
호기심 많은 분석가
[BoostCamp] Week6_Day25. 새로운 U-Stage, 도메인 심화과정 본문
부스트캠프
개발자의 지속 가능한 성장을 위한 학습 커뮤니티
boostcamp.connect.or.kr
CV과 NLP 중 한 도메인을 정해서 2주간 심화된 내용을 배우고, 그 후 남은 기간 동안 대회를 쭉 진행한다. 나는 여기서만큼 CV를 잘 배울 수 있는 곳이 없다고 생각해서 CV를 골랐고, 오늘 수업을 들었다. 예전 DL Basic 내용의 복습 느낌이었는데 많이 잊어버린 것들을 다시 리마인드 할 수 있어서 좋았다.
새로운 조원들과 함께하게 되어 아침에는 서로를 소개하고, 피어세션 룰을 정하는 시간을 가졌고, 이번에도 저번과 비슷한 방향으로 진행될 듯하다.
📙개인학습
(01강) Image Classification 1
CV란 영상으로부터 장면의 본질을 파악하는 것이다.
- 영상으로부터 장면의 본질을 파악한다.
1. Course overview
1-1. Why is visual perception(자각) important?
- Aritificial Intelligence (AI)?
- 왜 CV가 AI에 속하는가?
The theory and development of computer systems able to perform tasks normally
requiring human intelligence, such as visual perception, speech recognition,
decision-making, and translation between languages.
AI는 사람의 지능을 컴퓨터 시스템으로 구현하는 것인데, 지능은 사고하고 인과관계를 분석하는 것 외에도 시각이나 소리에 관련된 지각 능력 등을 포함한다. (인지능력, 지각 능력, 기억과 이해 및 사고능력)
- 이것을 어떻게 구현할까? 너무 어려울 땐 Reference를 보자 → 그것은 바로 사람!
- 사람이 태어나서 세상에 대해 배우는 방식을 관찰하면 인공지능을 구현할 수 있는 힌트를 얻을 것이다.
- Humans learn about the world through multi-modal perception

- Perception to system?
- 지각능력이 되게 중요하다. 이것이 하는 역할은 무엇인가?
- It`s (input, output) data
- As humans grow, we learn about the world by interacting with it
- We gather informative signals from multi-model association
- 사람은 오감뿐만 아니라 교차 감각과 다중감각도 이용해서 정보를 받아들임
- Developing machine perception is still an open research area
- 그래서 여전히 이 지각 능력을 향상하는 분야는 연구가 활발히 진행 중이다.

- 그중 시각을 통한 지각 능력이 굉장히 중요함
- 그래서 CV를 배우는 것

1-2. What is computer vision?
- 일상의 어떤 물체를 관찰(Visual World) → 수정체 뒤쪽에 상이 맺힘(Sensing device) → 뇌에 자극을 전달하고 이해하려 함(Interpreting device) → 해석(Interpretation)

- 이와 똑같은 과정을 컴퓨터에서 실행해주는 것이 CV
- 컴퓨터와 사람이 둘 다 이해하기 쉽도록 Representation(자료구조)
- 이것을 재구성을 했다 → Computer Graphics(Rendering 테크닉이라 함)

- Visual perception & intelligence
- Input : visual data (image or video)
- Class of visual perception
- Color perception
- Motion perception
- 3D perception
- Semantic-lebel perception
- Social perception (emotion perception)
- Visuomotor perception
- Also, computer vision includes understanding human visual perception capability 왜냐면 사람의 시각능력도 불완정하기 때문
- CV는 인간의 시각능력에 대한 이해도 포함한다.
- Our visual perception is imperfect
- Ex) 거꾸로 있는 사람이 이상하지 않을 수 있지만 실제로는 눈과 입이 반대로 된 굉장히 이상한 모습이다.

- To develop machine visual perception,
- We need to understand the good and bad of our visual perception
- We need to come up with how to compensate(보상하다) for the imperfection
- How to implement(시행, 구현하다)?
- 불과 몇 년 전만 해도 아래와 같은 고전적인 ML 기술을 많이 활용

- 딥러닝이 등장하면서 전문가에게 Feature extraction을 맡길 필요 없이 입력과 아웃풋만 넣어주면 해결되는 패러다임이 등장함
- 그렇게 잘 작동하지 않던 패턴인식과 컴퓨터 비전 알고리즘들이 작동하고 서비스 레벨까지 성장했음

1-3 What you will learn in this course
- Fundamental image tasks

- Data augmentation and knowledge distillation
- 단기간에 배우고 써먹을 수 있는 테크닉

- Multi-modal learning (vision + {text, sound, 3D, etc.})
- 시각과 다른 감각도 추가하여서 같이 작업하는 것도 배울 것

- Conditional generative model
- Neural network analysis by visualization
2. Image Classification
2-1. What is classification
Classifier
- A mapping f(.) that maps an image to a category level
- Classifier란 이미지를 category로 바꿔주는 함수다.

2-2 An ideal(이상적인) approach for image recognition
- What if we could memorize all the data in the world?
우리가 세상의 모든 정보를 다 기억하고 있다면?- Al the classification problems could be solved by k Nearest Neighbors (k-NN)!
- 쉽다. 비슷한 아이들만 찾아주면 됨, search 문제
- 하지만 그렇게 간단하지 않다. 정말 모든 데이터가 있다면 검색 속도가 기하급수적으로 늘어날 것이고 메모리 용량도 많이 필요하게 될 것 → 실현 불가능

- k Nearest Neighbors (k-NN)
- Classifies a query data(질의 데이터/새로운 데이터) point according to reference points closet to the query
- 새로운 데이터가 들어오면 그 근처의 k개의 데이터의 라벨 정보를 이용해서 분류하는 분류기

2-3 Convolutional Neural Networks (CNN)
CNN은 이 방대한 데이터를 제한된 복잡도의 시스템에 압축해서 녹여놓는 것이라고 볼 수 있음

- Let`s look at a simple model, perceptron, that takes every pixel of an image as input
- 모든 픽셀들을 서로 다른 가중치로 weighted sum을 하고 activation function을 취해줌으로써 분류

- Training 때는 전체를 학습시키다가 test 때는 Crop 해서 사용하면 전체적인 특징이 사라지므로 다른 것으로 예측할 수도 있음 → 그래서 fully connected layer가 아닌 locally connected layer를 가진 CNN이 등장함
- FC layer : 하나의 특징을 뽑기 위해서 모든 특징을 고려함
- LC layer : 영상의 공간적인 특성을 고려해서 국소적인 영역들만 connection을 고려
- 필요한 parameter수가 획기적으로 줆
- Sliding window처럼 전 영역을 순회하며 feature를 뽑으면 파라미터를 재활용하기에 더 적은 파라미터로도 효과적인 추출이 가능하고 오버 피팅도 방지해줌
→ 사진이 조금 바뀌더라도 특징은 잘 잡아내고 그렇기에 CNN이 영상에 적합

- 이러한 특징으로 인해 CNN은 다양한 CV Task의 backbone으로 활용된다.
- 윗 사진처럼 일부만 뽑진 않고, 작은 부분을 sliding 시켜서 모든 영역을 추출함

3. CNN architectures for image classification 1
3-1. Brief History

3-2. AlexNet
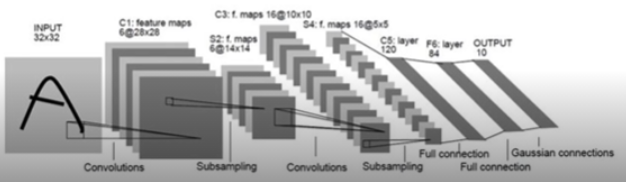
LeNet-5
- A very simple CNN architecture introduced by Yann LeCun in 1998
- Overall architecture : Conv - Pool - Conv - Pool - FC - FC
- Convolution : 5x5 filters with stride 1
- Pooling : 2x2 max pooling with stride 2
- 되게 간단한 구조였지만 한 글자씩 맞추는 데 좋은 성능을 보여 우편번호 인식에서 혁신을 불러일으킴 → AlexNet에 영감을 줌
- Similar with LeNet-5, but
- Bigger (7 hidden layers, 605k neurons, 60 million parameters)
- Trained with ImageNet (large amount of data, 1.2 millions)
- Using better activation function (ReLU) and regularization technuque (dropout)
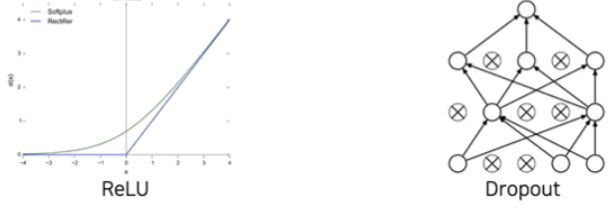
- 딥하게 층을 쌓으면서 파라미터 수를 늘렸고, 그 때문에 GPU 성능이 모자라 두 개의 GPU로 나눠서 진행함 → 중간중간 교차해줌으로써 서로 교환이 이루어지게 함

- MaxPool 된 데이터는 tensor형태(공간, 채널)이므로 Linear 연산을 해주기 위해서는 vector 형태로 만들어줘야 함 → flatten이나 AdaptiveAvgPool2d 등을 써줌
- Dense에서 4096인 것은 2개의 path로 되어있는 2048을 합친 것 (유의)

- Receptive field in CNN
- The region in the input space that a particular CNN feature is looking at
- 한 element가 출력이 됐을 때 얘를 나오게 만들어준(영향을 준) 입력 pixel을 의미
- Suppose KxK conv, filters with stride 1, and a pooling layer of size PxP,
- the a value of each unit in the pooling layer depends on an input patch of size : (P+K-1)x(P+K-1)

- The region in the input space that a particular CNN feature is looking at
3-2. AlexNet (deprecated components)
- LRN이라는 Local Response Normalization은 지금은 없어졌다. 명암을 normalization을 한다. → Batch Normalization을 사용함
- 11x11 convolution filter
- The filter size is increased, as the input size of the image has incresed
- LeNet: 28x28
- AlexNet: 227x227
- Larger size filters are used to cover a wider range of the input image
- 큰 사이즈의 convolutional filter를 사용했었는데 현재는 사용하지 않음
- The filter size is increased, as the input size of the image has incresed
3-3. VGGNet
- Deeper architecture
- 16 and 19 layers
- Simple architecture
- No local response normalization
- Only 3x3 conv filters blocks, 2x2 max pooling
- Better performance
- Significant performance improvement over AlexNet (2nd in ILSVRC14)
- Better generalization
- Final features generalizing well to other tasks even without fine-tuning

- Input
- AlexNet을 최대한 유지하려 했다
- 224x224 RGB images (same with AlexNet)
- Subtracting mean RGB values of training images
- Key design choices
- 3x3 convolution filters with stride 1
- 2x2 max pooling perations
→ Using many 3x3 conv layers instead of a small number of larger conv filters
- Keeping receptive field size large enough 여러 개 쌓으면 큰 receptive field와 크기가 동일하다
- Deeper with more non-liearities 깊게 쌓음으로써 활성 함수를 더 적용할 수 있음
- Fewer parameters 파라미터 수를 줄일 수 있다
- 3 fully-connected (FC) layers
- Other details
- ReLU for non-linearity
- No local response normalization
과제. VGG11 구현

- conv3-64의 의미 - 해당 층에서 3x3 필터 64개로 연산이 이루어진다.
- 아래와 같이 연산을 적어주면 된다. input_channel은 3, output_channel은 64, kernel_size가 3이고 padding은 1이기에 크기는 유지됨 -> 특징 추출, 각 채널은 서로 다른 특징들을 적절히 추출하도록 학습되므로 채널이 증가하면서 표현력이 높아짐
-
nn.Conv2d(3, 64, kernel_size=3, padding=1)
-
위와 같이 구성하면 크기가 224x224에서 112x112로 줄어듦을 확인할 수 있음, 이미지 데이터의 특징은 인접 픽셀들 간의 유사도가 매우 높다는 것인데, 그렇기에 우린 그 모든 데이터가 필요하지는 않음. Max-pooling으로 가장 큰 값을 얻음으로써 충분히 그 영역을 표현할 수 있고, 국소 영역 내부에서는 픽셀들이 이동 및 회전 등에 의해 위치가 바뀌더라도 출력 값이 동일하기 때문에 그러한 변화들에 영향을 덜 받는다.nn.MaxPool2d(kernel_size=2, strid=2) - 또한 CNN이 처리해야 하는 이미지의 크기가 크게 줄기 때문에 parameter가 줄어들어서 학습 시간을 절약할 수 있으며 오버 피팅 문제 또한 해결할 수 있다.
- Convolutional layer를 거친 뒤 linear classifier에서는 matrix 연산을 하기 위해 flatten을 취해줌으로 아래와 같이 이미지 크기와 channel을 input_feature로 넣어줘야 함
-
nn.Linear(in_features=7*7*512, out_features=4096)
-
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")를 model, image, label에 씌워줘서 GPU 사용
- freeze를 할 때 convolutional layer만 freeze 하고 Linear classifier만을 학습하기 위해서는 아래와 같이 시행해줘야 한다. idx 부분이 없으면 classifier까지 얼어버림
-
# Freeze the feature extracting convolution layers idx = 0 for param in model_finetune.children(): if idx == 0: param.requires_grad = False else : param.requires_grad = True idx += 1
🌱피어세션
발표 진행 ⇒ 송나은 님.
Multi-modal perception : 인간은 여러 가지의 인식 방법(시각, 청각, 후각, 촉각 등..)으로 세계를 인식
Q1. CNN에서 locally connected 한 것이 무슨 의미인가요?
- CNN에서는 fully connected layer와 다르게 kernel-size만큼의 window size만큼의 값만을 참조해 다음 layer에 전달하게 되므로, input에서 kernel size만큼의 값만을
locally 하게참조하는 것이라고 할 수 있다! - → random 하게 참조하는 것이 아닌 stride만큼 이동하면서 전체 이미지를 locally 하게 참조하는 것!!
Q2. [VGGNet 논문에서 질문] ❓Rescale을 다르게 하면 왜 성능이 향상되는가??

- 답변은 추후에 고민 후 이야기 나누도록
Image Classification 대회 진행했을 때 사용한 방법 공유.
(1) k-fold 방법
(2) psuedo labeling
(3) ensemble
제안. 논문 review를 하나씩 하면 어떨까요?

⇒ 희망하는 사람이 개인적으로 읽고 피어세션 남은 시간에 발표하기로 함. 발표를 하는 사람도 지식을 나누면서 배우는 것이 있을 것이다. 또한, 이전에 같은 방식으로 진행했었는데 생각보다 참여도가 높았다.
🔥 부캠에서 살아남기
1기 분들이 오셔서 강연을 해주셨는데, 다들 왜 초청되신 지 알 수 있을 만큼 대단하신 분들이셨다. 부스트 캠프에 임하는 자세, 대회에 참여할 때, 취업 준비를 할 때 등등에 대한 조언들 해주셨는데, 다들 언급해주신 부분들은
공유를 많이 하고, 스터디 등으로 함께 작업하며 여기서 좋은 인연을 많이 만들어라, 대회 순위는 중요하지 않다. 무엇을 배웠는지, 왜 이것을 시도했는지에 대한 정리를 잘해둬라 등등 협업과 기록에 대한 이야기들을 많이 해주셨다.
특히 마지막 고지형 멘토님의 자기소개서, 이력서, 포트폴리오는 이 사람을 안 뽑을 수 있나? 싶을 정도로 놀라운 것들의 연속이었다. 참고해서 나도 누군가에게 이런 도움을 주고, 이런 평가를 받을 수 있는 사람이 되어야겠다.
그래서 선배님들의 말씀을 본받아 누군가에겐 도움이 되길 바라며 취업 준비에 대한 소소한 Tip을 공유했고, 한 캠퍼분에게 도움이 많이 되었다는 DM을 받기도 했다. 공유를 습관화하는 사람이 되자🌟

[AI Tech]Daily Report
Naver AI Tech BoostCamp 2기 캠퍼 허정훈 2021.08.03 - 2021.12.27 https://bit.ly/3zvJnSh
data-hun.notion.site
'Coding > BoostCamp' 카테고리의 다른 글
| [BoostCamp] Week6_Day27. Image Classification (0) | 2021.09.19 |
|---|---|
| [BoostCamp] Week6_Day26. 양날의 검, Pseudo-labeling (2) | 2021.09.14 |
| [Boostcamp] Image Classification Competition (0) | 2021.09.05 |
| [BoostCamp] Week5_Day23&24. 대회를 마무리하며 (0) | 2021.09.05 |
| [BoostCamp] Week5_Day22. 끝을 향해 달려가는 (0) | 2021.09.03 |



