
호기심 많은 분석가
랜덤포레스트(Random Forest) 본문
1. 배깅(Bagging)이란?
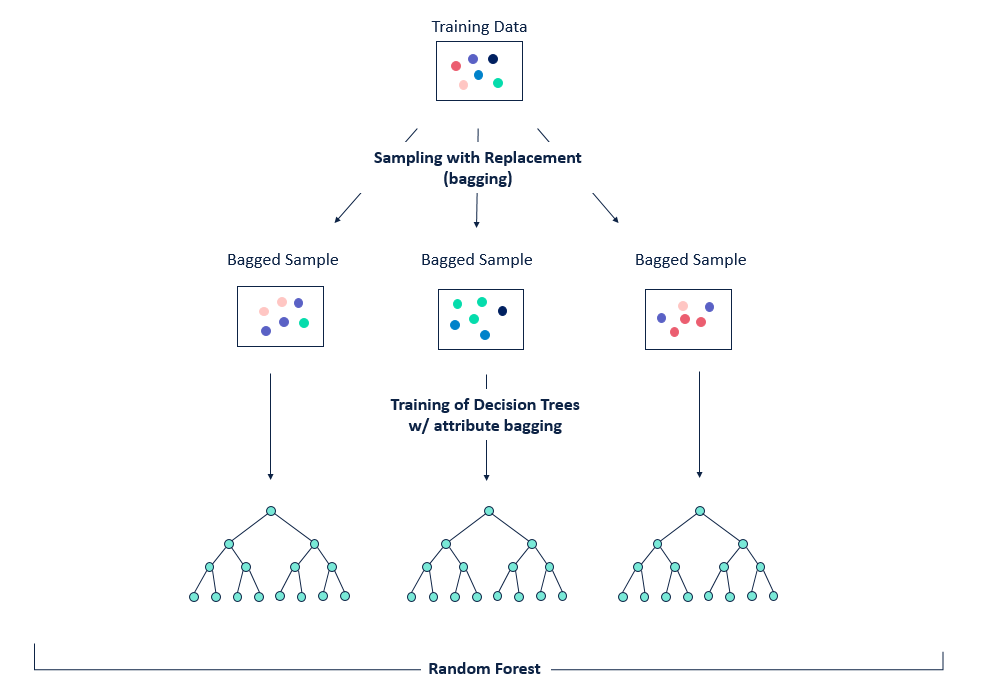
배깅(Bagging)은 Bootstrap Aggregating의 약자로, 보팅(Voting)과는 달리 동일한 알고리즘으로 여러 분류기를 만들어 보팅으로 최종 결정하는 알고리즘이다.
- 베깅은 다음과 같은 방식으로 진행이 됩니다.
- 동일한 알고리즘을 사용하는 일정 수의 분류기 생성
- 각각의 분류기는 부트스트래핑(Bootstrapping) 방식으로 생성된 샘플 데이터를 학습
- 최종적으로 모든 분류기가 보팅을 통해 예측 결정
- 부트스트래핑 샘플링은 전체 데이터에서 일부 데이터의 중첩을 허용하는 방식

- 보팅이란? 다른 알고리즘 model을 사용하는 점에서 차이가 있다.
2. 랜덤포레스트(RandomForest)
랜덤포레스트는 여러 개의 결정트리(Decision Tree)를 활용한 배깅 방식의 대표적인 알고리즘
장점
- 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있음
- 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있음
- 다양한 분야에서 좋은 성능을 나타냄
단점
- 하이퍼 파라미터가 많아 튜닝을 위한 시간이 많이 소요됨
3. 랜덤포레스트 하이퍼 파라미터 튜닝
랜덤포레스트는 트리 기반의 하이퍼 파라미터에 배깅, 부스팅, 학습, 정규화 등을 위한 하이퍼 파라미터까지 추가되므로 튜닝할 파라미터가 많습니다.
| 파라미터 명 | 설명 |
| n_estimators | - 결정트리의 갯수를 지정 - Default = 10 - 무작정 트리 갯수를 늘리면 성능 좋아지는 것 대비 시간이 오래 걸림 |
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터 수 -> 과적합 제어하는 데 사용 - Default =2 -> 작게 설정할 수록 분할 노드가 많아서 과적합 가능성 증가 |
| min_samples_leaf | - 리프노드가 되기 위해 필요한 최소한의 샘플 데이터 수 - min_samples_split과 함께 과적합 제어 용도 - 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작세 설정 필요 |
| max_features | - 최적의 분할을 위해 고려할 최대 feature 갯수 - Default = 'auto' (결정트리에서는 default가 none이었음) - int형으로 지정 -> feature 갯수 / float형으로 지정 -> 비중 - sqrt 또는 auto : 전체 feature 중 √(feature갯수) 만큼 선정 - log : 전체 feature 중 log2(전체 feature 갯수) 만큼 선정 |
| max_depth | - 트리의 최대 깊이 - default = None -> 완벽하게 클래스 값이 결정될 때까지 분할 또는 데이터 갯수가 min_samples_split보다 작아질 때까지 분할 - 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요 |
| max_leaf_nodes | - 리프노드의 최대 갯수 |



'Coding > Machine Learning & Python' 카테고리의 다른 글
| [Machine Learning] LightGBM, LGBM에 대해 알아보자 (0) | 2021.05.18 |
|---|---|
| [Machine Learning] 카테고리 변수를 다루는 법 (2) | 2021.05.12 |
| [Python] ImportError : cannot import name 'function' from 'module' (location) 발생 시 (0) | 2021.05.04 |
| [Python] 파이썬(Python) Flask로 웹서버에서 ML model 적용시키기 (2) (0) | 2021.05.04 |
| [Python] 파이썬(Python) Flask로 웹서버에서 ML model 적용시키기 (1) (0) | 2021.05.04 |
'Coding/Machine Learning & Python' Related Articles
more



