하나만 만들어두면 Dataset을 바꿀 때마다 재사용할 수 있다.

👨👨👦👦피어세션
굿모닝 세션 😉
- 진행상황
황원상 기본적인 Dataset 클래스 구현
허정훈 EDA, Dasaset 클래스 구현
조현동 EDA 진행, 얼굴 segmentation 테스트 - opencv사용 - 1/60 정도는 안되더라
오주영 EDA, Dataset, Dataloader
이준혁 EDA, Dataset, Dataloader
임성민 EDA, 프로젝트 템플릿 검토 - 옷이나 배경으로 같은 사람임을 판단할 수 있을까
- 오버피팅되어 좋은 결과가 나오지 않을 것 같다
- 하지만 옷으로 나이대를 유추할 수 있지 않을까?
- 배경 제외하고 사람만 잘라보는 건 어떨까?
- cv를 이용해서 얼굴만 잘라보니 300장 정도가 안잘리더라.
- 흑백 전처리를 통해서 마스크를 쓴건지 안쓴건지 확인해보는건 어떨까
- 학습 loss 가중치 (클래스 별로 데이터 개수가 다른 것을 보정해주기 위해?)
어제 우리끼리 얘기 했던 것에 관해 공유 해주심
https://stages.ai/competitions/74/discussion/talk/post/432
가중치를 다르게 줄 수 있는 pytorch 코드를 공유 - image의 shape 변환시 transpose(또는 permute) 할지, 아니면 view 로 할지 고려하여야 한다. 두 결과는 다를 수 잇다.
참조 - https://qlsenddl-lab.tistory.com/37
굿에프터눈 세션 😊
- 진행상황
황원상 - Dataset KFold 고려하여 구현
이준혁 - DataLoader 구현
허정훈 - 저번주 선택과제의 resnet 모델 등을 활용하여 전체 분류 테스트 해봄
조현동 - Dataset 하다가 자료 탐색
임성민 - 클래스 라벨 만드는 알고리즘 작성
오주영 - ImageFolder이용하여 DataLoader 구현, MobileNet 이용하여 model 구현, balanced batch sampling 찾아보는 중, train 코드 작성하는 중 - 데이터를 각자 나누어 맞는지 점검하기로 함 일요일까지
오주영 0~ 449
허정훈 450~899
조현동 13501799
임성민 2250~2699 - KFold시 sklearn.model_selection의 StratifiedKFold 참고
✍🏻학습회고
어제 마스크 착용 상태 분류 대화가 시작되면서 늘 해오던 정형 데이터나 머신러닝 대회가 아닌 딥러닝을 이용한 이미지 분류 대회를 진행하게 되었다.
어젠 EDA에 그쳤지만 많은 아이디어를 빠르게 적용해보기 위해서는 모델을 만드는 게 최우선이었기에 모델 생성을 목표로 작업했다. 여러가지 문제가 있었는데 공유 게시판, 캐글, 과제의 도움을 받아 해결할 수 있었다. 이 과정에서 역시 해보기 전이 두렵지, 시작하고 나면 나는 뭐든 할 수 있는 사람이구나를 한번 더 깨닫았다. 예전 국가수리과학연구소의 캠프에서도 딥러닝을 다루면서 이 감정을 느꼈는데, 딥러닝이 접하기도 사용하기도 힘들다보니 해결했을 때 뿌듯함이 배가 된다.
프로젝트 템플릿, 모듈화, 내가 가장 못하고 두려워하던 작업들이었는데 협업을 위해 사용하다보니 조금 더 익숙해졌다. 고작 2일이지만 벌써 많은 걸 배웠다. 모델 생성까지 완료해서 첫 제출에는 accuracy가 30%였지만 StratifiedKFold, Epoch, batch_size, pretrained 조절들을 통해 73%까지 상승시켰다. 그 과정에서 헷갈리던 개념들을 직접 구현하고 틀려가면서 배웠고, 아직 모델 내부 구조 변경과 생각하던 아이디어 적용들이 남아있어 갈 길이 멀다. 팀원중에 한 분이 되게 내부적인 구조도 많이 아시는 데 열심히 배워야겠다.
나는 보통 협업을 진행할 때 서로 역할을 분담하고, 모르는 건 알려주면서 빠르게 익히고 속도를 높였는데, 이번 주차는 개인 제출의 주차이고 하고 싶은 걸 각자 해보자라는 의견이 주라 코드 공유만 하고 한 걸음 떨어져서 지켜보고 있다. 이런 대회와 작업이 처음이라 막막해하시는 팀원분들이 계신 것 같은데 도와드리고 싶지만 스스로 이겨내고자 하시는 것 같아서 묵묵히 응원중이다. 혼자서 많은 시간을 들여 고민하는 자세, 조금은 본받자.
오늘은 역시 나는 할 수 있다는 자신감, 아직 정확히 알지 못한다는 아쉬움, 더 노력해야겠다는 의지를 느끼며 내일은 또 어떤 작업을 하게 될까 기대한다.
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
data-hun.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week4_Day18. 여러가지 실험들 (0) | 2021.08.31 |
|---|---|
| [BoostCamp] Week4_Day17. 여러번의 실패와 깊은 이해 (0) | 2021.08.30 |
| [BoostCamp] Week4_Day15. P-Stage의 시작 (0) | 2021.08.25 |
| [BoostCamp] Week3_Day14. 첫 U-Stage를 마무리하며 (0) | 2021.08.24 |
| [BoostCamp] Week3_Day13. 따뜻한 피드백 (0) | 2021.08.21 |



