
호기심 많은 분석가
[BoostCamp] Week6_Day26. 양날의 검, Pseudo-labeling 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
개인학습
(02강) Annotation Data Efficient Learning
컴퓨터 비전 문제를 푸는 딥러닝 모델은 supervised learning으로 학습하는 것이 유리하다는
사실은 알려져 있습니다.하지만, 딥러닝 모델을 학습할 수 있을 만큼 고품질의 데이터를
많이 확보하는 것은 보통 불가능하거나 그 비용이 매우 큽니다.
2강에서는 Data Augmentation, Knowledge Distillation, Transfer learning, Learning without Forgetting,
Semi-supervised learning 및 Self-training 등 주어진 데이터셋의 분포를 실제 데이터 분포와
최대한 유사하게 만들거나,이미 학습된 정보를 이용해 새 데이터셋에 대해 보다 잘 학습하거나,
label이 없는 데이터셋까지 이용해 학습하는 등 주어진 데이터셋을 최대한 효율적으로 이용해
딥러닝 모델을 학습하는 방법을 소개합니다.1. Data Augmentation
1-1. Learning representation of dataset
- CNN은 컴퓨터가 이해할 수 있도록 이미지 데이터를 압축해놓았다. 하지만 데이터셋은 항상 bias 되어 있다. 즉 카메라로 찍은 데이터(train data)와 실제 데이터는 차이가 꽤 있다는 뜻
- 아래 이미지는 그 키워드 데이터들의 평균 이미지
- 패턴들이 두드러진다. 왜냐? 예쁘게 찍은 데이터이기 때문

- 아래 이미지는 그 키워드 데이터들의 평균 이미지
- The training dataset is sparse(드문) samples of real data
- The training dataset contains only fractional(단편적인) part of real data

- The training dataset and real data always have a gap
- Suppose a training dataset has only bright images
- During test time, if a dark image is fed as input, the trained model may be confused
- Problem : Datasets don`t fully represent real data distribution!

- Augmentation data to fill more space and to close the gap

- Examples of augmentations to make a dataset denser

정리
우리가 보통 가지고 있는 데이터셋은 촬영된 것이기 때문에 현실을 표현하기는 조금 어렵다.(biased 되어있음) 이것을 data augmentation을 통해서 해결해보자
1-2. Data augmentation
- Image data augmentation
- Applying various image transformations to the dataset
- Crop, Shear(깎다), Brightness, Perspective(시각), Rotate,...

- OpenCV and NumPy have various methods useful for data augmentation
이미 잘 만들어져 있다 - Goal : Make training dataset`s distribution similar with real data distribution
- Applying various image transformations to the dataset
1-3. Various data augmentation methods
- Brightness adjustment(수정) using Numpy - 일정 숫자를 더해주기만 하면 됨(Random Sampling 해서 더해줘도 됨), Scaling 해줘도 된다, ※유의- 255는 넘지 않게


- Rotating (flipping) image using OpenCV

- Crop - Learning with only part of images
- 중요한 파트에 대해서 더 강하게 학습시켜주는 기법
- NumPy에서 indexing 해주는 것으로 간단하게 구현 가능


- Affine transformation
- Rotation의 일종
- Preserves 'line', 'length ratio', and 'parallelism' in image, 변환 전후에도 선은 선으로 유지되고, 길이의 비율도 유지되고, 평행 관계도 유지가 되는 변환
- For example, transforming a rectangle into a parallelogram (See the shear transform example below)

- Affine transformation (shear) using Opencv
- 모든 점을 입력하기엔 번거로움으로 3개의 포인트만 옮겨줌 → 그러면 M이라는 변환 행렬이 나와서 변환시켜주면 된다.

1-4. Modern augmentation techniques
- CutMix - 'Cut' and 'Mix' training example to help model better localize objects
- Mixing both images and labels
- 의미 있는 수준의 성능 향상과 동시에 물체의 위치를 좀 더 정교하게 학습이 된다고 함

- Mixing both images and labels
- RandAugment
- Augmentation을 한 번만 해야 하는가, 여러 가지를 조합해보자, 그런데 너무 많잖아? 그럴 때 사용하는 것이 RandAugment
- Many augmentation methods exist. Hard to find best augmentations to apply
- Automatically finding the best sequence of augmentations to apply
- Random sample, apply, and evaluate augmentations

- Augmentation policy has two parameters
- Which augmentation to apply
- Magnitude(규모) of augmentation to apply (how much to augment)

- Parameters used in the above example
- Which augmentation to apply : 'ShearX' & 'AutoContrast'
- Magnitude of augmentation to apply : 9
💯 대부분의 경우에서 data augmentation을 할 때 성능이 향상된다. 여러 가지 기법들을 배웠으니 꼭 적용해보자.
2. Leveraging(레버리징) pre-trained information
- Pre-trained 된 모델을 어떻게 사용할 것인가
2-1. Transfer learning
- The high-quality dataset is expensive and hard to obtain
- Supervised learning requires a very large-scale dataset for training
- Annotating data is very expensive, and its quality is not ensured
- Transfer learning : A practical training method with a small dataset!
- By transfer learning, we can easily adapt to a new task by leveraging pre-trained knowledge (feature)!
- 한 데이터셋에서 배운 지식을 다른 데이터셋에 사용하는 것, 이게 가능한가?
- Motivational observation : Similar datasets share common information 비슷한 데이터는 공통의 정보를 담고 있기 때문에 가능하다
- 아래는 비슷한 이미지의 다른 데이터셋인데, 한 데이터셋에서의 지식이 다른 데이터셋에서도 비슷한 형태를 보이는 것이 많다.

- Transfer learning에도 여러 가지 방법이 존재한다
- Approach 1 : Transfer knowledge from a pre-trained task to a new task
- Given a model pre-trained on a 10-class dataset,
- Chop off(잘라내다) the final layer of the pre-trained model, add and only re-train a new FC layer
- Extracted features preserve all the knowledge from pre-training

- Approach 2 : Fine-tuning the whole model
- Given a model pre-trained on a dataset
- Replace the final layer of the pre-trained model to a new one, and re-train the whole model
- Set learning rate differently
- 전체를 학습시키기에 더 많은 데이터가 필요하지만 성능은 훨씬 좋음

2-2. Knowledge distillation
- Pre-trained 모델이 가지고 있는 지식을 사용하는 진보된 방법
- Passing what model learned to 'another' smaller model (Teacher-Student learning)
- 이미 학습된 Teacher 네트워크의 지식을 주로 더 작은 모델인 Student 네트워크에 주입해서 학습하는 데 사용 : 큰 모델에서 작은 모델로 지식을 전달함으로써 모델 압축에 유용하게 사용하는 방법
- 'Distillate' knowledge of a trained model into another smaller model
- Used for model compression (Mimicking what a larger model knows)
- Also, used for pseudo-labeling (Generating pseudo-labels for an unlabeled dataset)
- 선생 모델의 출력 값을 가지고 라벨링 되지 않은 데이터를 수도 라벨링함으로써 데이터셋을 증가시킬 수 있다.

- Teacher-student network structure
- The student network learns what the teacher network knows
- The student network mimics outpus of the teacher network
- Unsupervised learning, since training can be done only with unlabeled data
- 같은 input에 대해서 Teacher Model과 Student Model의 아웃풋을 비교하고 그것의 loss로 Student Model을 backpropagation을 하며 학습시켜줌 → KL div.Loss는 두 개의 결괏값이 비슷해지도록 하는데, 결국은 Student Model이 Teacher Model을 따라 하게 되는 학습법 (label을 전혀 사용하지 않았기에 unsupervised learning이라고도 할 수 있음)

- When labeled data is available, can leverage labeled data for training (Student Loss)
- Distillation loss to 'predict similar outputs with the teacher model
- Distillation loss : 티쳐 모델을 따라하게 하는 loss (전체적인 경향성)
- Student loss : 정답 레이블과의 차이를 나타내는 loss
- Soft Prediction을 사용함 → argmax를 취하지 않은 실수 값들
- 최종적으로 Distillation Loss와 Student Loss의 Weighted sum으로 학습을 진행함

- Hard label (One-hot vector)
- Typically obtained from the dataset
- Indicates whether a class is 'true answer' or not
- Soft label
- Typically output of the model (=inference result)
- Regard it as 'knowledge'. Useful to observe how the model thinks

- Softmax with temperature(T)
- controls difference in output between small & large input values
- 그냥 Softmax를 취해줄 경우 입력값이 너무 큼에 따라서 결괏값이 극단적으로 다를 수 있는데 이것을 T로 나누어줌으로써 비슷한 경향성을 보이도록 설정함으로써 정보를 더 얻고자 한다.
- A large T smoothens large input value differences
- Useful to synchronize the student and teacher model`s outputs

- Distillation Loss
- KLdiv(Soft label, Soft prediction)
- Loss = difference between the teacher and student network`s inference
- 두 값의 차이의 거리를 본다
- Learn what teacher network knows by mimicking(모방)
- Student Loss
- CrossEntropy(Hard label, Soft prediction)
- Loss = difference between the student network`s inference and true label
- Learn the "right answer"

3. Leveraging unlabeled dataset for training
3-1. Semi-supervised learning
- unlabeled data를 목적성 있게 잘 사용하는 것
- 왜 unlabeled 데이터인가? supervised learning은 label이 필요하기 때문에 대규모의 데이터셋을 구축하기가 힘듦
- 근데 레이블이 필요 없다면? 온라인의 무궁무진한 데이터를 사용할 수 있음
- 이 기법은 unlabel 된 많은 데이터와 label 된 소수의 데이터로 학습하는 방법
- Typically, only a small portion of data is labeled
- Is there any way to learn from unlabeled data?
- Semi-supervised learning : Unsupervised (No label) + Fully Supervised (fully labeled)
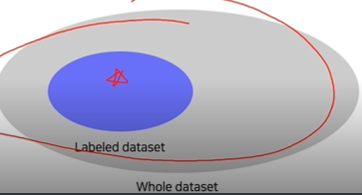
- Semi-supervised learning with pseudo labeling
- Pseudo-labeling unlabeled data using a pre-trained model, then use for training
- 레이블 데이터로 모델을 프리트레인하고, 언레이블 데이터의 수도 레이블을 이 모델로 생성함 → 이 두 데이터셋으로 새로운 모델을 재학습 시키는 것

3-2. Self-training
우리가 이제껏 배운 것들을 잘 연결하면 이미지에서 새로운 지평을 열 수 있다.
그것이 Self-training → 기존에 비해서 성능 자체가 압도적이었음, 이것의 도입으로 그동안 넘지 못했던 마의 장벽을 넘어섰다.
- Augmentation + Teacher-Student networks + semi-supervised learning
- SOTA ImageNet classification, 2019
- Self-training with noisy student
- 먼지 이미지넷 데이터셋을 이용해서 Teacher Model을 학습시킴
- Teacher Model로 언레이블 된 데이터셋에 수도 레이블을 생성해줌
- 이 두 데이터셋을 합쳐서 Student Model을 학습시킴
(+ RandAugment, 더 방대해진 데이터셋) - Student Model이 학습이 끝나면 이전 Teacher Model을 날리고, 그 Student Model를 Teacher Model로 변경해줌
- 특이한 점은 원래 Student Model을 Teacher Model보다 작은걸 사용해주는 데, 여기서는 조금씩 키워준다.
- 다시 이 2, 3, 4번 과정을 거친다.

- Iteratively training nosiy student network using teacher network

🌱피어세션
- 임문경 캠퍼님 발표🙋♂️
Q1. Teacher가 학습한 분포가 카테고리 분포라면 KL div Loss로 cross entropy를 사용해도 되는 것인가?
- 문의 결과 그렇다고 함
Q3. Self-training에서는 왜 Student Model이 Teacher Model보다 큰 것인가?
- Knowledge distillaion에서는 teacher보다 작은 student model을 사용함으로써 데이터에 fitting 하고 self-training에서는 반복해서 키움으로써 일반적인 데이터에 맞추고자 한다.
Q4. 정규분포를 따르는 224x1 행렬과 224x224 행렬을 곱하면 왜 분포가 (0, 224) 띄는
- 정규분포의 가법성이 아닐까?
10.(R) 통계 - 정규분포의 특징 (가법성)
지금까지 정규분포에 대해 알아봤습니다. 지금 설명드릴 글은 정규분포의 중요한 특징 중 가법성에 대해 설...
blog.naver.com
[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
data-hun.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week6_Day28. 팀원 찾기 (0) | 2021.09.21 |
|---|---|
| [BoostCamp] Week6_Day27. Image Classification (0) | 2021.09.19 |
| [BoostCamp] Week6_Day25. 새로운 U-Stage, 도메인 심화과정 (0) | 2021.09.07 |
| [Boostcamp] Image Classification Competition (0) | 2021.09.05 |
| [BoostCamp] Week5_Day23&24. 대회를 마무리하며 (0) | 2021.09.05 |
'Coding/BoostCamp' Related Articles
more



