
호기심 많은 분석가
[BoostCamp] Week3_Day12. 역대 최고의 교육자료, Custom Model 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개인학습
(04강) AutoGrad & Optimizer
딥러닝은 결국 블록(layer)의 반복이다. layer안에는 작은 layer들이 모여있기도 함
torch.nn.Module
- 딥러닝을 구성하는 Layer의 base class
- Input, Output, Forward, Backward 정의
- Input과 Output은 optional하지만, 대부분 정의해준다.
- Forward, Backward 때 하는 일을 정해주는 데, AutoGrad와 weight를 조절해준다.
- 학습의 대상이 되는 parameter(tensor) 정의

nn.Parameter
모델을 구성하기 위해서는 학습의 대상이 되는 weight들을 정해야 하는데 weight들은 parameter라고 하는 Class에 정의를 한다. → Tensor 객체랑 상당히 비슷함
- Tensor 객체의 상속 객체
- nn.Module 내에 attribute가 될 때는 required_grad=True로 지정되어 학습 대상이 되는 Tensor → AutoGrad의 대상이 된다.
- 우리가 직접 지정할 일은 잘 없음
- 대부분의 layer에는 weights 값들이 지정되어 있다
class MyLinear(nn.Module) :
# input output
def __init__(self, in_features, out_features, bias=True) :
super().__init__()
self.in_features = in_features # 7
self.out_features = out_features # 5
# input으로 batch size 3짜리 7개의 feature(3x7)가 들어오고
# output으로 5개의 feature만 남기고 싶다면 weights를 7x5로 지정해줘야함
# 그래야 3x7 X 7x5 -> 3x5가 남으니까
self.weights = nn.Parameter(
torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, x : Tensor):
return x @ self.weights + self.bias # xW+b 형태Backward
- Layer에 있는 Parameter들의 미분을 수행
- Forward의 결과값 (model의 output=예측치)과 실제값 간의 차이(loss)에 대해 미분을 수행
- 해당 값으로 Parameter 업데이트
for epoch in range(epochs) :
# Clear gradient buffers because we don`t want any gradient from previous
# epoch to carry forward
# 이전의 gradient 값이 지금의 학습에 영향을 주지 않게하기 위해서 초기화
optimizer.zero_grad()
# get output from the model, given the inputs
outputs = model(inputs) # y hat
# get loss for the predicted output
loss = criterion(outputs, labels)
print(loss)
# get gradients w.r.t to parameters
loss.backward() # loss값을 w에 대해 미분값을 구해주는 것
# update parameters
optimizer.step()- torch.nn.Linear라는 명령어가 PyTorch에서 미리 구현해놓은 Lienar Regression 모델
- 홈페이지에 들어가서 Code level로 볼 것
- 우리는 y=2x+1 식을 구현할 거라 input dimension과 output dimension이 각각 1임
- [0,1,2,...,10] input과 [1,3,5,...21] output을 가지고 있다
- loss는 MSE, Optimizer는 SGD를 사용해주고, 대상이 되는 parameter는 model.parameter()
- requires_grad로 미분의 대상이 되는 값들을 확인할 수 있다
Backward from the scratch
- 실제 backward는 Module 단계에서 직접 지정 가능
- Module에서 backward와 optimizer 오버라이딩
- 사용자가 직접 미분 수식을 써야 하는 부담
- 쓸 일은 없으나 순서는 이해할 필요가 있다.
(05강) Dataset & Dataloader
모델의 중요성도 있지만 대용량 데이터는 어떻게 처리해서 학습시키느냐도 굉장히 중요한 이슈
- Dataset API를 이용해서 그 대용량 데이터를 처리할 수 있다
모델에 데이터를 먹이는 방법
- 우리가 모은 데이터를 가지고 Dataset이라는 Class를 이용해서 __init__시작할 때 어떻게 데이터를 불러올 건지, __len__길이는 얼만지, __getitem__map-style이라고 해서 하나의 데이터를 불러올 때 어떻게 반환해줄 건지
- map-style 데이터, 다른 언어의 map이 파이썬에서는 dictionary를 의미해서 key 값으로 뽑아올 수 있는 데이터를 말한다.
- 그다음 transforms을 이용해서 이미지 데이터를 전처리해주거나 데이터 augmentation을 할 때 ToTensor와 함께 tensor로 바꿔줌
- DataLoader라는 것은 데이터를 어떻게 처리할지 정했으면, 그것을 묶어서 Model에 Feeding 해줌, batch를 만들어주거나, shuffle을 해서 데이터를 섞어주거나
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 다른 입력 정의
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset): # 초기 데이터 생성 방법을 지정 (Image라면 data directory가 지정된다거나)
def __init__(self, text, labels):
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels) # 데이터의 전체 길이
def __getitem__(self, idx) : # index 값을 주었을 때 반환되는 데이터의 형태 (X, y)
label = self.labels[idx]
text = self.data[idx]
sample = {'Text': text, 'Class': label}
return sampleDataset 클래스 생성 시 유의점
- 데이터 형태에 따라 각 함수를 다르게 정의함
- 모든 것을 데이터 생성 시점에 처리할 필요는 없음
- Image의 Tensor 변화는 학습에 필요한 시점에 변환
- 데이터 셋에 대한 표준화된 처리방법 제공 필요
- 후속 연구자 또는 동료에게는 빛과 같은 존재
- 최근에는 HuggingFace 등 표준화된 라이브러리 사용
DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
- DataLoader는 iterable한 객체기 때문에 iter 명령어를 사용해서 generator로, 그다음 next를 사용해서 다음 데이터를 추출해준다.
- collate_fn은 아래와 같이 Data, Label을 마지막 그림처럼 변환시켜주는 명령어이다.
- Variable length 가변인자 처리할 때 주로 사용함
- 값들에 0으로 패딩을 해줘야 할 때가 있다. 그때 각각의 x 데이터 동일하게 패딩을 하기 위해 collate_fn에 정의함

Casestudy
- 데이터 다운로드부터 loader까지 직접 구현해보기
- torchvision의 dataset visiondataset을 가면 굉장히 많은 데이터가 있다
- 여기에서 클론 코딩해보는 것을 추천
과제 1. Custom Model 제작
이제까지 과제 중 가장 정성이 많이 들어가 있고, 앞으로도 이만큼의 정성 가득한 과제가 있을까 싶다. 부덕이와 함께 Custom Model을 만들어보자.
- 우리는 PyTorch의 공식문서에 대해 공부해볼 것
PyTorch documentation — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
🌓 1. Document 읽기
- torch 문서 읽기
- "Tensors"라는 이름을 보며 추측해봤는데 tensor 자료구조를 생성하거나 관련된 특성을 추출할 수 있는 함수들이 모여있을 것 같다.
- torch.numel() - 전체 element의 숫자 반환
1-1. Creation Ops
이름에서 "Tensors"라는 자료구조를 만드는 함수임을 유추 (Operations)
import torch
import numpy as np
a = np.array([1, 2, 3])
# torch.[from_numpy](https://pytorch.org/docs/stable/generated/torch.from_numpy.html#torch.from_numpy) - ndarray -> tensor
t = torch.from_numpy(a)
t # tensor([1, 2, 3])
# torch.[zeros](https://pytorch.org/docs/stable/generated/torch.zeros.html#torch.zeros) - input shape의 zero tensor 생성
torch.zeros(2, 3)
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
# torch.[zeros_like](https://pytorch.org/docs/stable/generated/torch.zeros_like.html#torch.zeros_like) - input과 같은 shape의 zero tensor를 반환
torch.zeros_like(t) # tensor([0, 0, 0])1-2. Indexing, Slicing, Joining, Mutating Ops
import torch
import numpy as np
# torch.[chunk](https://pytorch.org/docs/stable/generated/torch.chunk.html#torch.chunk) - chunk개수로 tensor를 split
t = torch.tensor([[1, 2, 3],
[4, 5, 6]])
print(torch.chunk(t, 2, 0)) # (tensor([[1, 2, 3]]), tensor([[4, 5, 6]]))
print(torch.chunk(t, 2, 1)) # (tensor([[1, 2], tensor([[3],
# [4, 5]]), [6]]))
# torch.[swapdims](https://pytorch.org/docs/stable/generated/torch.swapdims.html#torch.swapdims) - transpose의 Alias
x = torch.tensor([[[0,1],[2,3]],[[4,5],[6,7]]])
x
# tensor([[[0, 1],
# [2, 3]],
# [[4, 5],
# [6, 7]]])
torch.swapdims(x, 0, 1)
# tensor([[[0, 1],
# [4, 5]],
# [[2, 3],
# [6, 7]]])
torch.swapdims(x, 0, 2)
# tensor([[[0, 4],
# [2, 6]],
# [[1, 5],
# [3, 7]]])1-2-1. 인덱싱 (Indexing)
- 파이썬에서 list를 indexing 하는 것과 어떻게 다를까?
#[[1 2]
# [3 4]] 라는 2차원 텐서에서 [1 3]이라는 값만 추출하자
import torch
A = torch.Tensor([[1, 2],
[3, 4]])
# 1. index_select (input, dimension, index), view≈reshape
torch.index_select(A, 1, torch.tensor([0])).view(1, -1)
# 2. list indexing
A[:, 0]🤔gather
- 조금 더 학습해보자
torch.gather — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
🤔Scatter - Gather의 역연산
torch.Tensor.scatter_ — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
# torch.Tensor.scatter_
src = torch.arange(1, 11).reshape((2, 5))
src
# tensor([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10]])
# 🦆 우리가 함께 공부했던 gather와 비슷한 느낌이 나요!
index = torch.tensor([[0, 1, 2, 0]])
torch.zeros(3, 5, dtype=src.dtype).scatter_(0, index, src)
# tensor([[1, 0, 0, 4, 0],
# [0, 2, 0, 0, 0],
# [0, 0, 3, 0, 0]])
index = torch.tensor([[0, 1, 2], [0, 1, 4]])
torch.zeros(3, 5, dtype=src.dtype).scatter_(1, index, src)
# tensor([[1, 2, 3, 0, 0],
# [6, 7, 0, 0, 8],
# [0, 0, 0, 0, 0]])Random Sampling
Reproducible PyTorch를 위한 randomness 올바르게 제어하기!
PyTorch 코드의 완벽한 재현을 위해 고려해야할 randomness를 제어하는 법을 설명드리겠습니다.
hoya012.github.io
- 우리가 사용하는 random과 관련 있는 기능들은 다 난수 발생기, Random Number Generator(RNG)를 통해 생성된 난수를 기반으로 구현되어 있다. 이때, 이 난수 발생기에는 random seed를 설정할 수 있고, 그러면 매번 같은 순서로 난수가 발생하게 된다.
- 하지만 PyTorch에는 random과 관련된 요소가 여러 개 존재해서, 각각의 요소들이 무엇인지 살펴보고, 각 요소들의 randomness를 제어해보자
우리가 사용하는 메인 프레임워크인 PyTorch의 random seed를 고정할 수 있다.
torch.manual_seed — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
import torch
torch.manual_seed(1996)
# numpy의 random seed 고정
import numpy as np
np.random.seed(1996)
# CuDNN random seed 고정 -> 연산 처리 속도가 조금 감소한다
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# python random Library 고정
import random
random.seed(1996)
torch.cuda.manual_seed(1996)
torch.cuda.manual_seed_all(1996) # if use multi-GPUtorch.seed — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
# torch.seed() - 난수를 생성하기 위한 시드를 비결정적 난수로 설정, 64bit
torch.seed() # 13544004746868985207
torch.get_rng_state — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
# get_rng_state - 난수생성기의 상태를 출력
# 저장해두면 set_rng_state로 동일한 조건 반환 가능
torch.get_rng_state() # tensor([204, 7, 0, ..., 0, 0, 0], dtype=torch.uint8)1-2-2. Math operations
- addcdiv
- $out_i = input_i+value\times\frac{tensor1_i}{tensor2_i}$
t = torch.randn(1, 3) # tensor([[-0.7723, 1.2713, 0.2101]])
t1 = torch.randn(3, 1) # 3x1 tensor
t2 = torch.randn(1, 3) # 1x3 tensor
torch.addcdiv(t, t1, t2, value=0.1)
# tensor([[-0.7495, 1.3169, 0.2160],
# [-0.7220, 1.3719, 0.2230],
# [-0.6057, 1.6044, 0.2528]])- clamp
- random 값을 모두 min과 max 값 사이에 위치하도록 변환
a = torch.randn(4)
a
torch.clamp(a, min=-0.5, max=0.5)
# tensor([ 0.0478, 0.5000, -0.5000, -0.5000])- deg2rad - 이름만 봐도 어떤 함수인지 알 수 있음
a = torch.tensor([[180.0, -180.0], [360.0, -360.0], [90.0, -90.0]])
torch.deg2rad(a)
# tensor([[ 3.1416, -3.1416],
# [ 6.2832, -6.2832],
# [ 1.5708, -1.5708]])2. Container
- nn.Linear(3)과 nn.Linear.forward(3)이 동일하다고 함
- 상속하는 순간 caller함수가 불러와지는데, 그때 forward가 자동으로 실행되기 때문
- 그래서 forward가 아닌 다른 문자를 쓰면 작동하지 않는다.
2-1. Sequential
- 모델을 묶어 순차적으로 실행시키고 싶을 때
class Add(nn.Module):
def __init__(self, value):
super().__init__()
self.value = value
def forward(self, x):
return x + self.value
calculator = nn.Sequential(
Add(3),
Add(2),
Add(5)
)
x = torch.tensor([1])
calculator(x)
# 이렇게 모델을 짜주면 1+3+2+5 모델이 생성된다.2-2. ModuleList
- 리스트처럼 모아 두고 그때그때 원하는 것을 인덱싱하여 쓰고 싶을 때
class Calculator(nn.Module):
def __init__(self):
super().__init__()
self.add_list = nn.ModuleList([Add(2), Add(3), Add(5)])
def forward(self, x):
for i in range(len(self.add_list)) :
x = self.add_list[i](x)
return x- ModuleDict
- dictionary처럼 key값을 이용해 가져오고 싶을 때
class Calculator(nn.Module):
def __init__(self):
super().__init__()
self.add_dict = nn.ModuleDict({'add2': Add(2),
'add3': Add(3),
'add5': Add(5)})
def forward(self, x):
x = self.add_dict['add2'](x)
x = self.add_dict['add3'](x)
x = self.add_dict['add5'](x)
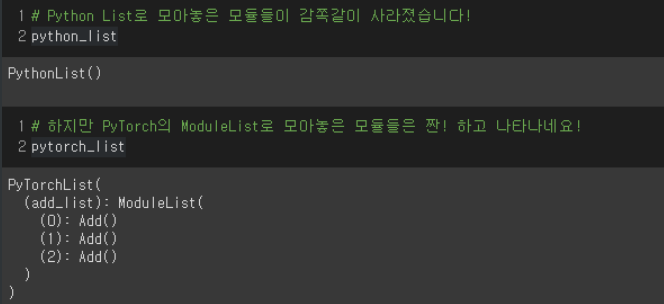
return x- 왜 파이썬에도 List가 있는데 굳이 PyTorch에서는 ModuleList를 별도로 만들었을까요?
- list로는 하위 모듈이 보이지 않지만, ModuleList로는 확인 가능하기 때문
- linear transformation인 Y = XW+b에서 W, b는 어떻게 만드는가?
- Parameter(torch.ones(out_features, in_features)) - 1로 초기화한 것
- 그렇다면 왜 굳이 tensor가 아닌 Parameter를 사용하는가?
- Parameter를 이용해서 W, b를 만들 경우에만 output tensor에 gradient를 계산하는 함수인 grad_fn이 생성됨
- 그리고 linear_parameter.state_dict()로 W, b를 뽑아낼 수 있다.
- 하지만 tensor는 두 개 다 안 됨
- Tensor
- gradient 계산 x
- 값 업데이트 x
- 모델 저장 시 값 저장 x
- Parameter
- gradient 계산 o
- 값 업데이트 o
- 모델 저장 시 값 저장 o
- Buffer
- gradient 계산 x
- 값 업데이트 x
- 모델 저장시 값 저장 o
- self.register_buffer('buffer', torch.Tensor([7]))으로 변수 등록 가능
- model.get_buffer('buffer')를 통해 값 추출 가능
3. Module 출력 내용 변경하기
우리는 Function_A()가 Function_A(name=duck)으로 나오길 바란다.
어떻게 해줄 수 있을까?- extra_repr를 사용해보자. repr 자체를 변경해줄 경우 children 등에 문제가 생길 수 있으니 extra_repr만 고쳐주는 것이 최상책

- repr는 원래 선언되므로 아래와 같이 코드를 생성해준다.
# Class 내부에서 추가 함수 정의
def extra_repr(self) :
return f'name={self.name}'☄️ 4. nn.Module 알쓸신잡
4-1. hook
- 패키지화된 코드에서 다른 프로그래머가 custom 코드를 중간에 실행시킬 수 있도록 만들어놓은 인터페이스
- 프로그램의 실행 로직을 분석하거나
- 프로그램에 추가적인 기능을 제공하고 싶을 때 사용
- Package는 원래부터 self.hooks라는 변수를 가지고 있다.
- 그래서 Package를 실행하면 패키지에 포함된 프로그램을 하나씩 실행하는 중간중간 self.hooks에 등록된 함수가 있는지 체크하게 되는 것
class Package(object):
"""프로그램 A와 B를 묶어놓은 패키지 코드"""
def __init__(self):
self.programs = [program_A, program_B]
self.pre_hooks = []
self.hooks = []
def __call__(self, x):
for program in self.programs:
# pre_hook : 프로그램 전에도 실행 가능
if self.pre_hooks:
for hook in self.pre_hooks:
output = hook(x)
if output:
x = output
x = program(x)
# Package를 사용하는 사람이 자신만의 custom program을
# 등록할 수 있도록 미리 만들어놓은 인터페이스 hook
if self.hooks:
for hook in self.hooks:
output = hook(x)
# return 값이 있는 hook의 경우에만 x를 업데이트 한다
if output:
x = output
return x
# Hook - 프로그램의 실행 로직 분석 사용 예시
def hook_analysis(x):
print(f'hook for analysis, current value is {x}')
# 생성된 패키지에 hook 추가
package.hooks = []
package.hooks.append(hook_analysis)
# 패키지 실행
input = 3
output = package(input)
print(f"Package Process Result! [ input {input} ] [ output {output} ]")
# program A processing!
# hook for analysis, current value is 6
# program B processing!
# hook for analysis, current value is 3
# Package Process Result! [ input 3 ] [ output 3 ]💡 PyTorch의 hook은 어떤 것들이 있을까? 크게 아래 2가지로 나뉜다고 한다.
- Tensor에 적용하는 hook
- Module에 적용하는 hook
🦆
Tensor에 등록하는 hook의 경우에는 '_backward_hooks'에서 확인할 수 있는데,
Module과는 다르게 Tensor에는 backward hook만 있다.
# register_hook로 사용
# tensor._backward_hooks로 확인 가능
nn.Module에 등록하는 모든 hook은 '__dict__'을 이용하면 한번에 확인이 가능하다
# 명령어
- register_forward_pre_hook
- register_forward_hook
- register_backward_hook
- register_full_backward_pre_hook
# __dict__ 결과
- forward_pre_hooks
- forward_hooks
- backward_hooks # deprecated
- full_backward_hooks
- state_dict_hooks # "load_state_dict" 함수가 내부적으로 사용
forward_pre_hook -> forward -> forward_hook
register_backward_hook은 대체되니 사용하지말자 -> register_full_backward_pre_hooktorch.Tensor.register_hook — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
Invoking Time of nn.Module _register_state_dict_hook()
Below is the source code of _register_state_dict_hook I quoted from official Pytorch nn.Module def _register_state_dict_hook(self, hook): r"""These hooks will be called with arguments: `self`, `state_dict`, `prefix`, `local_metadata`, after the `state_dict
discuss.pytorch.org
Useful hook
- gradient 값의 변화를 시각화
- gradient 값이 특정 임계값을 넘으면 gradient exploding 경고 알림
- 특정 tensor의 gradient 값이 너무 커지거나 작아지는 현상이 관측되면 해당 tensor 한정으로 gradient clipping
How to Use PyTorch Hooks
PyTorch hooks provide a simple, powerful way to hack your neural networks and increase your ML productivity.
medium.com
Debugging and Visualisation in PyTorch using Hooks
In this post, we cover debugging and Visualisation in PyTorch. We go over PyTorch hooks and how to use them to debug our backpass, visualise activations and modify gradients.
blog.paperspace.com
4-2. apply
- apply를 통해 적용하는 함수는 module을 입력으로 받는다
- 모델의 모든 module들을 순차적으로 입력받아서 처리한다.
- Postorder Traversal 방식으로 module들에 함수를 적용
- 일반적으로 가중치 초기화 (Weight Initialization)에 많이 사용한다.
피어세션
Q1. requires_grad = True 로 놨을 때, optimizer.step을 해도 역전파가 잘 일어나나??
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
opt = torch.optim.SGD({a, b}, lr = 0.0001)
opt.step()
print(a, b)
다음과 같은 예시를 돌려보았을때 역전파가 일어난다.Q2. class model, def forward에서 forward가 아닌 다른 method명으로 정의해도 model(x)가 작동하나??
안한다 nn.module을 상속받기때문에 함수가 호출될 때 자동으로 forward함수가 호출되게됨Q3. dataset 정의할 때, __ getitem __ 메소드와 dataset[i]와 같이 작동하는가???
A. 그렇다.
Writing Custom Datasets, DataLoaders and Transforms — PyTorch Tutorials 1.9.0+cu102 documentation
Note Click here to download the full example code Writing Custom Datasets, DataLoaders and Transforms Author: Sasank Chilamkurthy A lot of effort in solving any machine learning problem goes into preparing the data. PyTorch provides many tools to make data
pytorch.org
프로그래머특강2
1. Unit Tests
- Good reasons to test
- Regression : "When you fix one bug, you introduce several newer bugs"
- 그래서 Unit Test, TDD를 반드시 해야 한다.

1.2 Testing Terminology
- 고객에게 넘겨줄 때 같이 가는 코드가 Production Code
- 그전에 Production Code가 제대로 작동하는지 확인하는 것이 Unit Test, Integration Test
- Unit Test : Dependency가 없는 코드들, 내 코드의 문제만 해결하면 된다.
- 그전에 Production Code가 제대로 작동하는지 확인하는 것이 Unit Test, Integration Test
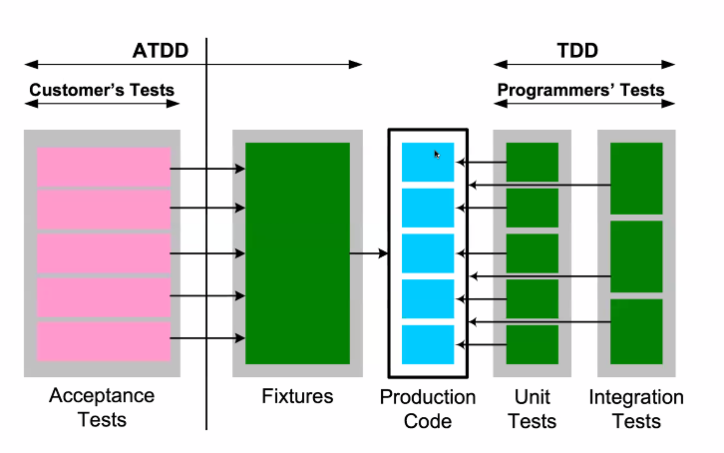
1.3 Maturity model
- Manual testing
- Automated testing
- Test-first development
- Test-drive development
- 이것만 하면 된다.
- Write tests that describe behavior
- Implement a system that has that behaviour
1.4 TDD
- RED : Write a failing unit test
- GREEN : Write production code to make test pass
- REFACTOR : Remove duplication and improve design*
Python Unit test
2.1 Hello TDD!
- Step 1 : Import the unittest module in your program
- Step 2 : Create a testcase by subclassing
- Step 3 : Define a test as a method inside the class. Name of method must start with 'test'
import unittest
def add(x, y) : # 처음에는 이것없이 실행한다. 그러면 당연히 Fail 뜸
return x+y # 그러면 그 Fail을 함수를 만듦으로써 해결하자
class SimpleTest(unittest.TestCase):
def testadd(self):
self.assertEqual(add(4, 5), 9)
if __name__ == '__main__' :
unittest.main()Machine Learning Unit Tests
3.2 Function
- Compose method pattern
- Extract method
3.3 Is obvious or not??
- Obvious : compare with expected results
- Not : measure changes
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3oC70G9
www.notion.so
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week3_Day14. 첫 U-Stage를 마무리하며 (0) | 2021.08.24 |
|---|---|
| [BoostCamp] Week3_Day13. 따뜻한 피드백 (0) | 2021.08.21 |
| [BoostCamp] Week3_Day11. PyTorch를 배워보자! (0) | 2021.08.17 |
| [BoostCamp] Data_Viz_1. Line Plot & Scatter Plot (0) | 2021.08.17 |
| [BoostCamp] Data_Viz_1. 시각화의 기본, Bar Plot (0) | 2021.08.15 |



